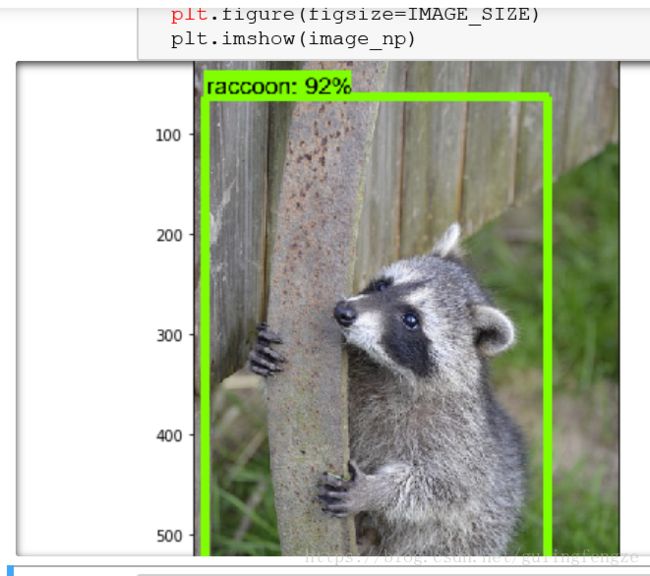
目标检测之数据集训练和模型调用
1.准备训练数据
之前的文章中VOC2007格式数据集制作已经说明了VOC2007数据集的制作方法,而Tensorflow Object Detection API使用是TFRecord文件数据格式,所以我们还需要将其转为TFRecord格式。
我们首先来创建一个dataset文件夹和trainModels文件夹,为了不影响原API源码的目录结构,我们假设在C:\Development\下创建这两个文件夹,将自己的VOC2007格式数据集放到dataset文件夹下,trainModels文件夹暂时先不管它。将object_detection/data/pascal_label_map.pbtxt文件复制一份也放到dataset文件夹下,并将此文件的内容改为自己数据集所对应的标签。
进入到object_detection\dataset_tools 路径下,有个名为create_pascal_tf_record.py的脚本文件,该脚本文件可以帮助我们将VOC2007格式数据集转成所需要的TFRecord格式文件。但使用之前需要修改两个地方(修改前最好备份一份):
- (49~50行这里)
flags.DEFINE_string(‘label_map_path’, ‘data/pascal_label_map.pbtxt’,
‘Path to label map proto’)
将'data/pascal_label_map.pbtxt' 改为上面我们复制的pascal_label_map.pbtxt文件所在路径,也就是修改为这样:
flags.DEFINE_string('label_map_path', 'C:\Development\dataset\pascal_label_map.pbtxt',
'Path to label map proto')- (163~164行这里)
examples_path = os.path.join(data_dir, year, ‘ImageSets’, ‘Main’,
‘aeroplane_’ + FLAGS.set + ‘.txt’)
将'aeroplane_' + 去掉,也就是修改为这样:
examples_path = os.path.join(data_dir, year, 'ImageSets', 'Main',
FLAGS.set + '.txt')修改完成后,我们进入到object_detection\dataset_tools 路径下,打开cmd命令窗口,再来分别执行下面的命令(注意:不要用win10的Powershell!!!,可能有坑!):
python create_pascal_tf_record.py --data_dir=C:\Development\dataset\VOCdevkit --year=VOC2007 --set=train --output_path='pascal_train.record'
python create_pascal_tf_record.py --data_dir=C:\Development\dataset\VOCdevkit --year=VOC2007 --set=val --output_path='pascal_val.record'
执行完后,我们可以在object_detection\dataset_tools 路径下看到两个文件:pascal_train.record和pascal_val.record,将这两个文件放到dataset文件夹下。
2.模型下载和文件配置
得到了所需的TFRecord文件后,我们需要下载模型以及进行相关的文件配置。这里我们使用ssd_inception_v2_coco_2017_11_17模型,将该模型的压缩包复制一份到trainModels文件夹中并解压。如果想使用别的模型,到这里下载即可模型下载。
准备好模型后,接下来进行配置工作。将路径object_detection\samples\configs 下名为ssd_inception_v2_coco.config的文件复制一份到trainModels文件夹中,打开进行修改这6处:
num_classes: 90 --改为自己类数
fine_tune_checkpoint: "PATH_TO_BE_CONFIGURED/model.ckpt" --改为自己下载的模型的ckpt文件路径
train_input_reader: {
tf_record_input_reader {
input_path: "PATH_TO_BE_CONFIGURED/mscoco_train.record" --改为pascal_train.record所在路径
}
label_map_path: "PATH_TO_BE_CONFIGURED/mscoco_label_map.pbtxt" --改为pascal_label_map.pbtxt所在路径
}
eval_input_reader: {
tf_record_input_reader {
input_path: "PATH_TO_BE_CONFIGURED/mscoco_val.record" ----改为pascal_val.record所在路径
}
label_map_path: "PATH_TO_BE_CONFIGURED/mscoco_label_map.pbtxt" --改为pascal_label_map.pbtxt所在路径
shuffle: false
num_readers: 1
}3.训练和验证
