应用级联CNN的人脸检测--笔记
一、总述:
此基于级联CNN的网络,同时具有高区分能力和快速性(高性能)。
两个结构特点:
1. 采用多分辨率,在前期的低分辨率层,快速的剔除背景区域;在后面的高分辨层,仔细预估难以区分的候选检测图。
2. 基于CNN的矫正层,跟在检测层之后,可以改进定位效率,和为后面层级减少候选的检测图数。
校准层调整检测窗口的位置,它的输出作为后面紧随层的输入。传统VGA图在单核CPU上可以跑到14 FPS,在GPU上可以跑到100 FPS。
二、级联CNN
2.1整体框架

图1
图1检测气的检测流程,从左到右,检测窗口在减少,并且(检测)层与层之间是有调整/矫正层的。
给定一幅图像,12-net将密集的扫描这整幅图像(不同的尺寸),快速的剔除掉超过90%的检测窗口,剩下来的检测窗口将被12-calibration-net逐个的以12x12的图像去调整它的尺寸和位置,让它更接近潜在的人脸图像的附近。
用非极大值抑制(NMS)去除高度重叠的检测窗口。剩下来的检测窗口将会被挑出并归一化没到24x24的图像作为24-net的输入,这将进一步剔除掉剩下来的将近90%的检测窗口。和之前的过程一样,通过24-calibration-net矫正检测窗口,并应用NMS进一步降低检测窗口的数量。
最后的48-net,将通过之前所有层级的检测窗口,以48x48的图像来估计检测窗口。NMS消除重叠是通过使用 交叉覆盖联合(IoU)比率超过预设阈值的方法。24-calibration-net矫正检测窗口作为最后的输出。
2.2 CNN结构
有6个CNNs被级联,3个人脸和非人脸的二分类CNNs;3个边框调整的CNNs,它是多分类的离散位移模式。没有特殊说明,我们使用ReLU非线性函数在下采样层和全连接层之后。
2.2.112-net
在测试流程中我们首先使用12-net吗,见图2。密集的扫描WXH 的图像,步长为4像素,12x12检测窗口。相当于使用12-net去获得一个增幅图像的([(W-12)/4]+1)x([(W-12)/4]+1) 置信分。
如果获得最小的人脸尺寸为F,测试图像会首先被建成图像金字塔,每级比例为12/F,作为12-net的输入。
图2检测网络结构

2.2.212-calibration-net
12-calibration-net是在12-net之后进行边框的矫正。结构见图3。N个矫正模式是预先设定好的,他是一个3维变量变化的无序向量。相关的关系见图4
|
|
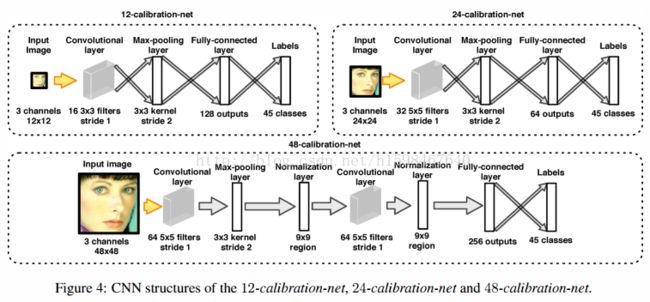
|
|

有N(45)个矫正模式。
给定一个检测窗口,窗口区域被剪出来并归一化到12x12作为12-calibration-net的输入。矫正网络将输出一个置信分的向量 。由于矫正模式之间不是正交的,所以采用高置信分模式的均值,来矫正。相关均值关系见图5。
图5 均值计算定义

2.2.324-net
24-net进一步减少检测窗口的数量,用12-calibration-net的输出窗口,resize到24x24,24-net进行预估。结构在图2。
同样相似,的浅层结构可以提高时间上的效率。并在24-net中采用多分辨率结构。在24-net中为了两种分辨率的图像分别为24x24和12x12。图2 ,全连接层就是之前的12-net的子结构(fully-connected layer),它被串联到128输出的全连接层。带有多分辨率的结构,12-net补充了24-net,可以帮助检测小脸。
图6是是否带多分辨率的实验对比
图6是否带多分辨率的实验对比

2.2.424-calibration-net
与12-calibration-net相比,除了输入size的不同,其它都相同。
2.2.5 48-net
图2,48-net 是相对复杂的,和24-net相似采用了多分辨率。
2.2.6 48-calibration-net
它和12-calibration-net一样都用了45个预先定义的模式。48-calibration-net只用了一个下采样层,这样可以提高矫正精度。
2.2.7 非极大值抑制(NMS)
迭代选择高置信分的检测窗口,消除交叉联合(IoU)比例高于预设阈值的检测窗口。12-net和24-net是浅CNNs,无足够的区分性,假阳性的挑战很大。12-calibration-net和24-calibration-net假阳性的挑战更大,因为跟高的置信分。因此,在12-calibration-net和24-calibration-net后面分别加了NMS,避免相同尺寸的检测窗口的召回率的降低。NMS在48-net被应用到了所有不同比例的窗口上,为了获得最精确的检测位置,及正确的图像比例,和避免冗余估计。
2.3矫正CNN
图7是否矫正对比

蓝色框是未调整的,红色检测框是调整后的。
绝大多数的检测框没有很好地对齐人脸。没有对齐步骤,接下来的级联CNN为了保证召回率,必须去估计更大区域的图像。整体检测时间将明显提高。
这个问题普遍存在于目标检测中。用多分类的矫正CNN代替了R-CNN,因为在有限的训练数据集下,多分类的CNN训练起来跟容易。我们相信离散化降低了矫正问题的难度,所以可以用更简单的CNN结构,获得好的矫正精度。
2.4训练过程
在级联CNNs的训练中,使用了5800张背景图来获得负样本,用AFLW作为正样本。在二分类和多分类的级联CNNs的训练中用了多元逻辑回归目标函数进行优化。
2.4.1矫正网络
对于矫正网络的训练数据,我们将标注好的人脸,用前面的45种矫正模式进行扰动。例如第n种模式 ,应用去调整标注好的人脸框,剪出来resize到(12x12,24x24,48x48)。
2.4.2检测网络
12-net,24-net,48-net是按照级联结构训练的:
a.随机抽样20万张Neg,12x12 Pos 训练12-net
b.用12-net和12-cali级联(2-stage)在AFLW上确定阈值T1(置信分,99%的召回率)
c.在background 用2-stage,开采Neg,大于T1的图 喂给24-net
d.N(大于T1)和P(24x24)训练24-net
e.同样方法级联(4-stage)在AFLW确定T2(97%recall)
f.同c开采neg(大于T2)喂给48-net
g.训练 48-net N P(48x48)