Resnet解构
目录
- 卷积层的残差连接的keras实现
- 结构鸟瞰
- initial layer
- main block1
- block chain
- 可自定义的block4 的卷积过程
- tensor flow 依赖函数
卷积层的残差连接的keras实现
from keras.layers import add, Convolution2D, Input, Activation
from keras.models import Model
x = Input(shape=(256, 256, 64))
y = Convolution2D(64, (3, 3), padding="same",activation='relu')(x)
y = Convolution2D(64, (3, 3), padding="same")(y)
z = add([x, y])
z = Activation('relu')(z)
model = Model(inputs=x, outputs=z)
model.summary()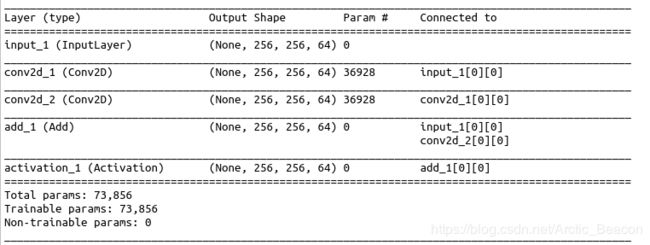
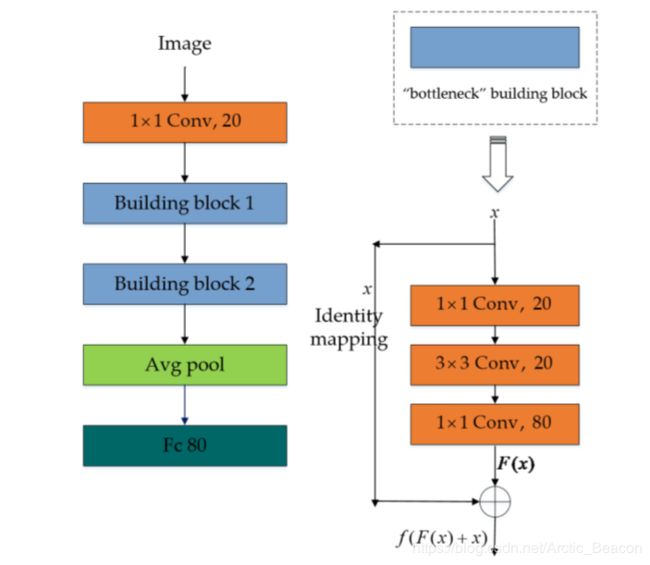
A building block
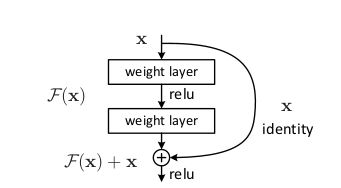
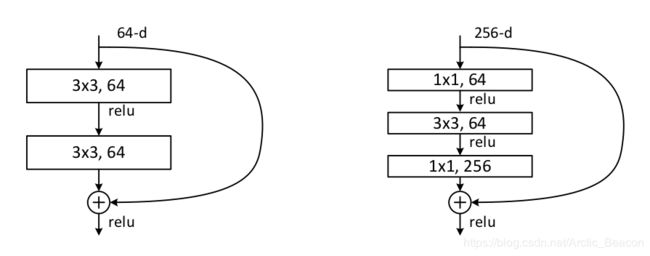
结构鸟瞰
model = ResNet50(weights='imagenet')
model.summary()...
