字节序与比特序详解
- 字节序的定义
- 几种类型的字节序
- cpu字节序
- 外部bus字节序
- 设备字节序
- 网络协议字节序
- Ethernet协议字节序
- IP协议字节序
- 编译字节序
- 几种类型的字节序
- 比特序的定义
- 字节序与bit序的转换
- 结构体的位域
字节序的定义
字节序就是说一个对象的多个字节在内存中如何排序存放,比如我们要想往一个地址a中写入一个整形数据0x12345678,那么最后在内存中是如何存放这四个字节的呢?
0x12这个字节值为最高有效字节,也就是整数值的最高位(在本文中0x12=0x12000000),0x78为最低有效字节。
这里就分为大端字节序和小端字节序
大端字节序:便是指最高有效字节落在低地址上的字节存放方式
小端字节序:便是指最高有效字节落在高地址上的字节存放方式。
a a+1 a+2 a+3
0x12 0x34 0x56 0x78 大端字节序
0x78 0x56 0x34 0x12 小端字节序
几种类型的字节序
参考如下图的计算机系统:

CPU, local bus and internal memory/cache 都可以归纳为CPU,因为他们通常都有同样的字节序。
cpu字节序
小端字节序CPU包括Intel和DEC,大端字节序CPU包括Motorola 680x0,Sun Sparc以及IBM(例如Powerpc)。MIPS和ARM可以配置两种字节序中的任一种。
外部bus字节序
bus的字节序由bus协议定义,假如bus的字节序和CPU字节序不同,bus控制器或者桥会执行转换工作。
设备字节序
Kevin’s Theory #1: When a multi-byte data unit travels across the boundary of two reverse endian systems, the conversion is made such that memory contiguousness to the unit is preserved.
网络协议字节序
网络协议的字节序定义了网络协议头中整形域部分的字节和比特是如何发送和接收的。我们引入一个术语:线上地址(wire address).低位线上地址的比特或者字节在高位之间传输。
网卡通常遵循它们支持的网络协议的字节序。大多数网络协议是大端字节序。我们以Ethernet协议和IP协议为例说明。
Ethernet协议字节序
以太网(Ethernet)协议是大端字节序。这意味着一个整型值的高字节被放置在低线上地址上,同时在低字节之前被传输或者接收。例如arp协议字0x0806,在以太网头中的布局如下:
wire byte offset: 0 1
hex : 08 06
同时注意到以太网头中的mac地址被认为是字符串,因此不用关心字节序的问题。I例如mac地址12:34:56:78:9a:bc在线上有如下布局,字节12被首先传输。