进入object_detection路径下,执行下面命令进行训练:
python train.py --logtostderr --pipeline_config_path='C:\Development\trainModels\ssd_mobilenet_v1_coco.config' --train_dir='C:\Development\train'说明:C:\Development\train, 执行上面命令后,会在C:\Development 下创建一个名为train的文件夹,这个文件夹是用来存储训练结果的。
训练完成后接下来进行模型的验证,执行下面命令进行训练:
python eval.py --logtostderr --pipeline_config_path='C:\Development\trainModels\ssd_mobilenet_v1_coco.config' --checkpoint_dir='C:\Development\trainModels\train --eval_dir='C:\Development\eval' 说明:C:\Development\eval, 执行上面命令后,会在C:\Development 下创建一个名为eval的文件夹,这个文件夹是用来存储验证结果的。checkpoint_dir='C:\Development\trainModels\train 是使用刚才训练后得到的ckpt文件。
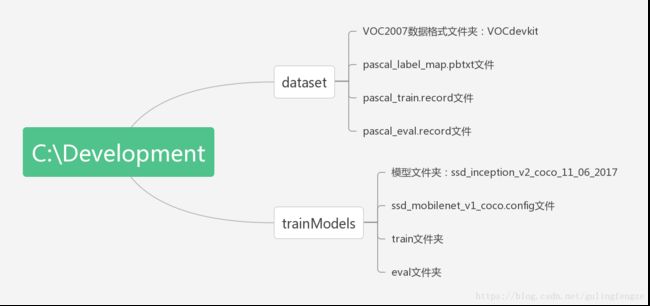
再来看下我们的文件结构吧:(图中的.config文件名写错了,应该是ssd_inception_v2_coco.config)
进入trainModels所在路径下,执行下面命令:
tensorboard --logdir=trainModels在浏览器中输入localhost:6060就能看到训练进程了。
4.pb文件生成和调用
在训练完自己的数据之后,在train文件夹下面可以看到有.meta、checkpoint、.ckpt、.index这四个文件。在实际进行预测时,仅需要模型和权重,所以我们需要进行‘冻结’操作,生成一个.pb 文件。说白点,可以把.pb 文件理解为模型和权重的结合体。可以看下上面我们解压的SSDMobilenet模型 (ssd_inception_v2_coco_11_06_2017)的目录:
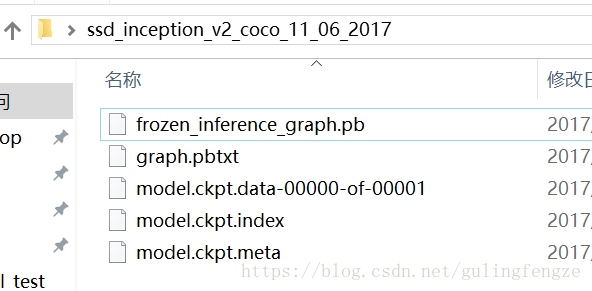
这里面就有一个frozen_inference_graph.pb文件,而
object_detection_tutorial.ipynb 中使用的也是.pb 文件。如何生成需要的.pb 文件呢?API给我们提供了实现脚本。在object_detection路径下有个export_inference_graph.py 文件,我们利用该文件执行下面命令即可:
python export_inference_graph.py --input_type image_tensor --pipeline_config_path=C:\Development\trainModels\ssd_mobilenet_v1_coco.config --trained_checkpoint_prefix=C:\Development\trainModels\train\model.ckpt-24 --output_directory=C:\Development\trainModels\train这时我们在trainModels\train 路径下就可以看到生成的frozen_inference_graph.pb 文件了。这里再说下model.ckpt-24 ,我这里的24是我训练时最后的一个检查点的编号(下图所示),大家应该根据自己训练时的检查点来定。

下面就可以调用生成的.pb 文件进行目标检测了,修改的地方有以下几个地方:
PATH_TO_CKPT =r'C:\Development\trainModels\train\frozen_inference_graph.pb'
PATH_TO_LABELS=r'C:\Development\dataset\pascal_label_map.pbtxt'
NUM_CLASSES = '改成自己的class num值'参照object_detection_tutorial.ipynb ,修改后的代码如下:
import numpy as np
import os
import six.moves.urllib as urllib
import sys
import tarfile
import tensorflow as tf
import zipfile
from collections import defaultdict
from io import StringIO
from matplotlib import pyplot as plt
from PIL import Image
# This is needed since the notebook is stored in the object_detection folder.
sys.path.append("..")
from object_detection.utils import ops as utils_ops
if tf.__version__ < '1.4.0':
raise ImportError('Please upgrade your tensorflow installation to v1.4.* or later!')
