【OpenVswitch源码分析之五】用户空间转发面数据结构与流程
传统交换机是基于MAC表进行转发的,所以OVS也支持MAC学习特性,但是由于OVS也支持Openflow协议作为控制面,其功能就不仅仅是一个二层交换机了。
先简单谈谈Openflow
由于现在的网络暴露出了越来越多的弊病以及人们对网络性能需求的提高,于是研究人员不得不把很多复杂功能加入到路由器的体系结构当中,例如OSPF,BGP,组播,区分服务,流量工程,NAT,防火墙,MPLS等等。这就使得路由器等交换设备越来越臃肿而且性能提升的空间越来越小。
然而与网络领域的困境截然不同的是,计算机领域实现了日新月异的发展。仔细回顾计算机领域的发展,不难发现其关键在于计算机领域找到了一个简单可用的硬件底层(x86指令集)。由于有了这样一个公用的硬件底层,所以在软件方面,不论是应用程序还是操作系统都取得了飞速的发展。很多主张重新设计计算机网络体系结构的人士认为:网络可以复制计算机领域的成功经验来解决现在网络所遇到的所有问题。在这种思想的指导下,将来的网络必将是这样的:底层的数据通路(交换机、路由器)是“哑的、简单的、最小的”,并定义一个对外开放的关于流表的公用的API,同时采用控制器来控制整个网络。未来的研究人员就可以在控制器上自由的调用底层的API来编程,从而实现网络的创新。
OpenFlow正是这种网络创新思想的强有力的推动者。OpenFlow交换机将原来完全由交换机/路由器控制的报文转发过程转化为由OpenFlow交换机(OpenFlow Switch)和控制服务器(Controller)来共同完成,从而实现了数据转发和路由控制的分离。控制器可以通过事先规定好的接口操作来控制OpenFlow交换机中的流表,从而达到控制数据转发的目的。
在Openflow的设计中,其匹配项除了二层的eth_src, eth_dst, eth_type, vlan 等的匹配外,还有三层的源目的IP,IP协议类型,的匹配,甚至于还有四层的端口号的匹配等,所以在Openflow和控制器的支持下,OVS已经不仅仅是一个二层交换机。
Openflow相关接口一览
static enum ofperr
ofproto_flow_mod_start(struct ofproto *ofproto, struct ofproto_flow_mod *ofm)
OVS_REQUIRES(ofproto_mutex)
{
enum ofperr error;
rule_collection_init(&ofm->old_rules);
rule_collection_init(&ofm->new_rules);
switch (ofm->command) {
case OFPFC_ADD:
error = add_flow_start(ofproto, ofm);
break;
case OFPFC_MODIFY:
error = modify_flows_start_loose(ofproto, ofm);
break;
case OFPFC_MODIFY_STRICT:
error = modify_flow_start_strict(ofproto, ofm);
break;
case OFPFC_DELETE:
error = delete_flows_start_loose(ofproto, ofm);
break;
case OFPFC_DELETE_STRICT:
error = delete_flow_start_strict(ofproto, ofm);
break;
default:
OVS_NOT_REACHED();
}
/* Release resources not needed after start. */
ofproto_flow_mod_uninit(ofm);
if (error) {
rule_collection_destroy(&ofm->old_rules);
rule_collection_destroy(&ofm->new_rules);
}
return error;
}Ofproto模块会收到flow_mod消息,无论是控制器发出还是命令行客户端添加流表,都会调用这个函数,OVS对收到的流表会保存在用户空间的oftable数据结构中,接下来就是整个OpenVswitch的核心,在用户空间对内核态上送的报文寻找匹配的Flow Entry。
相关数据结构和优化一览
数据结构和算法的设计上有几个难点:
- Openflow过于灵活的匹配规则对Pipe的实现提出了挑战,其rule包括metadata,L2,L3,L4的匹配项,可能都分布在一张表中,另外还有优先级的考虑
- 在并发的情况下,如何保障表项的修改,增加和删除对最终结果没有影响
- 如何保障高性能
最终OpenVswitch设计了一个复杂的数据结构和保障机制来达到上述要求

上图是用户空间各个核心数据结构的关系,其核心数据结构式Classifier,Pipeline里的每个Table对应一个Classifier,Classifier把整张表里的各个rule进行了分类分成了不同的subtable,每个subtable有自己的掩码,这个掩码表示这个subtable里的rule要匹配的掩码。很显然,这种分类并不能提高匹配效率,这个数据结构还做了不少优化策略:
- subtable之间还做了优先级排序,需要优先级向量来标识。这样的话从高优先级的subtable先开始,一旦匹配就可以跳过不少低优先级的subtable。
- 分阶段匹配,对于一个subtable还可以再继续拆分多个hashtable,因为如果某个subtabl同时要匹配的项比较多,包含了metadata,L2, L3,L4的匹配项,那么就按这四个子类来分,第一阶段先匹配metadata;然后再匹配metadata,L2;继续metadata,L2,L3;最后才是metadata,L2,L3,L4。对于能匹配的rule其实并不能增加效率,但是对于不匹配的情况却是可以增加很大效率。
- 前缀追踪,前缀跟踪允许分类器跳过比必要的前缀更长的rule,从而为数据流更好的通配符。当流表包含具有不同前缀长度的IP地址字段匹配项时,前缀跟踪可能是有益的。例如,当一个流表中包含一个完整的IP地址匹配和一个地址前缀匹配,完整的地址匹配通常会导致此表的该字段非通配符全0(取决于rule优先级)。在这种情况下,每个有不同的地址的数据包只能被交给用户空间处理并生成自己的数据流。在前缀跟踪启用后用户空间会为问题Packet生成更短的前缀地址匹配,而把无关的地址位置成通配,可以使用一个rule来处理所有的问题包。在这种情况下,可以避免许多的用户上调,这样整体性能可以更好。当然这仅仅是性能优化,因为不管是否有前缀跟踪数据包将得到相同的处理。另外前缀跟踪是可以和分阶段匹配配套使用,Trie树会追踪整个Classifier中所有Rule的地址前缀的数量。更神奇的是通过维护一个在Trie树遍历中遇到的最长前缀的列表或者维护通过不同Metadata分开的规则子集独立的Trie树可以实现表跳跃。前缀追踪是通过OVSDB“Flow_Table”表”fieldspec” 列来配置的,”fieldspec” 列是用string map这里前缀的key值告诉哪些字段可以被用来做前缀追踪。
并发的支持
很显然,出于对性能的考虑,对Pipeline的并发的支持是必须的,而且在转发的场景下,相对而言会是一个reader多writer少的一个场景,针对这种场景,OVS采用了类似于悲观锁的版本控制机制和Linux RCU机制的保护,下面分别对两者进行介绍:
基于版本的并发的支持
Classifier检索总是在一个特定的版本上进行的,这个版本号是一个自然数。当一个新的Rule被添加到Classifier之后,它会被设置为在一个特定的版本号上可见。如果这个插入时的版本号比当前检索的时候的版本号要大,那么它暂时是不可见的。这意味着检索不会发现这个rule,但是rule会在Classifier迭代之后马上可见。
类似的,一条rule可以被在将来的某个版本删除。在当前的检索没有完成之前,rule是不允许被删除的,首先第一步应该把rule设置为不可见,之后当用来检索的Classifier的版本号已经大于删除版本号时再实际上把这个rule删除掉
Classifier 支持版本的两个原因:
支持基于版本的修改使得对Classifier的修改具备原子特征,不同版本间的中间状态是对外不可见的。同时,当一个rule被添加到未来的版本里,这些修改可以回退掉且不会对当前的检索产生任何影响
性能:添加或删除一个rule集合,其性能的影响和Classifier已有的rule数量成正比。当多个rule一口气添加上之后,只要整批的rule修改还没有完成之前不可见,那么这种影响其实是可以避免。
Linux RCU机制
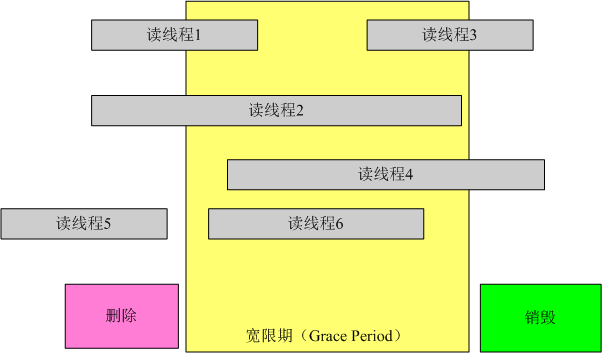
RCU(Read-Copy Update),顾名思义就是读-拷贝修改,它是基于其原理命名的。对于被RCU保护的共享数据结构,读者不需要获得任何锁就可以访问它,但写者在访问它时首先拷贝一个副本,然后对副本进行修改,最后使用一个回调(callback)机制在适当的时机把指向原来数据的指针重新指向新的被修改的数据。这个时机就是所有引用该数据的CPU都退出对共享数据的操作。
长图以删除为例,在做删除操作后起始并没有把数据销毁掉,而是等待已经读取该数据的线程出读临界区之后再做销毁工作,这段时间叫宽限期,而在这段时间内新来的线程则可以读取最新修改的值。
但是注意到RCU机制和版本控制机制是同时使用的,由于Classifier rule是RCU保护的,Rule的销毁在执行remove操作之后必须是RCU推迟的。同时,当版本特性也在使用时,remove操作自身也必须是RCU推迟的(此时的删除必须等待到指定的版本之后)。在这种情形下rule的删除就经理了两次RCU推迟。 比如,第二次调用ovsrcu_postpone() 来销毁Rule就是在第一次RCU回调执行remove操作的时候调用的
用户态转发的核心都在Classifier里,这里也会附加Classifier的详细解释,读者可以自行体会。
/* Flow classifier.