以太网的数据结构如下:
struct ethhdr
{
unsigned char h_dest[ETH_ALEN];
unsigned char h_source[ETH_ALEN];
unsigned short h_proto;
};h_dest 和h_source 是字符串,因此不必考虑字节序的问题。h_proto是整型值,因此在主机访问该字段是需要使用ntohs,在主机填充该字段时要htons。
至于比特序的传输顺序下文有介绍。
IP协议字节序
IP协议字节序是大端。bit序继承自CPU的,网卡负责线上转换bit序列。
以下为ip header的结构体:
struct iphdr {
#if defined(__LITTLE_ENDIAN_BITFIELD)
__u8 ihl:4,
version:4;
#elif defined (__BIG_ENDIAN_BITFIELD)
__u8 version:4,
ihl:4;
#else
#error "Please fix "
#endif
__u8 tos;
__u16 tot_len;
__u16 id;
__u16 frag_off;
__u8 ttl;
__u8 protocol;
__u16 check;
__u32 saddr;
__u32 daddr;
/*The options start here. */
};version 和 ihl 字段:
根据ip协议,version是ip头首字节的高有效4bit ,ihl是低有效bit.
有两种方法访问这两个字段:
1.直接解析法
假如ver_ihl代表ip头的首字节则ipl=ver_ihl&0xf,version=ver_ihl>>4,不论主机是那种字节序。
2.结构体位域法
定义如上的结构体,假如主机是小端,我们定义ihl在version之前,如果是大端正好相反。应用Kevin’s Theory #2 如果位域A定义在位域B之前,那么位域A总是出现在低序的比特位。正好可以满足我们的访问要求。
编译字节序
CPU的字节序影响CPU的指令集。不同的GNC C工具链为了编译C代码应该使用相应CPU的大小端。例如mips-linux-gcc和mipsel-linux-gcc是被用来分别编译大端的和小端的MIPs代码。
比特序的定义
比特序就是一个字节中的bit顺序问题。一般情况下系统的比特序和字节序是保持一致的。 对应分为以下情况:
LSB 0 位序:字节的第0位存放数据的least significant bit,即我们的数据的最低位存放在字节的第0位。(对应小端字节序)
MSB 0 位序:节的第0位存放数据的most significant bit,即我们的数据的最高位存放在字节的第0位。(对应大端字节序)
LSB是指 least significant bit,MSB是指 most significant bit。
比特序1 0 0 1 0 0 1 0在大端系统中最高有效比特位为1、最低有效比特位为0,字节的值为0x92。在小端系统中最高、最低有效比特位则相反为0、1,字节的值为0x49。
跟字节序类似,要想保持一个字节值不变那么就要使系统能正确的识别最高、最低有效比特位。
字节序与bit序的转换
字节序转换函数ntohl(s)、htonl(s) 。
例如在socket编程中经常要用到网络字节序转换函数ntohl、htonl来进行主机序和网络序(大端序)的转换,在主机序为小端的系统中字节序列78 56 34 12(val=0x12345678)经过htonl转换后字节序列变成12 34 56 78
字节序转换后我在想是不是比特序也一同进行了转换?
为什么会有这个疑问呢,因为前文可知系统的比特序和字节序是一致的,现在字节序已经从小端变成了大端那么比特序应该也要一起转换。而且如果比特序不变化那么当这些字节到了目标大端序系统中后每一个字节的值都会发生变化,因为同样的比特序列在小端和大端系统中识别的字节值会不一样。
首先从htonl、ntohl的源码来看确实只进行了字节序的转换并没有进行比特序的转换,再有就是以前socket编程的时候只调用了ntohl、htonl等函数并没有调用(而且系统也没有提供)比特序转换函数,但是最后的结果都是正确的,并没有发现上面提到的字节值发生变化的问题。
这是因为系统帮我们自动做了转换。下面进行详细分析。
比特的发送、接收顺序是指一个字节中的bit在网络电缆中是如何发送、接收的。在以太网(Ethernet)中,是从最低有效比特位到最高有效比特位的发送顺序,也就是最低有效比特位首先发送。
在以太网中这个规定有点奇怪,因为字节序我们是按照大端序来发送,但是比特序却是按照小端序的方式来发送。如下图所示:
主机是大端系统:
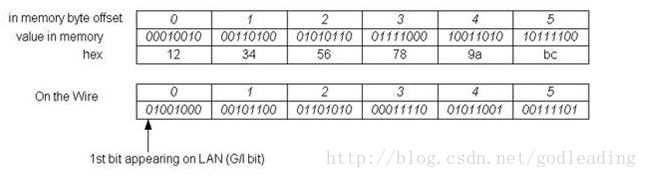
比特的发送、接收顺序对CPU、软件都是不可见的,(对诸如PHY的serdes(串行器和解串器)以及网卡写总线的硬件设计是非常重要的)因为我们的网卡会给我们处理这种转换,在发送的时候按照小端序发送比特位,在接收的时候网卡会把接收到的比特序转换成主机的比特序,
The bit transmission/reception order generally is invisible to the CPU and software, 下面是一个小端机器发送一个int整型给一个大端机器的示意图:

结构体的位域
对于位域有一个约定:在C语言的结构体中如果包含了位域,如果位域A定义在位域B之前,那么位域A总是出现在低序的比特位。
参考如下代码:
#include小端机器A上的结果
bit_order->a : 1
bit_order->b : 6
bit_order->c : 3 对应字节上的bit序如下图:

大端机器上的结果
bit_order->a : 1
bit_order->b : 7
bit_order->c : 1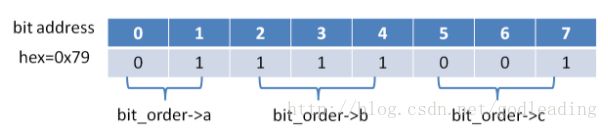
从上面的输出可以看到同样的代码在不同的机器中输出了不同的结果,也就是说我们的代码在不同的平台不能直接移植,导致这个问题的原因就是我们前面提到的关于位域的一个约定,定义在前面的位域总是出现在低地址的bit位中,因为不同的平台的比特序是不同的,但是我们定义的位域没有根据平台的大小端进行转换,最后就导致了问题。那么如何解决这个问题,那就是在定义结构体中的位域时判断平台的大小端:
#include"
#endif
};
int main(int argc, char *argv[])
{
unsigned char ch = 0x79;
struct bit_order *ptr = (struct bit_order *)&ch;
printf("bit_order->a : %u\n", ptr->a);
printf("bit_order->b : %u\n", ptr->b);
printf("bit_order->c : %u\n", ptr->c);
return 0;
}