YOLO合集:You Only Look Once
YOLO现在有三个版本,每个版本相对于之前都有很大的进步,现总结如下。
YOLO
论文"YouOnlyLookOnce: Unified,Real-TimeObjectDetection":
https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Redmon_You_Only_Look_CVPR_2016_paper.pdf
这是最早的YOLO版本,当时提出来非常的新颖,因为整个YOLO做object detection只用了一个端到端的CNN,同时产生bounding box和class probability。
YOLO另外一个特点就是它的inference很快,文章中提到real-time中,YOLO可以在Titan X上做到45fps;在YOLO的fast模型中,甚至可以做到155fps。
YOLO将object detection这个问题转换为了从像素到bounding box的坐标和class probability的一个回归问题。
1 Unified Detection
YOLO将整幅image拆分成![]() 个方格,每个方格中有B个bounding box和confidence score,其中confidence的定义为:
个方格,每个方格中有B个bounding box和confidence score,其中confidence的定义为:![]() .
.
同时每个bounding box包含5个预测值:![]() .其中
.其中![]() 代表的是bounding box的center距离每个方格的偏离。
代表的是bounding box的center距离每个方格的偏离。
同时每个方格(注意是方格不是bounding box)有一个class probability tensor:![]() ,最后通过这个计算每一个bounding box的probability:
,最后通过这个计算每一个bounding box的probability:
![]()
在PASCAL VOC数据集上,采用的是![]() 的方式。
的方式。
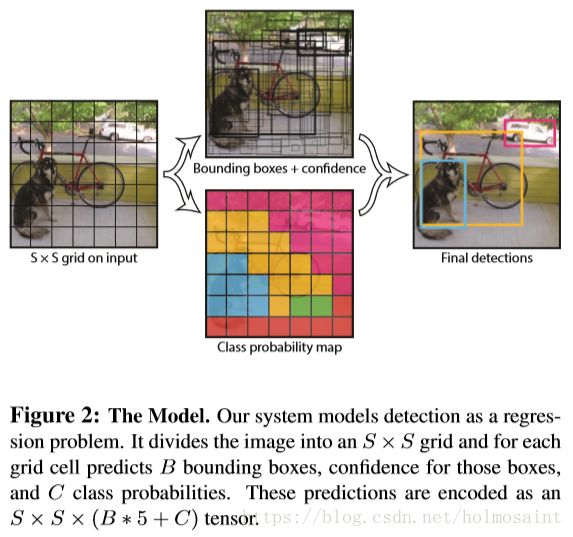
1.1 Network Design
文章参考了GoogLeNet的设计,但是没有使用Inception model,而是在![]() 的filter之前先增加一个reduce dimension的
的filter之前先增加一个reduce dimension的![]() 的filter。
的filter。
基本的YOLO模型有24层卷积层,2层fc层;fast模型中只有9层卷积层,并且filter的数量会更少。
整体的网络结构如下:

1.2 Training
首先在ImageNet的classfication的任务上pre-train了前20层卷积层。
之后添加4层卷积层和2层fc层,随即初始化权重,然后将input image的size扩大到![]() ,继续训练。
,继续训练。
在最后一层使用的是线性的activation函数,其他层使用的都是:

在loss function中,增加了坐标预测错误的loss并且减少了没有包含物体的box的从confidence score的loss。
同时,在训练的时候只用一个bounding box predictor负责一个物体,选择IOU分数最高的predictor来负责。这有助于使得特定的predictor能够负责ratio,scale相似的bounding box。
最终的loss function为:

Learning rate:在first epochs从![]() 逐步升到
逐步升到![]() ,然后稳定在
,然后稳定在![]() 训练75周期,
训练75周期,![]() 训练30周期,最后
训练30周期,最后![]() 训练30周期。
训练30周期。
momentum:0.5
dropout:0.5
weight decay:0.0005
同时也采用了extensive data augmentation的方式来减小overfitting。
1.3 Inference
在PASCAL VOC的数据集上,每张图片可以产生98个bounding box。最后使用NMS可以使得mAP提升3%左右。
1.4 Limitations of YOLO
YOLO限制了每一个方格只能有2个bounding box,同时这两个bounding box只能预测一个物体,这使得在空间上有了很大的局限性,很多小的物体很难被侦测到。
再者YOLO本身也不能很好的detect比例、形态异于常规的物体;同时由于downsampling的比例太大,其习得的feature非常的粗糙。
最后,loss function对于在大小不一的bounding box中的错误是一视同仁的,但是直觉上来看,在小一点的bounding box上错误会显得更大一些。
YOLOv2
论文“YOLO9000: Better,Faster,Stronger”:
http://openaccess.thecvf.com/content_cvpr_2017/papers/Redmon_YOLO9000_Better_Faster_CVPR_2017_paper.pdf
YOLOv2的性能比起YOLO有很大的提升。在67FPS的情况下,YOLOv2在VOC 2007上的mAP有76.8;在40FPS的情况下,YOLOv2的 mAP为78.6.
(本博客不对YOLO9000进行讨论)
1 Better
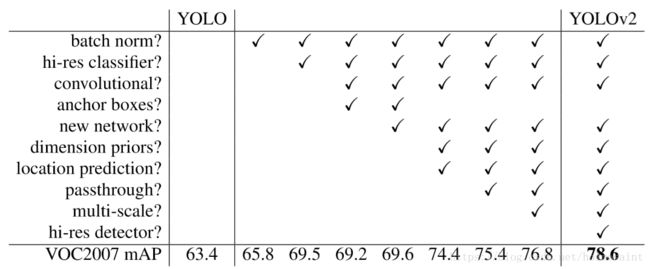
YOLO和Faster R-CNN相比,出现了更多的localization的错误,同时和region proposal-based的方法相比,召回率也相对较低。YOLOv2主要针对了这两个方面进行了改进,增加一下这些手段:
1.1 Batch Normalization
通过在所有卷积层的增加BatchNorm使得总体的mAP提升了2%左右,并且BatchNorm的使用起到了regularization的作用,不需要再使用Dropout了。
1.2 High Resolution Classifier
由于在YOLO中训练的图片大小为![]() ,然后detection inference的时候直接就放的是
,然后detection inference的时候直接就放的是![]() 的图片,这使得网络的性能会想对更差,所以YOLOv2在最后用
的图片,这使得网络的性能会想对更差,所以YOLOv2在最后用![]() 的图片在ImageNet上fine-tune了10个epoch。
的图片在ImageNet上fine-tune了10个epoch。
1.3 Convolutional With Anchor Boxes
在YOLOv2中去掉了fc层改成了使用anchor box来进行推断。
首先去掉了一个pooling层也用来提高网络的resoluton,同时将网络的输入变成了![]() ,这是因为416位奇数可以保证只用一个唯一的中心方格(对于大物体而言比较好,因为他们通常占据了图片的大多部分)。这样YOLOv2的卷积层的downsampling rate为32,所以最后得到的是
,这是因为416位奇数可以保证只用一个唯一的中心方格(对于大物体而言比较好,因为他们通常占据了图片的大多部分)。这样YOLOv2的卷积层的downsampling rate为32,所以最后得到的是![]() 的feature map。
的feature map。
和YOLO一样,最终的detection预测IOU,box和class probability。
使用了anchor box之后,在accuracy上有一定的下降。但是YOLO只会在每张image上产生98个box,但是使用anchor box就会产生上千个box,这使得召回率有了很大的提升。
1.4 Dimension Clusters
anchor box的size都是手动选择的,为了使得size的大小更好,使用了k-means的方法来对训练集上的bounding box做聚类分析来选择好的priors。最终选择的distance metric是和IOU紧密相关的:
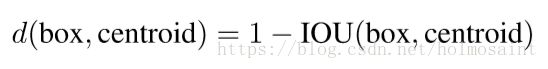
最终在complexity和high recall中间选择了k=5。
1.5 Direct Location Prediction
使用anchor box之后会遇到模型不稳定这个问题,因为如果使用绝对的offset作为坐标的预测的话,这些数值是没有限制的。所以和YOLO采用了相同的方法,即预测和grid cell的offset,同时做logistic activation来把数值限制在0~1之间:

1.5 Fine-Grained Features
上文中提到最终得到的feature map是![]() 的,为了提高小物体的召回率,简单地增加了一个旁路从更底层的layer中之间连接过来了一个
的,为了提高小物体的召回率,简单地增加了一个旁路从更底层的layer中之间连接过来了一个![]() 个feature map,然后把它和
个feature map,然后把它和![]() 的feature map连接起来。即
的feature map连接起来。即![]() 的feature map变成了
的feature map变成了![]() 的feature map。
的feature map。
1.6 Multi-Scale Training
在training的时候,每10个epoch更换一次input image size,使用的size大小都是32的倍数(因为downsampling rate为32)。
最终下图为每种新的方式对于YOLOv2的贡献:
2 Faster
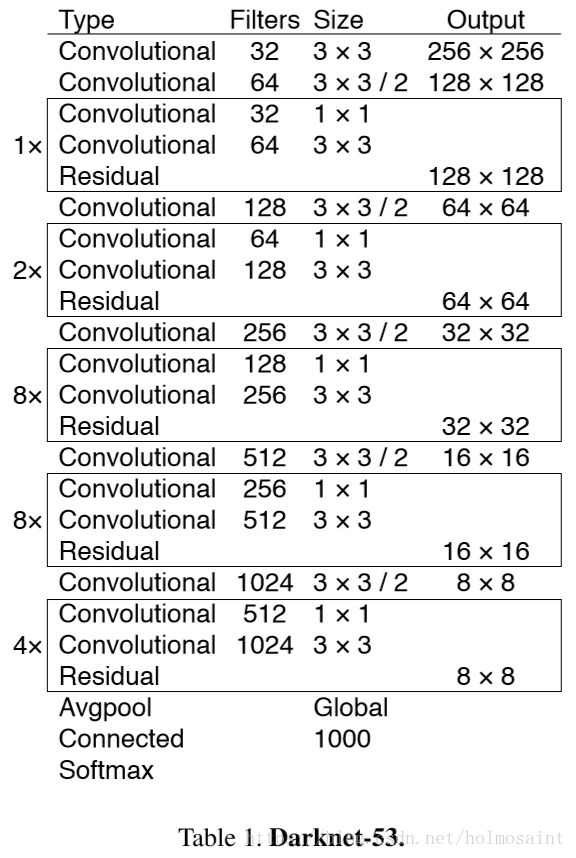
这一次YOLOv2使用了全新的classification的框架:Darknet-19。
几乎全部使用的是![]() 的filter并且在每个pooling later之后会将channel的数量翻倍,最终使用global average pooling来进行预测。
的filter并且在每个pooling later之后会将channel的数量翻倍,最终使用global average pooling来进行预测。
Darknet-19只有55.8亿次操作(VGG-16有306.9亿,GoogLeNet有85.2亿)
具体的网络架构如下:

2.1 Training for Classification
在ImageNet训练160个epoch,使用SGD。
learning rate:0.1,然后4次多项式递减。
wight decay:0.0005
momentum:0.9
在![]() 的图片上面训好了之后,在
的图片上面训好了之后,在![]() 的图片上fine-tune 10个epoch,learning rate为0.001.
的图片上fine-tune 10个epoch,learning rate为0.001.
2.2 Training for Detection
去掉最后一个conv layer然后增加3个![]() 的卷积层,然后每一个后面都跟一个
的卷积层,然后每一个后面都跟一个![]() 的卷基层。
的卷基层。
然后在最后一个conv layer中增加从前一个layer得到的feature。
总共训练160个epoch。
learning rate:0.001,在10,60,90个epoch递减。
weight decay:0.0005,momentum:0.9.
YOLOv3
在![]() 的input上,YOLOv3可以在22ms内完成,并且保证28.2的mAP,这比SSD快了3倍。同时在Titan X上,能够在51ms的水平上达到57.9的AP50。和其他方法的性能对比如下:
的input上,YOLOv3可以在22ms内完成,并且保证28.2的mAP,这比SSD快了3倍。同时在Titan X上,能够在51ms的水平上达到57.9的AP50。和其他方法的性能对比如下:

1 Bounding Box Prediction
在训练的时候使用的是平方误差。同时Yolov3也会对每个bounding box预测一个分数来判断其是否有物体在其中,使用的目标函数是逻辑回归。如果有一个bounding box和ground truth之间的重叠数值超过了其他的任何bounding box,那么它回归的值就是1;而对于剩下的bounding box的确覆盖ground truth超过了某一个threshold,就单纯忽略掉这一个。使用的threshold为0.5.
如果一个bounding box没有被分匹配到一个object,那么对于它的loss计算就只有object,而没有坐标的误差。
2 Class Prediction
每一个bounding box可能包含使用multilabel的classfication。同时不再使用softmax,因为作者发现他们对于performance没有本质的提升作用。同时在训练的时候,使用的是binary cross-entropy来衡量损失。
3 Predictions Across Scales
YOLOv3在3种不同的尺寸来预测bounding box。在COCO的数据集上,每个scale预测3个box,所以最终的tensor的规格是![]() ,因为一共有4个坐标offset,1个objectness prediction和80个class predictions。
,因为一共有4个坐标offset,1个objectness prediction和80个class predictions。
4 Feature Extractor
最终推出了叫做Draknet-53的feature extractor,使用了很多![]() 和
和![]() 的卷积核组。
的卷积核组。
Darknet-53和ResNet其实很像,但是Darknet要高效很多,下面是性能的对比图:
