OpenCV3.0基本类型初探(三)MAT初探
在研究Mat之前,我们先来看下CV提供的一些小型Mat实现
Matx 用于表述规模较小的确定大小的矩阵,在模板定义的时候就确定了矩阵的规模,其定义如下:
template class Matx
数据存储实体如下:
_Tp val[m*n]; //< matrix elements
虽然没有动态分配内存的灵活性,Matx对于小型的矩阵却不失为一种加快运行速度的良好数据结构 CV也提供其和Mat之间的相互转换
其实质就是一个固定大小一维数组的封装
而其行列的定义是储存在一个枚举结构之中
all(alpha) 矩阵的所有元素填充为alpha值
zero() 矩阵所有元素填充为0
ones() 矩阵所有元素填充为1
eye() 矩阵较小维填充为对角为1的矩阵
即 矩阵定义为 3X4
运行eye操作后 得到
1 0 0 0
0 1 0 0
0 0 1 0
其定义如下
class CV_EXPORTS Mat
{
public:
// ... a lot of methods ...
...
/*! includes several bit-fields: - the magic signature - continuity flag - depth - number of channels */
int flags ;
//! the array dimensionality, >= 2
int dims ;
//! the number of rows and columns or (-1, -1) when the array has more than 2 dimensions
int rows , cols ;
//! pointer to the data
uchar * data ;
//! pointer to the reference counter;
// when array points to user-allocated data, the pointer is NULL
int * refcount ;
// other members ...
};
其表示一个N维的稠密单/复通道矩阵 ,可以用来存储实/复值向量和矩阵以及灰度/彩色图片、点云、张量乃至直方图。
..矩阵之间元素的距离是由步长变量step决定的,所以,对矩阵中单个元素的地址,其计算公式为:
![addr(M_{i_0,...,i_{M.dims-1}}) = M.data + M.step[0]*i_0 + M.step[1]*i_1 + ... + M.step[M.dims-1]*i_{M.dims-1}](http://img.e-com-net.com/image/info8/35862a931347425b97bcf4028f2111b5.jpg)
在二维向量中 计算公式被简化为:
![addr(M_{i,j}) = M.data + M.step[0]*i + M.step[1]*j](http://img.e-com-net.com/image/info8/0bfcd01c275c46509d9dc70aec07d3d9.png)
更详细的理解 可以参考这个帖子
http://www.douban.com/note/265479171/
下面我们来讨论Mat在创建和复制时的内存分配行为:
以一个常用的创建方法create为例子
当我们输入
Mat mat;
mat.create(3,2,CV_8U);
时,尽管有多个参数的重载,最终函数都会被指向
void create(int ndims, const int* sizes, int type);
这个函数。其在分配内存初期会进行一个检查,如果矩阵的数据不为空且新矩阵的规模和格式与原矩阵相同,将不做任何操作退回
如果需要创建一个新矩阵的内存空间,系统会调用MatAllocator类作为分配符进行内存的分配。
但是MatAllocator是一个虚基类,其具体实现有如下三种
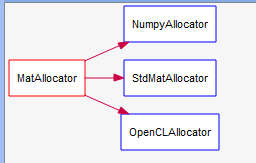
在C++的实现中,一般调用的就是stdMaltAllocator
分配代码如下
case3:创建过程
Mat在创建时,如果进行了分配数据的操作,会主动调用addref方法,将refcount+1
如果没有进行数据分配,refcount则仍为0
最后 让我们来看看CV_XADD的展开
其实质就是在进行一个线程安全的加减法 用于在多线程操作中安全增减refcount的数目
小实验:
Mat a;
Mat b;
int size[]= { 356 , 367 , 311 };
a.create( 3 ,size, CV_32FC3 );
std ::cout<
u
->
refcount
<<
std
::endl;
b=a;
std ::cout<
u
->
refcount
<<
"
"
<
u
->
refcount
<<
std
::endl;
a.release();
std :: cout << b . u -> refcount << std :: endl ;
输出:
1
Matx
Matx定义于matx.hpp中 继承关系如图
Matx 用于表述规模较小的确定大小的矩阵,在模板定义的时候就确定了矩阵的规模,其定义如下:
template
数据存储实体如下:
_Tp val[m*n]; //< matrix elements
虽然没有动态分配内存的灵活性,Matx对于小型的矩阵却不失为一种加快运行速度的良好数据结构 CV也提供其和Mat之间的相互转换
其实质就是一个固定大小一维数组的封装
而其行列的定义是储存在一个枚举结构之中
enum { depth = DataType<_Tp>::depth,
rows = m,
cols = n,
channels = rows*cols,
type = CV_MAKETYPE(depth, channels),
shortdim = (m < n ? m : n)
};
其中depth深度即表示每个元素所占有的位数 并且和符号相关
enum { CV_8U=0, CV_8S=1, CV_16U=2, CV_16S=3, CV_32S=4, CV_32F=5, CV_64F=6 }; 可见 0和1都代表8位, 2和3都代表16位,4和5代表32位,6代表64位;
ros.cols代表行列数
channels代表通道数 即矩阵中每个元素拥有元素值的个数
在常见的RGB或者HSV图像中 通道数为3
在Matx中 整个矩阵被认为是一个独立元素,所以其通道数为其包含元素个数
type和之前介绍的一样,为了类型安全而标注的类型编号
shortdim 矩阵较小的维度 而另一个额较大的数字会被认为是数据样本个数
其与其他矩阵类一样,也提供诸如
其中depth深度即表示每个元素所占有的位数 并且和符号相关
enum { CV_8U=0, CV_8S=1, CV_16U=2, CV_16S=3, CV_32S=4, CV_32F=5, CV_64F=6 }; 可见 0和1都代表8位, 2和3都代表16位,4和5代表32位,6代表64位;
ros.cols代表行列数
channels代表通道数 即矩阵中每个元素拥有元素值的个数
在常见的RGB或者HSV图像中 通道数为3
在Matx中 整个矩阵被认为是一个独立元素,所以其通道数为其包含元素个数
type和之前介绍的一样,为了类型安全而标注的类型编号
shortdim 矩阵较小的维度 而另一个额较大的数字会被认为是数据样本个数
all(alpha) 矩阵的所有元素填充为alpha值
zero() 矩阵所有元素填充为0
ones() 矩阵所有元素填充为1
eye() 矩阵较小维填充为对角为1的矩阵
即 矩阵定义为 3X4
运行eye操作后 得到
1 0 0 0
0 1 0 0
0 0 1 0
Mat
Mat型可以说是CV最常用的类型其定义如下
class CV_EXPORTS Mat
{
public:
// ... a lot of methods ...
...
/*! includes several bit-fields: - the magic signature - continuity flag - depth - number of channels */
int flags ;
//! the array dimensionality, >= 2
int dims ;
//! the number of rows and columns or (-1, -1) when the array has more than 2 dimensions
int rows , cols ;
//! pointer to the data
uchar * data ;
//! pointer to the reference counter;
// when array points to user-allocated data, the pointer is NULL
int * refcount ;
// other members ...
};
其表示一个N维的稠密单/复通道矩阵 ,可以用来存储实/复值向量和矩阵以及灰度/彩色图片、点云、张量乃至直方图。
..矩阵之间元素的距离是由步长变量step决定的,所以,对矩阵中单个元素的地址,其计算公式为:
在二维向量中 计算公式被简化为:
更详细的理解 可以参考这个帖子
http://www.douban.com/note/265479171/
下面我们来讨论Mat在创建和复制时的内存分配行为:
以一个常用的创建方法create为例子
当我们输入
Mat mat;
mat.create(3,2,CV_8U);
时,尽管有多个参数的重载,最终函数都会被指向
void create(int ndims, const int* sizes, int type);
这个函数。其在分配内存初期会进行一个检查,如果矩阵的数据不为空且新矩阵的规模和格式与原矩阵相同,将不做任何操作退回
如果需要创建一个新矩阵的内存空间,系统会调用MatAllocator类作为分配符进行内存的分配。
但是MatAllocator是一个虚基类,其具体实现有如下三种
在C++的实现中,一般调用的就是stdMaltAllocator
分配代码如下
UMatData* allocate(int dims, const int* sizes, int type,
void* data0, size_t* step, int /*flags*/, UMatUsageFlags /*usageFlags*/) const
{
size_t total = CV_ELEM_SIZE(type);
for( int i = dims-1; i >= 0; i-- )
{
if( step )
{
if( data0 && step[i] != CV_AUTOSTEP )
{
CV_Assert(total <= step[i]);
total = step[i];
}
else
step[i] = total;
}
total *= sizes[i];
}
uchar* data = data0 ? (uchar*)data0 : (uchar*)fastMalloc(total);
UMatData* u = new UMatData(this);
u->data = u->origdata = data;
u->size = total;
if(data0)
u->flags |= UMatData::USER_ALLOCATED;
return u;
}
展开CV_ELEMENSIZE 得到
可以印证 STEP并不是一定等于DIM原始大小所占的空间
做个小实验:
Mat a;
int size[]= { 356, 367, 311};
a.create( 3,size, CV_32FC3);
int i;
for(i= 0;idims;i++)
std::cout<step[i]<<
std::endl;
输出
综上 create操作一般会申请最大的step所占空间的字节数
但是 这样并没有体现出任何自动内存管理的特点 模拟sharedPTR的机制又在哪里体现的呢
