集体智慧编程第二章之提供推荐
本章主要介绍了利用协作型算法对项目进行推荐,这里的项目可以是商品,电影,音乐。一个协作型算法的关键是对一大群人进行搜索,从中找出与我们品味最相似的一群人,算法会对这些人的所偏好的内容进行考查,并将它们组合起来构造出一个经过排名的推荐列表。本文主要通过一个电影推荐的例子完成这个过程。
1.搜集偏好
在实际中,用户对项目的偏好往往是以打分,评论,收藏标签,点击等方式体现,可以用数字值将这些行为进行具体化,比如说打分可以由1-5的区别,收藏标签可以由0和1之分。所以进行推荐的第一步是要收集用户的喜好数据,在这里用一个字典来保存用户的历史喜好数据。
critics = {
'Lisa Rose': {
'Lady in the Water': 2.5,
'Snakes on a Plane': 3.5,
'Just My Luck': 3.0,
'Superman Returns': 3.5,
'You, Me and Dupree': 2.5,
'The Night Listener': 3.0,
},
'Gene Seymour': {
'Lady in the Water': 3.0,
'Snakes on a Plane': 3.5,
'Just My Luck': 1.5,
'Superman Returns': 5.0,
'The Night Listener': 3.0,
'You, Me and Dupree': 3.5,
},
'Michael Phillips': {
'Lady in the Water': 2.5,
'Snakes on a Plane': 3.0,
'Superman Returns': 3.5,
'The Night Listener': 4.0,
},
'Claudia Puig': {
'Snakes on a Plane': 3.5,
'Just My Luck': 3.0,
'The Night Listener': 4.5,
'Superman Returns': 4.0,
'You, Me and Dupree': 2.5,
},
'Mick LaSalle': {
'Lady in the Water': 3.0,
'Snakes on a Plane': 4.0,
'Just My Luck': 2.0,
'Superman Returns': 3.0,
'The Night Listener': 3.0,
'You, Me and Dupree': 2.0,
},
'Jack Matthews': {
'Lady in the Water': 3.0,
'Snakes on a Plane': 4.0,
'The Night Listener': 3.0,
'Superman Returns': 5.0,
'You, Me and Dupree': 3.5,
},
'Toby': {'Snakes on a Plane': 4.5, 'You, Me and Dupree': 1.0,
'Superman Returns': 4.0},
}2.计算用户相似度
在搜集完成用户的喜好之后,必须有一种方法来判断用户之间的相似度的算法,人以类聚,物与群分,找到与指定的用户相似的用户是推荐的基础。实际中用到的相似度计算法方法主要有欧几里得距离和皮尔逊相关系数。
欧几里得距离
欧几里得距离就是计算两个向量之间的距离,这里可以把用户对每一部电影的评分看作是一个向量,然后计算两个向量之间的距离。用一个简单的二维图示表示如下:
这里的横坐标和纵坐标分别表示一部电影,这样就可以将所有的用户置于这样的一个电影空间中,这个只是二维的情况,多不电影的话就对应的是一个多维的空间。利用欧几里得距离计算用户之间的相似度的过程如下所示:
利用欧几里得距离来测量用户之间的相似度
#prefs: 用户偏好
#p1,p2: 不同的用户
#返回用户之间的相似度
def sim_distance(prefs,p1,p2):
si={}
for item in prefs[p1]: #遍历用户p1和p2,找到二者共有的项目
if item in prefs[p2]:
si[item]=1
if len(si)==1:
return 0
#计算二者之间的欧几里得距离
sum_of_squares=sum([pow(prefs[p1][item]-prefs[p2][item],2) for item in
prefs[p1] if item in prefs[p2]])
return 1/(1+sqrt(sum_of_squares))皮尔逊相关度评价
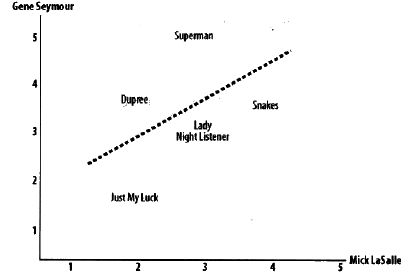
皮尔逊相关系数是判断一组数据和一条直线之间拟合程度的一宗度量,在数据很不规范的时候会给出更好的结果。如下图所示,横纵坐标表示两个用户,坐标点表示的是用户对电影的评分,这样二者都评分的电影都在一个平面内了,组成了这样的散点图,现在用一条直线去拟合这些散点图,如果两个用户之间越相似,那么这些散点就越能拟合到一条直线上。
皮尔逊相关系数的计算公式如下:
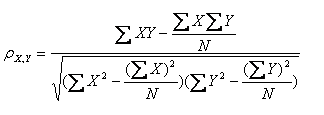
