CV进阶—实战 | 手把手教你简单的人脸识别

最近人脸检测识别又火起来了,不知道大家知否两会期间都是人脸检测识别技术在后台监控,保证了我们两会期间的安全及监控工作,今天是我们CV进阶的第二节课,带领大家进入新的篇章,教你怎么用最近本的框架去实现人脸识别。

人脸检测及识别无处不在我们身边,只要你出门,就被摄像头一直监控着可以这么说。这也是为了我们社会安全!
在各个领域都已经用到了检测及识别技术最常见的是我们支付宝刷脸支付及门禁系统。

那今天我们“计算机视觉战队”就和大家说说识别。今天主要是针对刚刚入门的同学,如果你还很感兴趣,接下来和我们一起学习吧!本次学习后,你会对识别有一个深入了解,也会对该领域有浓厚的兴趣!
今天我们主要以实践为主!!!
在实践之前,我们首先要做的就是搭建环境,这个在CV系列已经有详细的教学了,本次我们基于Python的keras为大家带来简单教学。
数据准备
首先你选定文件的位置,该文件主要有train、test、Model和predict四个文件夹,之后会说每个文件夹的用途。

建立好四个文件夹之后,在train这个文件夹中存放你要存放的训练集,如下图:

今天举例子我只用两个类别的人脸数据,注:在train文件在建立两个你存入训练数据的文件夹并命名,在测试集也一样的操作,数据量根据你个人而定。
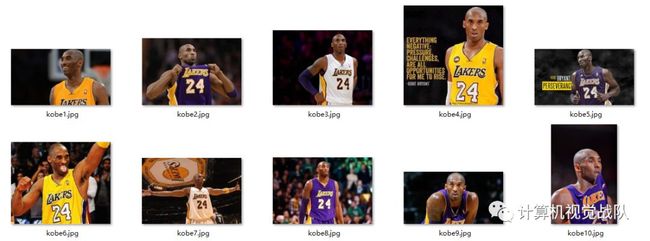
上图就是训练集内的部分数据,其他训练集文件及测试集都一样的操作,这个是建模的基础。
建模型
注:本次操作都是在Jupyter,方便简单。
导入相关库
from keras.models import Sequential
from keras.layers import Conv2D,MaxPool2D,Activation,Dropout,Flatten,Dense
from keras.optimizers import Adam
from keras.preprocessing.image import ImageDataGenerator,img_to_array,load_img
from keras.models import load_model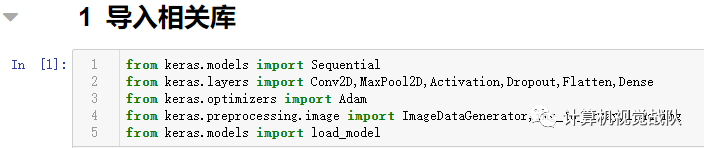
基础设置
该处的设置主要是文件夹的路径及简单参数,如下:
设置图像尺寸大小,该处是将输入的图片进行裁剪,输入则为设置的宽高大小的图片:
IMG_W = 224
IMG_H = 224该处主要定义类别数(本次我用了两类,所以CLASS = 2)、EPOCH是迭代周期、BATCH_SIZE是批次大小(也就是一次输入多少图像),学习率及dropout的比例这几个参数都比较好理解,平台之前也专门讲解过调参技巧,有兴趣的可以去历史推送查阅:
CLASS = 2
BATCH_SIZE = 64
EPOCHS = 5
LEARNING_RATE = 1e-4 #学习率
DROPOUT_RATE = 0
设置各个文件夹的路径:
TRAIN_PATH = 'train' #训练集存放路径
TEST_PATH = 'test' #测试集存放路径
SAVE_PATH = 'Model' #模型保存路径


预处理
train_datagen = ImageDataGenerator(
rotation_range = 40, # 随机旋转度数
width_shift_range = 0.2, # 随机水平平移
height_shift_range = 0.2,# 随机竖直平移
rescale = 1/255, # 数据归一化
shear_range = 20, # 随机错切变换
zoom_range = 0.2, # 随机放大
horizontal_flip = True, # 水平翻转
fill_mode = 'nearest', # 填充方式 )
test_datagen = ImageDataGenerator(
rescale = 1/255, # 数据归一化 )
model = Sequential() #创建一个神经网络对象
网络框架
开始设置本次模型的网络框架,首先创建一个卷积层,彩色图像,所以是3通道,并设置32个不同卷积核进行卷积以构建32个特征图:
model.add(Conv2D(input_shape(IMG_W,IMG_H,3),filters=32,kernel_size=3,padding='same',activation='relu'))
其中使用了ReLU激活函数,该激活函数本平台之前也有详细讲解。
接下来是创建另一个卷积层及池化层,具体如下:
model.add(Conv2D(filters=32,kernel_size=3,padding='same',activation='relu')) model.add(MaxPool2D(pool_size=2,strides=2)) model.add(Conv2D(filters=64,kernel_size=3,padding='same',activation='relu')) model.add(Conv2D(filters=64,kernel_size=3,padding='same',activation='relu')) model.add(MaxPool2D(pool_size=2,strides=2)) model.add(Conv2D(filters=128,kernel_size=3,padding='same',activation='relu')) model.add(Conv2D(filters=128,kernel_size=3,padding='same',activation='relu')) model.add(MaxPool2D(pool_size=2, strides=2))
从上面可以看出,构建了多个卷积层及池化层,其中filters数量大家要注意,那是增加了卷积核的数量,且池化过程的步长为2。
model.add(Flatten()) #数据扁平化 model.add(Dense(128,activation='relu')) model.add(Dense(64,activation='relu')) model.add(Dropout(DROPOUT_RATE)) model.add(Dense(CLASS,activation='softmax'))
adam = Adam(lr=LEARNING_RATE) #创建Adam优化器 model.compile(optimizer=adam,loss='categorical_crossentropy',metrics=['accuracy'])
以上主要设置了全连接层及优化方式,注意看的同学应该注意到了,加入了Dropout,如果数据较少,该项可以去除。
基本的工作已经完成,接下来就是训练及测试。
train_generator = train_datagen.flow_from_directory(
TRAIN_PATH,
target_size=(IMG_W,IMG_H),
batch_size=BATCH_SIZE)
test_generator = test_datagen.flow_from_directory(
TEST_PATH,
target_size=(IMG_W,IMG_H),
batch_size=BATCH_SIZE, )
print(train_generator.class_indices)
这主要设置训练&测试迭代器,最后输出结果。直接运行吧:

从中可以看出,模型已经把他们自己划分成两类(如上面的字典,科比为0,詹姆斯为0)。
再来看看运行过程的损失及精度,我最后设置了50次EPOCH。


那我们开始测试吧!
测试
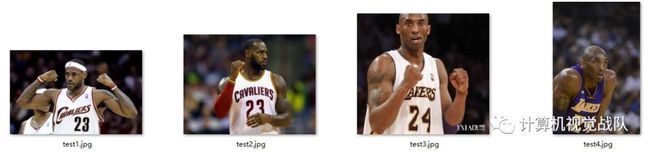
结果如下:

具体代码请自行下载,去尝试实践,感谢对本平台的支持与关注。如果觉得本次实践好,请点击好看并分享,谢谢!
链接:https://pan.baidu.com/s/1djGeUHOlE7J2M2B2h7IrAg
提取码:louf
如果想加入我们“计算机视觉战队”,请扫二维码加入学习群。计算机视觉战队主要涉及机器学习、深度学习等领域,由来自于各校的硕博研究生组成的团队,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。

![]()
