tensorflow二分类
模型创建
加载数据
这里是对tensorflow的学习,所以没有什么特别有意义的数据,我是使用sklearn生成的二分类数据
sklearn.datasets.make_classification(n_samples=100, n_features=20, n_informative=2, n_redundant=2, n_repeated=0, n_classes=2, n_clusters_per_class=2, weights=None, flip_y=0.01, class_sep=1.0, hypercube=True, shift=0.0, scale=1.0, shuffle=True, random_state=None)
- n_features :特征个数= n_informative() + n_redundant + n_repeated
- n_informative:多信息特征的个数
- n_redundant:冗余信息,informative特征的随机线性组合
- n_repeated :重复信息,随机提取n_informative和n_redundant 特征
- n_classes:分类类别
- n_clusters_per_class :某一个类别是由几个cluster构成的
对我们来说,假定有500个样本,为了好显示,只取2个特征,不需要冗余的特征,对于简单的二分类,每个类别只有一个簇
from sklearn import datasets
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
x,y = datasets.make_classification(n_samples=500,n_features=2, n_redundant=0, n_informative=2,
n_clusters_per_class=1)
train_x,test_x,train_y,test_y = train_test_split(x,y,test_size=0.3)
plt.scatter(train_x[:,0],train_x[:,1], marker='o', c=train_y,
s=25, edgecolor='k')
train_x,train_y = x 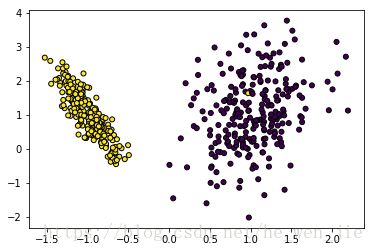
定义模型
首先就是定义输入
x_input = tf.placeholder(tf.float32,shape=[None,n_features],name='input') # data
y_input = tf.placeholder(tf.int32,shape=[None]) # label
这里使用简单的logstic模型
W = tf.Variable(tf.truncated_normal([n_features, n_classes]))
b = tf.Variable(tf.zeros([n_classes]))
logits = tf.sigmoid(tf.matmul(x,W)+b)
predict = tf.arg_max(logits,1,name='predict')损失函数使用交叉熵
loss = tf.losses.sparse_softmax_cross_entropy(logits=logits,labels=y)
loss = tf.reduce_mean(loss)
optimizer = tf.train.AdamOptimizer(0.01).minimize(loss)然后定义精度,训练完之后可以验证精度
_, acc_op = tf.metrics.accuracy(labels=y,predictions=predict)
然后就是定义输入数据了,我们使用batch训练,因此需要先定义一个get_batch函数,用来返回一个batch的数据
def get_batch(x,y,batch):
n_samples = len(x)
for i in range(batch,n_samples,batch):
yield x[i-batch:i], y[i-batch:i]接着就是训练了
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
for epoch in range(100): # 训练次数
for tx,ty in get_batch(train_x,train_y, batch_size): # 得到一个batch的数据
loss_value,_ ,acc_value= sess.run([loss,optimizer,acc_op],feed_dict={x:tx,y:ty})
print('loss = {}, acc = {}'.format(loss_value,acc_value))
acc_value = sess.run([acc_op],feed_dict={x:test_x,y:test_y}) # 验证集的精度,这里验证集和
print('val acc = {}'.format(acc_value))这样整个模型就结束了,下面就是可视化了。
可视化结果
可视化的思想非常简单,就是选取足够多的样本,对这些样本进行分类,根据得到的分数绘制等高线。
首先就是生成网格,取两个特征维度的最大和最小,生成网格,网格其实就是数据
h = 0.02
x_min, x_max = x[:, 0].min() - .5, x[:, 0].max() + .5
y_min, y_max = x[:, 1].min() - .5, x[:, 1].max() + .5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))假如x有两个特征,这两个特征的值范围分别是[0.1,0.2],[0,5,0.7],我们取间隔0.02,这样就会得到
[0.1,0.12,0.14,0.16,0.18,0.2]
[0.5,0.52,0.54,0.56,0.58,0.6,0.62,0.64,0.66,0.68,0.7]我们使用np.c_将不同特征的不同取值组合,得到充分多的样本
np.c_[xx.ravel(), yy.ravel()]结果类似这样的
(0.1,0.5),(0.1,0.52),(0.1,0.54)......
(0.12,0.5),(0.12,0.52),(0.12,0.54)......
....