add_48 (Add) (None, 7, 7, 2048) 0 bn5c_branch2c[0][0]
activation_144[0][0]
__________________________________________________________________________________________________
activation_147 (Activation) (None, 7, 7, 2048) 0 add_48[0][0]
__________________________________________________________________________________________________
avg_pool (AveragePooling2D) (None, 1, 1, 2048) 0 activation_147[0][0]
__________________________________________________________________________________________________
flatten_3 (Flatten) (None, 2048) 0 avg_pool[0][0]
__________________________________________________________________________________________________
fc1000 (Dense) (None, 1000) 2049000 flatten_3[0][0]
==================================================================================================
>>>model.layers[-4].output
>>>model.layers[-4].output
>>>model.layers[-1].output
initial layer
inputs = np.ones((512,512),dtype='float32').reshape(1,512,512,1)
with slim.arg_scope([slim.conv2d],activation_fn=None, normalizer_fn=None):
net = conv2d_same(inputs, 64, 7, stride=2, scope='conv1')
print(net.name)
print(net.get_shape())
net = slim.max_pool2d(net, [3, 3], stride=2, scope='pool1')
print(net.name)
print(net.get_shape())conv1/BiasAdd:0
(1, 256, 256, 64)
pool1/MaxPool:0
(1, 127, 127, 64)
main block1
class Block(collections.namedtuple('Block', ['scope', 'unit_fn', 'args'])):
"""
"""
base_depth=64
num_units=3
stride=2
multi_grid=[1, 2, 4]
output_stride = None
block1 = Block('block1', bottleneck, [{'depth': base_depth * 4,'depth_bottleneck': base_depth,'stride': 1}] * (num_units - 1)
+ [{'depth': base_depth * 4,'depth_bottleneck': base_depth,'stride': stride}])
c = block1.args
print(block1.scope)
print(block1.unit_fn)block1
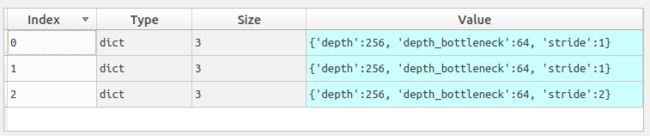
def bottleneck(inputs, depth, depth_bottleneck, stride, rate=1,
outputs_collections=None, scope=None):
with tf.variable_scope(scope, 'bottleneck_v2', [inputs]) as sc:
depth_in = slim.utils.last_dimension(inputs.get_shape(), min_rank=4)
preact = slim.batch_norm(inputs, activation_fn=tf.nn.relu, scope='preact')
print(preact.name)
print(preact.get_shape())
if depth == depth_in:
shortcut = subsample(inputs, stride, 'shortcut')
else:
shortcut = slim.conv2d(preact, depth, [1, 1], stride=stride,
normalizer_fn=None, activation_fn=None,
scope='shortcut')
residual = slim.conv2d(preact, depth_bottleneck, [1, 1], stride=1,
scope='conv1')
residual = conv2d_same(residual, depth_bottleneck, 3, stride,
rate=rate, scope='conv2')
residual = slim.conv2d(residual, depth, [1, 1], stride=1,
normalizer_fn=None, activation_fn=None,
scope='conv3')
output = shortcut + residual
print(output.name)
print(output.get_shape())
return slim.utils.collect_named_outputs(outputs_collections,
sc.name,
output)
def stack_blocks_dense(net, blocks, multi_grid, output_stride=None,
outputs_collections=None):
current_stride = 1
rate = 1
for block in blocks:
with tf.variable_scope(block.scope, 'block', [net]) as sc:
for i, unit in enumerate(block.args):
print("=" * 20)
print(unit)
if output_stride is not None and current_stride > output_stride:
raise ValueError('The target output_stride cannot be reached.')
with tf.variable_scope('unit_%d' % (i + 1), values=[net]):
if output_stride is not None and current_stride == output_stride:
if block.scope == "block4":
net = block.unit_fn(net, rate=rate * multi_grid[i], **dict(unit, stride=1))
else:
net = block.unit_fn(net, rate=rate, **dict(unit, stride=1))
rate *= unit.get('stride', 1)
else:
net = block.unit_fn(net, rate=1, **unit)
current_stride *= unit.get('stride', 1)
net = slim.utils.collect_named_outputs(outputs_collections, sc.name, net)
if output_stride is not None and current_stride != output_stride:
raise ValueError('The target output_stride cannot be reached.')