*
*
* What?
* =====
*
* A flow classifier holds any number of "rules", each of which specifies
* values to match for some fields or subfields and a priority. Each OpenFlow
* table is implemented as a flow classifier.
*
* The classifier has two primary design goals. The first is obvious: given a
* set of packet headers, as quickly as possible find the highest-priority rule
* that matches those headers. The following section describes the second
* goal.
*
*
* "Un-wildcarding"
* ================
*
* A primary goal of the flow classifier is to produce, as a side effect of a
* packet lookup, a wildcard mask that indicates which bits of the packet
* headers were essential to the classification result. Ideally, a 1-bit in
* any position of this mask means that, if the corresponding bit in the packet
* header were flipped, then the classification result might change. A 0-bit
* means that changing the packet header bit would have no effect. Thus, the
* wildcarded bits are the ones that played no role in the classification
* decision.
*
* Such a wildcard mask is useful with datapaths that support installing flows
* that wildcard fields or subfields. If an OpenFlow lookup for a TCP flow
* does not actually look at the TCP source or destination ports, for example,
* then the switch may install into the datapath a flow that wildcards the port
* numbers, which in turn allows the datapath to handle packets that arrive for
* other TCP source or destination ports without additional help from
* ovs-vswitchd. This is useful for the Open vSwitch software and,
* potentially, for ASIC-based switches as well.
*
* Some properties of the wildcard mask:
*
* - "False 1-bits" are acceptable, that is, setting a bit in the wildcard
* mask to 1 will never cause a packet to be forwarded the wrong way.
* As a corollary, a wildcard mask composed of all 1-bits will always
* yield correct (but often needlessly inefficient) behavior.
*
* - "False 0-bits" can cause problems, so they must be avoided. In the
* extreme case, a mask of all 0-bits is only correct if the classifier
* contains only a single flow that matches all packets.
*
* - 0-bits are desirable because they allow the datapath to act more
* autonomously, relying less on ovs-vswitchd to process flow setups,
* thereby improving performance.
*
* - We don't know a good way to generate wildcard masks with the maximum
* (correct) number of 0-bits. We use various approximations, described
* in later sections.
*
* - Wildcard masks for lookups in a given classifier yield a
* non-overlapping set of rules. More specifically:
*
* Consider an classifier C1 filled with an arbitrary collection of rules
* and an empty classifier C2. Now take a set of packet headers H and
* look it up in C1, yielding a highest-priority matching rule R1 and
* wildcard mask M. Form a new classifier rule R2 out of packet headers
* H and mask M, and add R2 to C2 with a fixed priority. If one were to
* do this for every possible set of packet headers H, then this
* process would not attempt to add any overlapping rules to C2, that is,
* any packet lookup using the rules generated by this process matches at
* most one rule in C2.
*
* During the lookup process, the classifier starts out with a wildcard mask
* that is all 0-bits, that is, fully wildcarded. As lookup proceeds, each
* step tends to add constraints to the wildcard mask, that is, change
* wildcarded 0-bits into exact-match 1-bits. We call this "un-wildcarding".