# This is needed to display the images.
%matplotlib inline
from utils import label_map_util
from utils import visualization_utils as vis_util
# What model to download.
#MODEL_NAME = 'C:\Development\trainModels\ssd_mobilenet_v1_coco_2017_11_17'
#MODEL_FILE = MODEL_NAME + '.tar.gz'
#DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'
# Path to frozen detection graph. This is the actual model that is used for the object detection.
#改为自己的.ckpt路径
PATH_TO_CKPT = r'C:\Development\trainModels\train\frozen_inference_graph.pb'
# List of the strings that is used to add correct label for each box.
#改为自己的.pbtxt路径
PATH_TO_LABELS = r'C:\Development\dataset\pascal_label_map.pbtxt'
#改为自己的class num
NUM_CLASSES = 90
#opener = urllib.request.URLopener()
#opener.retrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE)
#tar_file = tarfile.open(MODEL_FILE)
#for file in tar_file.getmembers():
# file_name = os.path.basename(file.name)
# if 'frozen_inference_graph.pb' in file_name:
# tar_file.extract(file, os.getcwd())
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES, use_display_name=True)
category_index = label_map_util.create_category_index(categories)
def load_image_into_numpy_array(image):
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape(
(im_height, im_width, 3)).astype(np.uint8)
# For the sake of simplicity we will use only 2 images:
# image1.jpg
# image2.jpg
# If you want to test the code with your images, just add path to the images to the TEST_IMAGE_PATHS.
PATH_TO_TEST_IMAGES_DIR = 'test_images'
TEST_IMAGE_PATHS = [ os.path.join(PATH_TO_TEST_IMAGES_DIR, 'image{}.jpg'.format(i)) for i in range(1, 4) ]
#PATH_TO_TEST_IMAGES_DIR = 'C:/Users/gulin/Desktop/animal'
#TEST_IMAGE_PATHS = [ os.path.join(PATH_TO_TEST_IMAGES_DIR, 'image{}.jpg'.format(i)) for i in range(1, 7) ]
# Size, in inches, of the output images.
IMAGE_SIZE = (12, 8)
def run_inference_for_single_image(image, graph):
with graph.as_default():
with tf.Session() as sess:
# Get handles to input and output tensors
ops = tf.get_default_graph().get_operations()
all_tensor_names = {output.name for op in ops for output in op.outputs}
tensor_dict = {}
for key in [
'num_detections', 'detection_boxes', 'detection_scores',
'detection_classes', 'detection_masks'
]:
tensor_name = key + ':0'
if tensor_name in all_tensor_names:
tensor_dict[key] = tf.get_default_graph().get_tensor_by_name(
tensor_name)
if 'detection_masks' in tensor_dict:
# The following processing is only for single image
detection_boxes = tf.squeeze(tensor_dict['detection_boxes'], [0])
detection_masks = tf.squeeze(tensor_dict['detection_masks'], [0])
# Reframe is required to translate mask from box coordinates to image coordinates and fit the image size.
real_num_detection = tf.cast(tensor_dict['num_detections'][0], tf.int32)
detection_boxes = tf.slice(detection_boxes, [0, 0], [real_num_detection, -1])
detection_masks = tf.slice(detection_masks, [0, 0, 0], [real_num_detection, -1, -1])
detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks(
detection_masks, detection_boxes, image.shape[0], image.shape[1])
detection_masks_reframed = tf.cast(
tf.greater(detection_masks_reframed, 0.5), tf.uint8)
# Follow the convention by adding back the batch dimension
tensor_dict['detection_masks'] = tf.expand_dims(
detection_masks_reframed, 0)
image_tensor = tf.get_default_graph().get_tensor_by_name('image_tensor:0')
# Run inference
output_dict = sess.run(tensor_dict,
feed_dict={image_tensor: np.expand_dims(image, 0)})
# all outputs are float32 numpy arrays, so convert types as appropriate
output_dict['num_detections'] = int(output_dict['num_detections'][0])
output_dict['detection_classes'] = output_dict[
'detection_classes'][0].astype(np.uint8)
output_dict['detection_boxes'] = output_dict['detection_boxes'][0]
output_dict['detection_scores'] = output_dict['detection_scores'][0]
if 'detection_masks' in output_dict:
output_dict['detection_masks'] = output_dict['detection_masks'][0]
return output_dict
for image_path in TEST_IMAGE_PATHS:
image = Image.open(image_path)
# the array based representation of the image will be used later in order to prepare the
# result image with boxes and labels on it.
image_np = load_image_into_numpy_array(image)
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
# Actual detection.
output_dict = run_inference_for_single_image(image_np, detection_graph)
# Visualization of the results of a detection.
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
output_dict['detection_boxes'],
output_dict['detection_classes'],
output_dict['detection_scores'],
category_index,
instance_masks=output_dict.get('detection_masks'),
use_normalized_coordinates=True,
line_thickness=8)
plt.figure(figsize=IMAGE_SIZE)
plt.imshow(image_np)