Spark集群安装
Spark集群安装
1 环境准备
网上的资料真的是太混乱了,写的都是乱七八糟。还得自己动手
1.1 机器环境
使用vmware准备三台机器
192.167.2.10 Master
192.167.2.11 Slave1
192.167.2.12 Slave2
注意一定要在/etc/sysconfig/network和hosts中修改主机名称和ip映射。在spark中是通过主机名称来找master。
1.2 软件环境
创建用户spark或者hadoop这个随意,最好修改一下/etc/sudoers文件,让这些用户有sudo的权限方便。
1.3 需要安装的软件
1)jdk-8u92-linux-x64.gz
2) hadoop-2.7.3.tar.gz
3) spark-2.0.2-bin-hadoop2.7.tgz
这是最小安装
1.4 关闭防火墙
Systemctl stop firewalld
Systemctl disable firewalld
2 安装java
这个简单,我就直接写命令了
tar –zvxf jdk-8u92-linux-x64.gz
sudo mv jdk1.8.92 /usr/local/jdk
修改.bash_profile
Export JAVA_HOME=/usr/local/jdk
Export PATH=$PATH:$JAVA_HOME/bin
然后source .bash_profile使其生效。这个简单,也可以子啊/etc/profile中修改。三个机器要安装。建议三台机器安装的路径要一致。
3 Ssh配置
这是一个关键的问题。
在192.167.2.10上
Ssh-genkey –t rsa
在~/.ssh/目录下创建了id_rsa和id_rsa.pub文件,而id_rsa.pub为公钥。
Cd ~/.ssh/
Cat id_rsa.pub >> authorized_keys
Chmod 600 authorized_keys 只有将权限修改为600才起作用。
使用ssh localhost测试是否无密码登录本地。
将authorized_keys拷贝到192.167.2.11和192.167.2.12上。都是~/.ssh/目录下即
~/.ssh/authorized_keys文件。
将.ssh目录修改为700,将authorized_keys文件修改为600
通过ssh Slave1和ssh Slave2来测试是否能无密码登录远程机器。
4 安装hadoop
4.1 软件安装
我使用了用hlf用户,所以在/home/hlf目录,我就在这个目录下完成hadoop和spark的安装。
Cd /home/hlf
Mkdir hadoop