* A lookup step that examines a particular field must un-wildcard that field.
* In general, un-wildcarding is necessary for correctness but undesirable for
* performance.
*
*
* Basic Classifier Design
* =======================
*
* Suppose that all the rules in a classifier had the same form. For example,
* suppose that they all matched on the source and destination Ethernet address
* and wildcarded all the other fields. Then the obvious way to implement a
* classifier would be a hash table on the source and destination Ethernet
* addresses. If new classification rules came along with a different form,
* you could add a second hash table that hashed on the fields matched in those
* rules. With two hash tables, you look up a given flow in each hash table.
* If there are no matches, the classifier didn't contain a match; if you find
* a match in one of them, that's the result; if you find a match in both of
* them, then the result is the rule with the higher priority.
*
* This is how the classifier works. In a "struct classifier", each form of
* "struct cls_rule" present (based on its ->match.mask) goes into a separate
* "struct cls_subtable". A lookup does a hash lookup in every "struct
* cls_subtable" in the classifier and tracks the highest-priority match that
* it finds. The subtables are kept in a descending priority order according
* to the highest priority rule in each subtable, which allows lookup to skip
* over subtables that can't possibly have a higher-priority match than already
* found. Eliminating lookups through priority ordering aids both classifier
* primary design goals: skipping lookups saves time and avoids un-wildcarding
* fields that those lookups would have examined.
*
* One detail: a classifier can contain multiple rules that are identical other
* than their priority. When this happens, only the highest priority rule out
* of a group of otherwise identical rules is stored directly in the "struct
* cls_subtable", with the other almost-identical rules chained off a linked
* list inside that highest-priority rule.
*
* The following sub-sections describe various optimizations over this simple
* approach.
*
*
* Staged Lookup (Wildcard Optimization)
* -------------------------------------
*
* Subtable lookup is performed in ranges defined for struct flow, starting
* from metadata (registers, in_port, etc.), then L2 header, L3, and finally
* L4 ports. Whenever it is found that there are no matches in the current
* subtable, the rest of the subtable can be skipped.
*
* Staged lookup does not reduce lookup time, and it may increase it, because
* it changes a single hash table lookup into multiple hash table lookups.
* It reduces un-wildcarding significantly in important use cases.
*
*
* Prefix Tracking (Wildcard Optimization)
* ---------------------------------------
*
* Classifier uses prefix trees ("tries") for tracking the used
* address space, enabling skipping classifier tables containing
* longer masks than necessary for the given address. This reduces
* un-wildcarding for datapath flows in parts of the address space
* without host routes, but consulting extra data structures (the
* tries) may slightly increase lookup time.
*
* Trie lookup is interwoven with staged lookup, so that a trie is
* searched only when the configured trie field becomes relevant for
* the lookup. The trie lookup results are retained so that each trie
* is checked at most once for each classifier lookup.
*
* This implementation tracks the number of rules at each address
* prefix for the whole classifier. More aggressive table skipping
* would be possible by maintaining lists of tables that have prefixes
* at the lengths encountered on tree traversal, or by maintaining
* separate tries for subsets of rules separated by metadata fields.
*
* Prefix tracking is configured via OVSDB "Flow_Table" table,
* "fieldspec" column. "fieldspec" is a string map where a "prefix"
* key tells which fields should be used for prefix tracking. The
* value of the "prefix" key is a comma separated list of field names.
*
* There is a maximum number of fields that can be enabled for any one
* flow table. Currently this limit is 3.
*
*
* Partitioning (Lookup Time and Wildcard Optimization)
* ----------------------------------------------------
*
* Suppose that a given classifier is being used to handle multiple stages in a
* pipeline using "resubmit", with metadata (that is, the OpenFlow 1.1+ field
* named "metadata") distinguishing between the different stages. For example,
* metadata value 1 might identify ingress rules, metadata value 2 might
* identify ACLs, and metadata value 3 might identify egress rules. Such a
* classifier is essentially partitioned into multiple sub-classifiers on the
* basis of the metadata value.
*
* The classifier has a special optimization to speed up matching in this
* scenario:
*
* - Each cls_subtable that matches on metadata gets a tag derived from the
* subtable's mask, so that it is likely that each subtable has a unique
* tag. (Duplicate tags have a performance cost but do not affect
* correctness.)
*
* - For each metadata value matched by any cls_rule, the classifier
* constructs a "struct cls_partition" indexed by the metadata value.