(0.14,0.5),(0.14,0.52),(0.14,0.54)......xx是x的坐标值,yy是y的坐标值,相互对应的。这相当于我们人为的创建了密集的样本,接着就是使用训练好的模型对这样样本进行分类了,得到每个样本的概率值
prob = sess.run([logits],feed_dict={x:np.c_[xx.ravel(), yy.ravel()]})然后我们将prob重新reshape成xx的尺寸,这样每个平面上坐标(xx,yy)的值为prob,使用plt.contourf绘制等高线
cm = plt.cm.RdBu
plt.contourf(xx, yy, z,cmap=cm, alpha=.3)
# contour lines
#plt.contour(xx, yy, z, colors='k')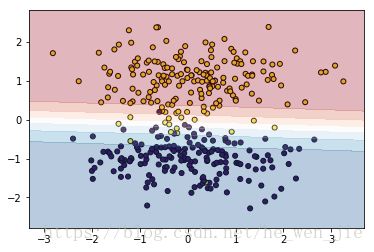
模型数据显示
我们在训练的时候希望绘制出损失的曲线,或者看看数据什么的,这个时候print怕是不行了,因此需要使用tf.summary函数将想要显示的数据写到log中,通过tensorboard查看。
tf.summary
首先就是写入计算图
train_writer = tf.summary.FileWriter(path, sess.graph)然后就是写入数据了,这里要就是loss和acc了(标量)
tf.summary.scalar('loss', loss)
tf.summary.scalar('acc', acc_op)每一个都是一个操作符,所以必须通过sess才能显示出数据来,但是一个个的输进去很慢,我们可以将所有的summary合并成一个操作符
merge_summary = tf.summary.merge_all()只需要每一步计算merge_summary就相当于计算了所有的summary
_ ,train_summary = sess.run([optimizer,merge_summary],feed_dict={x:tx,y:ty})得到所有的summary的值之后,下一步就是将数据写到log里了
train_writer.add_summary(train_summary,step) #step表示训练的步数。模型的保存和加载
训练也训练完了,显示也可以显示了,下一步就是保存模型了,tensorflow提供了tf.train.Saver()函数进行模型的保存和恢复
saver = tf.train.Saver()tf.train.Saver()有几个参数用来控制模型的保存,
max_to_keep : 用来保存checkpoint 的个数,默认是5,设置0或者None表示保存最新的一次
keep_checkpoint_every_n_hours : 隔多长时间保存一次(不知道和下面的global_step会不会冲突)
tf.train.Saver()默认是保存所有的变量,如果我们想要保存某些变量可以
v1 = tf.Variable(..., name='v1')
v2 = tf.Variable(..., name='v2')
# Pass the variables as a dict:
saver = tf.train.Saver({'v1': v1, 'v2': v2})
# Or pass them as a list.
saver = tf.train.Saver([v1, v2])
# Passing a list is equivalent to passing a dict with the variable op names
# as keys:
saver = tf.train.Saver({v.op.name: v for v in [v1, v2]})我一般都会全部保存。
接着将 计算图,张量,变量等保存进去就可以了
saver.save(session, filename) # 保存模型我们不会每一步都保存模型,而可以设定步长,例如1000步之后保存一次
if step % 1000 == 0:
saver.save(sess, 'Model',global_step=step)保存完之后,我们在测试的时候需要将模型加载出来,
首先需要将计算图给加载出来,这是最重要的,有了图才能计算啊
saver=tf.train.import_meta_graph('Model/model-1000.meta')接着加载ckpt路径,ckpt里保存的是模型的参数,之后通过restore函数将参数加载到计算图
ckpt_path = tf.train.latest_checkpoint('Model/')
saver.restore(session, ckpt_path)如果我们有原来的模型,可以直接获得操作符,然后进行计算,例如上面的模型中通过predict操作符可以得到类别
saver=tf.train.import_meta_graph('Model/model-1000.meta')
ckpt_path = tf.train.latest_checkpoint('Model/')
saver.restore(session, ckpt_path)
with tf.Session() as sess:
sess.run([predict],feed_dict={x_input :[0.1,0.2]})但是有时候我们没有模型代码,只有ckpt等文件,可以根据name从计算图中找到节点。
with tf.Session() as sess:
saver = tf.train.import_meta_graph('Model/model-1000.meta')
saver.restore(sess, tf.train.latest_checkpoint('Model/'))
graph = tf.get_default_graph()
x_input = graph.get_tensor_by_name("x_input:0")
predict = graph.get_tensor_by_name("predict:0")
print(sess.run([predict],feed_dict={x_input:[[1,2]]}))都到这个地步我们也就可以试试fine-tuning了。
有时候我们没有定义name,所以需要查看一下,可以通过查看tf.global_variables()或tf.train_variables()
saver = tf.train.import_meta_graph('Model/model-1000.meta')
ckpt_path = tf.train.latest_checkpoint('Model/')
saver.restore(sess, ckpt_path)
train_vars = tf.global_variables()
for var in train_vars:
print(var.name)还有就是tensorflow自带的函数
from tensorflow.python import pywrap_tensorflow