将hadoop-2.7.3.tar.gz上传到hadoop目录下
Tar –zvxf Hadoop-2.7.3.tar.gz
这样/home/hlf/hadoop/hadoop-2.7.3就存在了
4.2 配置文件
在/home/hlf/hadoop/hadoop-2.7.3中的etc/hadoop/是配置文件
需要修改的文件:
Hadoop-env.sh
Core-site.xml
Hdfs-site.xml
Mapred-site.xml
Yarn-site.xml
4.2.1 Hadoop-env.sh
在hadoop-env.sh中添加export JAVA_HOME=/usr/local/jdk
4.2.2 Core-site.xml
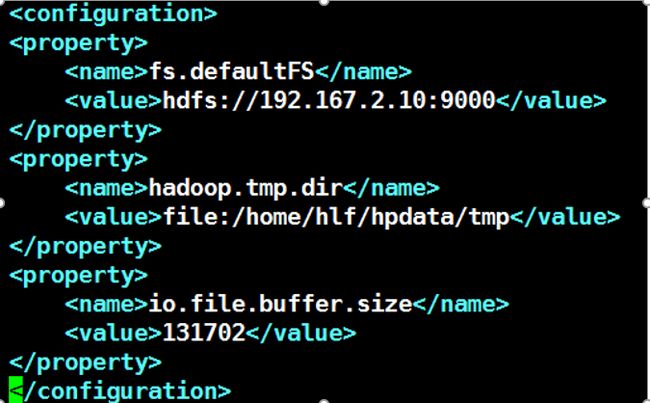
在该文件中用到了临时目录,所以使用mkdir 要创建/home/hlf/hpdata/tmp目录。
4.2.3 Hdfs-site.xml
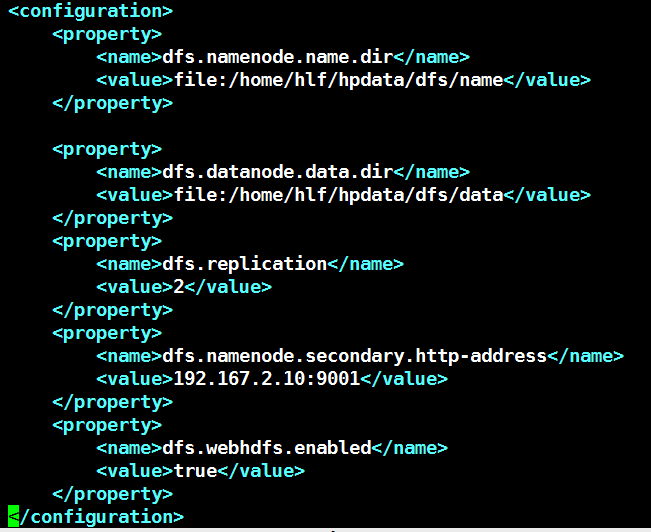
在该文件中需要使用/home/hlf/hpdata/dfs/data目录和/home/hlf/hpdata/dfs/name目录
4.2.4 Mapred-site.xml
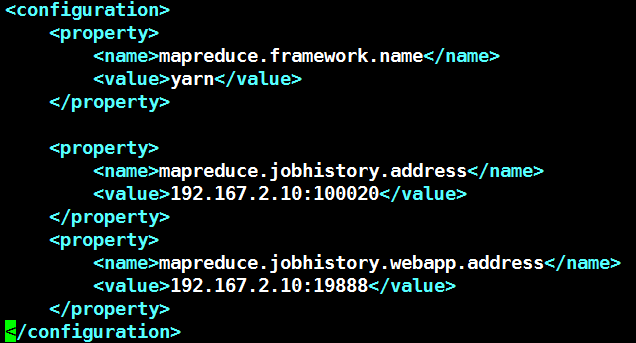
4.2.5 Yarn-site.xml
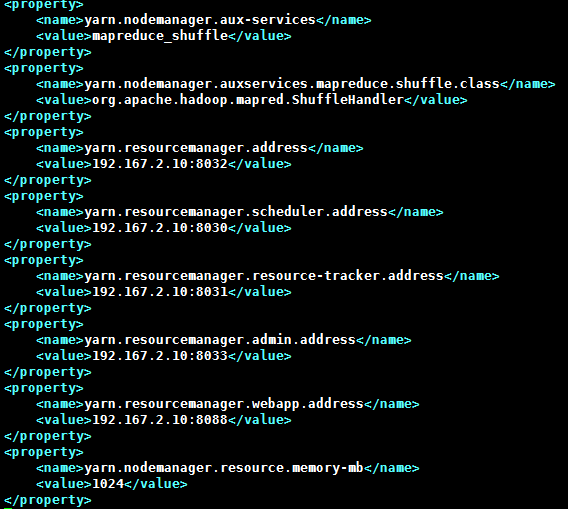
注意yarn.nodemanager.resource.memory-mb至少为1024
4.2.6 Slaves文件
在该文件中添加
192.167.2.11
192.167.2.12
4.3 分布
将/home/hlf/hadoop目录分发大Slave1和Slave2中。
4.4 运行
bin/hdfs namenode -format 进行格式化
sbin/start-all.sh启动hadoop系统。
5 安装spark
将spark-2.0.2-bin-hadoop2.7.tgz上传到/home/hlf/spark下,解压为spark-2.0.2-bin-hadoop2.7
在conf目录中是配置文件,修改spark-env.sh文件和slaves文件
5.1 Slaves文件
添加如下:
Master
Slave1
Slave2
5.2 Spark-env.sh

5.3 启动
Spark目录下的sbin/start-all.sh
5.4 测试
Spark目录下bin/pyspark启动python的shell进行测试。
6 总结
这是最小的安装和配置,可以作为玩具的类型进行学习和研究。