* The cls_partition has a 'tags' member whose value is the bitwise-OR of
* the tags of each cls_subtable that contains any rule that matches on
* the cls_partition's metadata value. In other words, struct
* cls_partition associates metadata values with subtables that need to
* be checked with flows with that specific metadata value.
*
* Thus, a flow lookup can start by looking up the partition associated with
* the flow's metadata, and then skip over any cls_subtable whose 'tag' does
* not intersect the partition's 'tags'. (The flow must also be looked up in
* any cls_subtable that doesn't match on metadata. We handle that by giving
* any such cls_subtable TAG_ALL as its 'tags' so that it matches any tag.)
*
* Partitioning saves lookup time by reducing the number of subtable lookups.
* Each eliminated subtable lookup also reduces the amount of un-wildcarding.
*
*
* Classifier Versioning
* =====================
*
* Classifier lookups are always done in a specific classifier version, where
* a version is defined to be a natural number.
*
* When a new rule is added to a classifier, it is set to become visible in a
* specific version. If the version number used at insert time is larger than
* any version number currently used in lookups, the new rule is said to be
* invisible to lookups. This means that lookups won't find the rule, but the
* rule is immediately available to classifier iterations.
*
* Similarly, a rule can be marked as to be deleted in a future version. To
* delete a rule in a way to not remove the rule before all ongoing lookups are
* finished, the rule should be made invisible in a specific version number.
* Then, when all the lookups use a later version number, the rule can be
* actually removed from the classifier.
*
* Classifiers can hold duplicate rules (rules with the same match criteria and
* priority) when at most one of these duplicates is visible in any given
* lookup version. The caller responsible for classifier modifications must
* maintain this invariant.
*
* The classifier supports versioning for two reasons:
*
* 1. Support for versioned modifications makes it possible to perform an
* arbitraty series of classifier changes as one atomic transaction,
* where intermediate versions of the classifier are not visible to any
* lookups. Also, when a rule is added for a future version, or marked
* for removal after the current version, such modifications can be
* reverted without any visible effects to any of the current lookups.
*
* 2. Performance: Adding (or deleting) a large set of rules can, in
* pathological cases, have a cost proportional to the number of rules
* already in the classifier. When multiple rules are being added (or
* deleted) in one go, though, this pathological case cost can be
* typically avoided, as long as it is OK for any new rules to be
* invisible until the batch change is complete.
*
* Note that the classifier_replace() function replaces a rule immediately, and
* is therefore not safe to use with versioning. It is still available for the
* users that do not use versioning.
*
*
* Deferred Publication
* ====================
*
* Removing large number of rules from classifier can be costly, as the
* supporting data structures are teared down, in many cases just to be
* re-instantiated right after. In the worst case, as when each rule has a
* different match pattern (mask), the maintenance of the match patterns can
* have cost O(N^2), where N is the number of different match patterns. To
* alleviate this, the classifier supports a "deferred mode", in which changes
* in internal data structures needed for future version lookups may not be
* fully computed yet. The computation is finalized when the deferred mode is
* turned off.
*
* This feature can be used with versioning such that all changes to future
* versions are made in the deferred mode. Then, right before making the new
* version visible to lookups, the deferred mode is turned off so that all the
* data structures are ready for lookups with the new version number.
*
* To use deferred publication, first call classifier_defer(). Then, modify
* the classifier via additions (classifier_insert() with a specific, future
* version number) and deletions (use cls_rule_make_removable_after_version()).
* Then call classifier_publish(), and after that, announce the new version
* number to be used in lookups.
*
*
* Thread-safety
* =============
*
* The classifier may safely be accessed by many reader threads concurrently
* and by a single writer, or by multiple writers when they guarantee mutually
* exlucive access to classifier modifications.
*
* Since the classifier rules are RCU protected, the rule destruction after
* removal from the classifier must be RCU postponed. Also, when versioning is
* used, the rule removal itself needs to be typically RCU postponed. In this
* case the rule destruction is doubly RCU postponed, i.e., the second
* ovsrcu_postpone() call to destruct the rule is called from the first RCU
* callback that removes the rule.
*
* Rules that have never been visible to lookups are an exeption to the above
* rule. Such rules can be removed immediately, but their destruction must
* still be RCU postponed, as the rule's visibility attribute may be examined
* parallel to the rule's removal. */