ckpt_path = tf.train.latest_checkpoint('Model/')
reader = pywrap_tensorflow.NewCheckpointReader(ckpt_path)
all_var = reader.get_variable_to_shape_map()
print(all_var)完整的一个代码
from sklearn import datasets
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
n_features = 2
n_classes = 2
batch_size = 32
h = 0.2
x,y = datasets.make_classification(n_samples=500,n_features=n_features,
n_redundant=0, n_informative=1,
n_classes=n_classes,n_clusters_per_class=1)
train_x,test_x,train_y,test_y = train_test_split(x,y,test_size=0.3)
x_min, x_max = x[:, 0].min() - .5, x[:, 0].max() + .5
y_min, y_max = x[:, 1].min() - .5, x[:, 1].max() + .5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
#print(xx.shape)
#print(yy.shape)
#print(np.c_[xx.ravel(), yy.ravel()])
def get_batch(x,y,batch):
n_samples = len(x)
for i in range(batch,n_samples,batch):
yield x[i-batch:i], y[i-batch:i]
x_input = tf.placeholder(tf.float32,shape=[None,n_features],name='x_input')
y_input = tf.placeholder(tf.int32,shape=[None],name='y_input')
W = tf.Variable(tf.truncated_normal([n_features, n_classes]),name='W')
b = tf.Variable(tf.zeros([n_classes]),name='b')
logits = tf.sigmoid(tf.matmul(x_input,W)+b)
predict = tf.arg_max(logits,1,name='predict')
loss = tf.losses.sparse_softmax_cross_entropy(logits=logits,labels=y_input)
loss = tf.reduce_mean(loss)
tf.summary.scalar('loss', loss)
optimizer = tf.train.AdamOptimizer(0.01).minimize(loss)
acc, acc_op = tf.metrics.accuracy(labels=y_input,predictions=predict)
tf.summary.scalar('acc', acc_op)
merge_summary = tf.summary.merge_all()
with tf.Session() as sess:
train_writer = tf.summary.FileWriter('log', sess.graph)
saver = tf.train.Saver(max_to_keep=4)
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
step = 0
for epoch in range(100): # 训练次数
for tx,ty in get_batch(train_x,train_y, batch_size): # 得到一个batch的数据
step += 1
loss_value,_ ,acc_value,train_summary= sess.run([loss,optimizer,acc_op,merge_summary],feed_dict={x_input:tx,y_input:ty})
train_writer.add_summary(train_summary,step)
if step % 100 == 0:
saver.save(sess, 'Model/model',global_step=step)
print('loss = {}, acc = {}'.format(loss_value,acc_value))
acc_value = sess.run([acc_op],feed_dict={x_input:test_x ,y_input:test_y})
print('val acc = {}'.format(acc_value))
prob = sess.run([logits],feed_dict={x_input:np.c_[xx.ravel(), yy.ravel()]})
prob = prob [0][:,0].reshape(xx.shape)
plt.scatter(train_x[:,0],train_x[:,1], marker='o', c=train_y,
s=25, edgecolor='k')
# filled contours
cm = plt.cm.RdBu
plt.contourf(xx, yy, prob,cmap=cm, alpha=.3)
# contour lines
#plt.contour(xx, yy, prob, colors='k')然后新定义一个文件用来测试
import tensorflow as tf
with tf.Session() as sess:
saver = tf.train.import_meta_graph('Model/model-1000.meta')
saver.restore(sess, tf.train.latest_checkpoint('Model/'))
graph = tf.get_default_graph()
x_input = graph.get_tensor_by_name("x_input:0")
predict = graph.get_tensor_by_name("predict:0")
print(sess.run([predict],feed_dict={x_input:[[1,2]]}))TensorBoard:可视化学习
Tensorflow加载预训练模型和保存模型
tf.train.Saver
如何从ckpt文件中拷贝权值到新的变量中
numpy之meshgrid和where
numpy 辨异 (五)—— numpy.ravel() vs numpy.flatten()