再看Mat类中数据实体UMatData的定义 有一个refCount的定义
int refcount;
我们来看看究竟有哪些情况会修改到refcount的数量
case1:浅复制过程
Mat::Mat(const Mat& m)调用的时候
如果原有的mat是有数据的, 调用 CV_XADD(&u->refcount, 1); refcount+1
其实这样的复制过程也就是一次浅拷贝的过程
同样是浅拷贝过程的还有重载的运算符=
case2:释放过程
主动调用release方法的时候,程序会对refcount做一次检查
在对象析构的时候,也会主动调用release方法,其步骤如上
展开CV_ELEMENSIZE 得到
/* 0x3a50 = 11 10 10 01 01 00 00 ~ array of log2(sizeof(arr_type_elem)) */
#define CV_ELEM_SIZE(type) \
(CV_MAT_CN(type) << ((((sizeof(size_t)/4+1)*16384|0x3a50) >> CV_MAT_DEPTH(type)*2) & 3))
可以印证 STEP并不是一定等于DIM原始大小所占的空间
做个小实验:
Mat a;
int size[]= { 356, 367, 311};
a.create( 3,size, CV_32FC3);
int i;
for(i= 0;i
std::cout<
输出
1369644
3732
12
尽管没有详细的判断,但是一般来说step还是等于dim原占有的空间的综上 create操作一般会申请最大的step所占空间的字节数
但是 这样并没有体现出任何自动内存管理的特点 模拟sharedPTR的机制又在哪里体现的呢
再看Mat类中数据实体UMatData的定义 有一个refCount的定义
int refcount;
我们来看看究竟有哪些情况会修改到refcount的数量
case1:浅复制过程
Mat::Mat(const Mat& m)调用的时候
如果原有的mat是有数据的, 调用 CV_XADD(&u->refcount, 1); refcount+1
其实这样的复制过程也就是一次浅拷贝的过程
同样是浅拷贝过程的还有重载的运算符=
case2:释放过程
主动调用release方法的时候,程序会对refcount做一次检查
if( u && CV_XADD(&u->refcount, -1) == 1 )
deallocate();
只有在refcount减一之后为1时,才会调用deallocate
case3:创建过程
Mat在创建时,如果进行了分配数据的操作,会主动调用addref方法,将refcount+1
如果没有进行数据分配,refcount则仍为0
最后 让我们来看看CV_XADD的展开
#if defined __INTEL_COMPILER && !(defined WIN32 || defined _WIN32)
// atomic increment on the linux version of the Intel(tm) compiler
# define CV_XADD(addr, delta) (int)_InterlockedExchangeAdd(const_cast(reinterpret_cast(addr)), delta)
#elif defined __GNUC__
# if defined __clang__ && __clang_major__ >= 3 && !defined __ANDROID__ && !defined __EMSCRIPTEN__ && !defined(__CUDACC__)
# ifdef __ATOMIC_ACQ_REL
# define CV_XADD(addr, delta) __c11_atomic_fetch_add((_Atomic(int)*)(addr), delta, __ATOMIC_ACQ_REL)
# else
# define CV_XADD(addr, delta) __atomic_fetch_add((_Atomic(int)*)(addr), delta, 4)
# endif
# else
# if defined __ATOMIC_ACQ_REL && !defined __clang__
// version for gcc >= 4.7
# define CV_XADD(addr, delta) (int)__atomic_fetch_add((unsigned*)(addr), (unsigned)(delta), __ATOMIC_ACQ_REL)
# else
# define CV_XADD(addr, delta) (int)__sync_fetch_and_add((unsigned*)(addr), (unsigned)(delta))
# endif
# endif
#elif defined _MSC_VER && !defined RC_INVOKED
# include
# define CV_XADD(addr, delta) (int)_InterlockedExchangeAdd((long volatile*)addr, delta)
#else
CV_INLINE CV_XADD(int* addr, int delta) { int tmp = *addr; *addr += delta; return tmp; }
#endif
其实质就是在进行一个线程安全的加减法 用于在多线程操作中安全增减refcount的数目
小实验:
Mat a;
Mat b;
int size[]= { 356 , 367 , 311 };
a.create( 3 ,size, CV_32FC3 );
std ::cout<
b=a;
std ::cout<
a.release();
std :: cout << b . u -> refcount << std :: endl ;
输出:
1
2 2
1