return net
blocks = [block1]
net = stack_blocks_dense(net, blocks, multi_grid, output_stride)
print(net.name)
print(net.get_shape())
====================
{'depth': 256, 'depth_bottleneck': 64, 'stride': 1}
block1/unit_1/bottleneck_v2/preact/Relu:0
(1, 127, 127, 64)
block1/unit_1/bottleneck_v2/add:0
(1, 127, 127, 256)
====================
{'depth': 256, 'depth_bottleneck': 64, 'stride': 1}
block1/unit_2/bottleneck_v2/preact/Relu:0
(1, 127, 127, 256)
block1/unit_2/bottleneck_v2/add:0
(1, 127, 127, 256)
====================
{'depth': 256, 'depth_bottleneck': 64, 'stride': 2}
block1/unit_3/bottleneck_v2/preact/Relu:0
(1, 127, 127, 256)
block1/unit_3/bottleneck_v2/add:0
(1, 64, 64, 256)
block1/unit_3/bottleneck_v2/add:0
(1, 64, 64, 256)
可以看出,该block的前两个unit:
BN =》relu,分两路
一路,1×1conv(256)/全通
一路,1×1conv(64)relu => 3×3conv(64) relu=> 1×1conv(256)relu
该block最后一个unit:
一路,max_pool2d(inputs, [1, 1], stride=2)
一路,1×1conv(64)relu => 3×3conv(64) (stride=2)relu=> 1×1conv(256)relu
然后两路相加,代入下一个block。
block chain
def resnet_v2_block(scope, base_depth, num_units, stride):
return Block(scope, bottleneck, [{
'depth': base_depth * 4,
'depth_bottleneck': base_depth,
'stride': 1
}] * (num_units - 1) + [{
'depth': base_depth * 4,
'depth_bottleneck': base_depth,
'stride': stride
}])
blocks = [
resnet_v2_block('block1', base_depth=64, num_units=3, stride=2),
resnet_v2_block('block2', base_depth=128, num_units=4, stride=2),
resnet_v2_block('block3', base_depth=256, num_units=6, stride=2),
resnet_v2_block('block4', base_depth=512, num_units=3, stride=1),
]
multi_grid=[1, 2, 4]
output_stride = 16
if output_stride % 4 != 0:
raise ValueError('The output_stride needs to be a multiple of 4.')
output_stride /= 4
net = stack_blocks_dense(net, blocks, multi_grid, output_stride)===================> block1
unit: {'depth': 256, 'depth_bottleneck': 64, 'stride': 1}
mark 3
block1/unit_1/bottleneck_v2/preact/Relu:0
(1, 127, 127, 64)
block1/unit_1/bottleneck_v2/add:0
(1, 127, 127, 256)
unit: {'depth': 256, 'depth_bottleneck': 64, 'stride': 1}
mark 3
block1/unit_2/bottleneck_v2/preact/Relu:0
(1, 127, 127, 256)
block1/unit_2/bottleneck_v2/add:0
(1, 127, 127, 256)
unit: {'depth': 256, 'depth_bottleneck': 64, 'stride': 2}
mark 3
block1/unit_3/bottleneck_v2/preact/Relu:0
(1, 127, 127, 256)
block1/unit_3/bottleneck_v2/add:0
(1, 64, 64, 256)
===================> block2
unit: {'depth': 512, 'depth_bottleneck': 128, 'stride': 1}
mark 3
block2/unit_1/bottleneck_v2/preact/Relu:0
(1, 64, 64, 256)
block2/unit_1/bottleneck_v2/add:0
(1, 64, 64, 512)
unit: {'depth': 512, 'depth_bottleneck': 128, 'stride': 1}
mark 3
block2/unit_2/bottleneck_v2/preact/Relu:0
(1, 64, 64, 512)
block2/unit_2/bottleneck_v2/add:0
(1, 64, 64, 512)
unit: {'depth': 512, 'depth_bottleneck': 128, 'stride': 1}
mark 3
block2/unit_3/bottleneck_v2/preact/Relu:0
(1, 64, 64, 512)
block2/unit_3/bottleneck_v2/add:0
(1, 64, 64, 512)
unit: {'depth': 512, 'depth_bottleneck': 128, 'stride': 2}
mark 3
block2/unit_4/bottleneck_v2/preact/Relu:0
(1, 64, 64, 512)
block2/unit_4/bottleneck_v2/add:0
(1, 32, 32, 512)
===================> block3
unit: {'depth': 1024, 'depth_bottleneck': 256, 'stride': 1}
mark 2
block3/unit_1/bottleneck_v2/preact/Relu:0
(1, 32, 32, 512)
block3/unit_1/bottleneck_v2/add:0
(1, 32, 32, 1024)
unit: {'depth': 1024, 'depth_bottleneck': 256, 'stride': 1}
mark 2
block3/unit_2/bottleneck_v2/preact/Relu:0
(1, 32, 32, 1024)
block3/unit_2/bottleneck_v2/add:0
(1, 32, 32, 1024)
unit: {'depth': 1024, 'depth_bottleneck': 256, 'stride': 1}
mark 2
block3/unit_3/bottleneck_v2/preact/Relu:0
(1, 32, 32, 1024)
block3/unit_3/bottleneck_v2/add:0
(1, 32, 32, 1024)
unit: {'depth': 1024, 'depth_bottleneck': 256, 'stride': 1}
mark 2
block3/unit_4/bottleneck_v2/preact/Relu:0
(1, 32, 32, 1024)
block3/unit_4/bottleneck_v2/add:0
(1, 32, 32, 1024)
unit: {'depth': 1024, 'depth_bottleneck': 256, 'stride': 1}
mark 2
block3/unit_5/bottleneck_v2/preact/Relu:0
(1, 32, 32, 1024)
block3/unit_5/bottleneck_v2/add:0
(1, 32, 32, 1024)
unit: {'depth': 1024, 'depth_bottleneck': 256, 'stride': 2}
mark 2
block3/unit_6/bottleneck_v2/preact/Relu:0
(1, 32, 32, 1024)
block3/unit_6/bottleneck_v2/add:0
(1, 32, 32, 1024)
===================> block4
unit: {'depth': 2048, 'depth_bottleneck': 512, 'stride': 1}
mark 1
block4/unit_1/bottleneck_v2/preact/Relu:0
(1, 32, 32, 1024)
block4/unit_1/bottleneck_v2/add:0
(1, 32, 32, 2048)
dilates rate: 1
unit: {'depth': 2048, 'depth_bottleneck': 512, 'stride': 1}
mark 1
block4/unit_2/bottleneck_v2/preact/Relu:0
(1, 32, 32, 2048)
block4/unit_2/bottleneck_v2/add:0
(1, 32, 32, 2048)
dilates rate: 2
unit: {'depth': 2048, 'depth_bottleneck': 512, 'stride': 1}
mark 1
block4/unit_3/bottleneck_v2/preact/Relu:0
(1, 32, 32, 2048)
block4/unit_3/bottleneck_v2/add:0
(1, 32, 32, 2048)
dilates rate: 4
可自定义的block4 的卷积过程
def bottleneck(inputs, depth, depth_bottleneck, stride, rate=1,
outputs_collections=None, scope=None):
with tf.variable_scope(scope, 'bottleneck_v2', [inputs]) as sc:
depth_in = slim.utils.last_dimension(inputs.get_shape(), min_rank=4)
preact = slim.batch_norm(inputs, activation_fn=tf.nn.relu, scope='preact')
print(preact.name)
print(preact.get_shape())
if depth == depth_in:
shortcut = subsample(inputs, stride, 'shortcut')
print('identity route:')
print(shortcut.name)
print(shortcut.get_shape())
else:
shortcut = slim.conv2d(preact, depth, [1, 1], stride=stride,
normalizer_fn=None, activation_fn=None,
scope='shortcut')
print('identity route:')
print(shortcut.name)
print(shortcut.get_shape())
residual = slim.conv2d(preact, depth_bottleneck, [1, 1], stride=1,
scope='conv1')
print('residual convlution route:')
print(residual.name)
print(residual.get_shape())
residual = conv2d_same(residual, depth_bottleneck, 3, stride,
rate=rate, scope='conv2')
print(residual.name)
print(residual.get_shape())
residual = slim.conv2d(residual, depth, [1, 1], stride=1,
normalizer_fn=None, activation_fn=None,
scope='conv3')
print(residual.name)
print(residual.get_shape())
output = shortcut + residual
print(output.name)
print(output.get_shape())
return slim.utils.collect_named_outputs(outputs_collections,
sc.name,
output)===================> block4
unit: {'depth': 2048, 'depth_bottleneck': 512, 'stride': 1}
block4/unit_1/bottleneck_v2/preact/Relu:0
(1, 32, 32, 1024)
identity route:
block4/unit_1/bottleneck_v2/shortcut/BiasAdd:0
(1, 32, 32, 2048)
residual convlution route:
block4/unit_1/bottleneck_v2/conv1/Relu:0
(1, 32, 32, 512)
block4/unit_1/bottleneck_v2/conv2/Relu:0
(1, 32, 32, 512)
block4/unit_1/bottleneck_v2/conv3/BiasAdd:0
(1, 32, 32, 2048)
block4/unit_1/bottleneck_v2/add:0
(1, 32, 32, 2048)
dilates rate: 1
unit: {'depth': 2048, 'depth_bottleneck': 512, 'stride': 1}
block4/unit_2/bottleneck_v2/preact/Relu:0
(1, 32, 32, 2048)
identity route:
block4/unit_1/bottleneck_v2/add:0
(1, 32, 32, 2048)
residual convlution route:
block4/unit_2/bottleneck_v2/conv1/Relu:0
(1, 32, 32, 512)
block4/unit_2/bottleneck_v2/conv2/Relu:0
(1, 32, 32, 512)
block4/unit_2/bottleneck_v2/conv3/BiasAdd:0
(1, 32, 32, 2048)
block4/unit_2/bottleneck_v2/add:0
(1, 32, 32, 2048)
dilates rate: 2
unit: {'depth': 2048, 'depth_bottleneck': 512, 'stride': 1}
block4/unit_3/bottleneck_v2/preact/Relu:0
(1, 32, 32, 2048)
identity route:
block4/unit_2/bottleneck_v2/add:0
(1, 32, 32, 2048)
residual convlution route:
block4/unit_3/bottleneck_v2/conv1/Relu:0
(1, 32, 32, 512)
block4/unit_3/bottleneck_v2/conv2/Relu:0
(1, 32, 32, 512)
block4/unit_3/bottleneck_v2/conv3/BiasAdd:0
(1, 32, 32, 2048)
block4/unit_3/bottleneck_v2/add:0
(1, 32, 32, 2048)
dilates rate: 4
其中在con2层利用了扩张卷积,扩张率为1,2,4,对应卷积核大小分别为3×3,5×5,9×9。
tensor flow 依赖函数
tf.contrib.layers.conv2d(
inputs,
num_outputs,
kernel_size,
stride=1,
padding='SAME',
data_format=None,
rate=1,
activation_fn=tf.nn.relu,
normalizer_fn=None,
normalizer_params=None,
weights_initializer=initializers.xavier_initializer(),
weights_regularizer=None,
biases_initializer=tf.zeros_initializer(),
biases_regularizer=None,
reuse=None,
variables_collections=None,
outputs_collections=None,
trainable=True,
scope=None
)bias_initializer: An initializer for the bias vector. If None, the default initializer will be used.
tf.contrib.layers.max_pool2d(
inputs,
kernel_size,
stride=2,
padding='VALID',
data_format=DATA_FORMAT_NHWC,
outputs_collections=None,
scope=None
)