相关系数的取值范围的-1到1之间,-1表示二者负相关,1表示二者正相关,0 表示二者不相关,皮尔逊相关度评价首先找出二者都评价过的物品,然后计算评分的总和和平方和,并求得评分的乘积之和。计算过程如下所示:
#利用皮尔逊相关系数来计算用户之间的相似度
#prefs: 用户偏好
#p1,p2: 不同的用户
#返回用户之间的相似度
def sim_person(prefs,p1,p2):
si={}
for item in prefs[p1]:
if item in prefs[p2]:
si[item]=1
if len(si)==0:
return 0
n=len(si)
#计算二者公共项目评分的总和
sum1=sum([prefs[p1][it] for it in si])
sum2=sum([prefs[p2][it] for it in si])
#计算二者公共项目评分的平方和
sum1sq=sum([pow(prefs[p1][it],2) for it in si])
sum2sq=sum([pow(prefs[p2][it],2) for it in si])
#计算二者评分的乘积之和
psum=sum([prefs[p1][it]*prefs[p2][it] for it in si])
#分子
num=psum-sum1*sum2/n
#分母
den=sqrt((sum1sq-pow(sum1,2)/n)*(sum2sq-pow(sum2,2)/n))
if den==0:
return 0
return num/den计算出一对用户之间的相似度之后,就可以通过遍历所有的用户,找出某一个用户相似度最高的前k个用户,计算相似度,排序即可。
#求取指定用户相似度最高的前n个用户
def topMatches(prefs,person,n=5,similarity=sim_person):
scores=[(similarity(prefs,person,other),other)for other in prefs if other!=person]
scores.sort()
scores.reverse()
return scores[0:n]找出与制定用户之间相似度最高的k个用户之后,当然可以把这前k个用户的所有电影前部推荐给用户,但是注意到这些用户之间的相似度是不一样的,所以我们要对每一部电影计算一个推荐度,通过一个经过加权的评价值来为影片打分,用相似度乘以对每一部影片的打分得到推荐度。
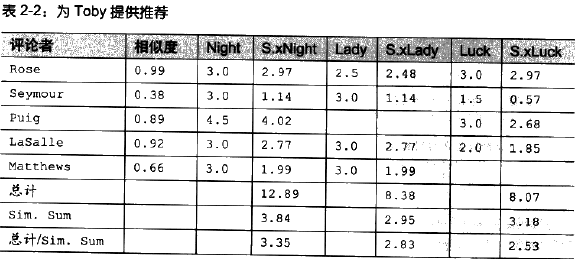
如图所示,每一个用户与Toby之间的相似度乘以他们对电影的评分,最后得到一个推荐值,将这些推荐值相加和再除以所有用户的相似度之和就得到了最后的推荐度。具体实现过程如下:
#根据用户之间的相似度进行物品推荐
def getRecommendations(prefs,person,similarity=sim_person):
totals={}
simSums={}
for other in prefs:
if other==person: #与自己不做比较
continue
sim=similarity(prefs,person,other) #与每一个用户计算相似度
if sim<=0:
continue
for item in prefs[other]:
#只对自己还没有看过的项目进行推荐
if item not in prefs[person] or prefs[person][item]==0:
totals.setdefault(item,0)
#计算最终的item的推荐指数
totals[item]+=prefs[other][item]*sim
#最终的左右相似度之和
simSums.setdefault(item,0)
simSums[item]+=sim
#建立一个归一化的列表
rankings=[(total/simSums[item],item) for (item,total) in totals.items()]
rankings.sort()
rankings.reverse()
return rankings![]()
5.在MovieLens数据集上进行推荐
下载MovieLens数据集,其中用到的文件有u.item和u.data两个文件,u.item中主要包含了电影的具体详细,u.data中包含了用户对电影的评分,首先需要将u.item文件读取到字典中。
#利用真实的电影数据集进行推荐
def loadMovieLens(path):
movies={}
for line in open(path+'/u.item',encoding='utf-8'):
(id,title)=line.split('|')[0:2]
movies[id]=title
prefs={}
for line in open(path+'/u.data',encoding='utf-8'):
(user,movieid,rating,ts)=line.split('\t')
prefs.setdefault(user,{})
prefs[user][movies[movieid]]=float(rating)
return prefs
![]()