系统学习NLP(二)--语音合成的计算机处理综述
参考:https://blog.csdn.net/zlj925/article/details/79061900 略删改。
语音合成跟语音识别,自然语音理解,作为人机交互的基础模块,加上对话管理器,形成人机语音对话系统。
语音合成原理
语音合成(Text to Speech,TTS)是指将文本通过一系列的信号处理转换为“人造”语音(声学波形)。与简单的录音播放不同,机器进行语音合成时,往往并没有这些文本的人声录音,而是通过音节拼接与参数调整来生成尽可能接近人声的合成语音。
语音合成一般会经过文本与韵律分析、声学处理与声音合成三个步骤,分别依赖于文本与韵律分析模型、声学模型与声码器。
其中文本与韵律分析模型一般被称为“前端”,声学模型和声码器被称为“后端”。也可以定义为输入文本转换成语音内部表示的文本分析阶段和内部表示转换为波形的波形合成。
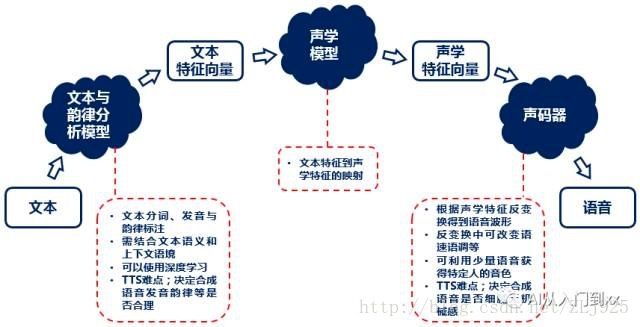
(语音合成的处理过程)
文本与韵律分析中,首先对文本进行分词和标注:分词会将文本切成一个个词语,标注则会注明每个字的发音以及哪里是重音、哪里需要停顿等韵律信息;然后根据分词和标注的结果提取文本的特征,将文本变成一个个文本特征向量组成的序列。也就是文本分析的结果,内部表示。
声学模型建立了从文本特征向量到声学特征向量的映射:一个个文本特征向量经过声学模型的处理,会变成一个个声学特征向量。
声码器则会将一个个声学特征向量通过反变换分别得到相应的声音波形,然后依次进行拼接就得到了整个文本的合成语音。
声学特征反映了声音信号的一些“关键信息”,反变换则可看作用关键信息还原全量信息。所以在反变换的过程中可以有人为“操作”的空间(如参数的调整),从而改变合成语音的语调、语速等。
反变换的过程还可以让合成的语音具备特定的音色。录制某个人少量的语音片段,在合成时即可据此调整参数,让合成的语音拥有这个人的音色。老司机们最爱的“林志玲导航语音包”就是这么来的。

(别伤心,你们的女神还是多少录了几句话的)
红遍宇宙的深度学习技术同样可以运用在语音合成中。无论是文本与韵律分析模型、声学模型还是声码器,都可以采用通过大量的文本和语音数据训练出的深度神经网络。
语音合成在功能上可以看作语音识别的“逆过程”。语音识别是通过语音波形提取得到声学特征向量,再变为文本特征向量,最后得到文本;而语音合成则是通过文本提取得到文本特征向量,再变为声学特征向量,最后反变换得到合成语音波形。
然而,语音识别和语音合成在每个步骤的技术原理却差异很大。语音识别可以看作是一个分类问题(连续到离散),而语音合成则应看作回归问题(离散到连续);前者希望尽可能排除个体发音的差异获得其中的“共性”,后者则是从“共性”出发,希望尽可能还原个体发音的特色,获得更有表现力的合成语音。
像一点,再像一点
和语音识别不同,对语音合成质量的评价标准相对主观。对于一段合成语音,一些人耳中的“发音错误”对其他人来说可能只是“发音不准”;同时,什么样的声音像人声,像到什么程度,都很难通过几个像“准确率”这样的简单指标来进行评价。
所以,语音合成的质量一般通过人工根据一系列规则打分来评价;而让合成的语音听起来像真实的人声,则是语音合成真正的难点所在。现代语音合成的研究可以追溯到数十年前,但这个问题直到现在也没有完全解决。
语音合成的难点主要来自前端的文本与韵律分析以及后端的声码器,它们也成为了目前各家公司语音合成技术实力的体现。
文本与韵律分析中的分词与标注往往需要结合文本语义以及上下文的有关的内容才能作出准确的判断,而这些也正是自然语言处理中的难点。如果这一步的处理出了问题,那么合成语音的节奏、语调等听起来就会比较奇怪。

(重音会随着语义的变化而变化)
声码器反变换得到语音波形时,由于声学特征只反映了语音波形的少量关键信息,所以还需要通过参数调整,添加大量信息,才能使合成语音听起来圆润细腻、没有机械感。真实的人声拥有非常丰富的细节信息,所以会使反变换的过程变得困难。
得到声学特征向量之后,也可以不用声码器,直接通过录音拼接的方法进行合成。这种方式需要事先录制大量的真人语音片段,然后根据声学特征向量找到它们所对应的那些语音片段直接进行拼接。
录音拼接的方式相当于规避了声码器中参数合成的难度,所以更容易获得高质量的语音,但所需要的语音片段数据量可能会非常庞大。所以,这种方法一般用在机器需要播放的合成语句的数量比较有限的场景中。
硬币的正反面
