使用OpenMP给程序加速
最近面试总是谈到效率问题,这个问题以前一直没考虑过,就是稀里糊涂的写。之前有看到过OpenMP,也不曾深究,看到这篇博客关于OpenMP写的非常详细,就转来慢慢学习吧。
OpenMP语法简介:
你想让你的程序运行的更快吗?
你想让你的程序在改动很少代码的基础上免费的飞奔起来吗?
如果答案是肯定的,向您推荐Inter免费的OpenMP。
OpenMP是基于多核处理器的,如果你的机器不是多核的,请不要往下读了!
1,OpenMP 的概述
OpenMP 的应用程序接口(API)是在共享存储体系结构上的一个编程模型,它包含编
译指导(Compiler Directive)、运行函数库(Runtime Library)和环境变量(Environment
Variables)。OpenMP 是一个编译器指令和库函数的集合,这些编译器指令和库函数主要用
于创建共享存储器计算机的并行程序。OpenMP 组合了C、C++或Fortran,以创建一种多线
程编程语言。它的语言模型基于这样一种假设:假设执行单元是共享一个地址空间的线程。
OpenMP 是基于派生/连接(fork/join)编程模型。一个OpenMP 程序从单个线程开始执
行,在程序的某些点需要并行执行时,程序派生出额外的线程,组成一个线程组。这些线程
在一个称为并行区域的代码区中并行执行。线程到达并行区域的末尾时等待,直到整个线程
组都到达,然后它们连接在一起,只有初始或者主线程继续执行,直到下一个并行区域(或
者程序结束)。
OpenMP 具有两个特性:串行等价性和递增的并行性。当一个程序无论是使用一个线程
运行还是使用多个线程运行时,它能够产生相同的结果,则该程序具有串行等价性。在大多
数情形中,具有串行等价性的程序更易于维护和理解(因此也更容易编写)。递增的并行性
是指一种并行的编程类型,其中一个程序从一个串行程序演化为一个并行程序。处理器从一
个串行程序开始,一块接着一块的寻找值得并行执行的代码段。这样,并行性被逐渐地添加。
在这个过程的每个阶段,存在一个可以被验证的程序,这极大地增加了项目的成功机率。
OpenMP 不具有下面三条性质:不是建立在分布式存储系统上的;不是在所有的环境下
都是一样的;不能保证多数共享存储器均能有效的利用。
2,OpenMP 程序结构
基于 C/C++语言的OpenMP 程序的结构如下:
#include
main ()
{
int var1, var2, var3;
/*Serial code*/
…
/*Beginning of parallel section. Fork a team ofthreads*/
/*Specify variable scoping */
#pragma omp parallel private(var1, var2) shared(var3)
{
/*Parallel section executed by all threads*/
…
/*All threads join master thread and disband*/
}
}
可以看出在C/C++中,通过# pragma omp parallel 来完成代码块的并行运行。
3,OpenMP语法概述
1)编译指导
一个 OpenMP 的编译指导语句不依赖于其他的语句。
形式如:#pragma omp directive_name…
例如:
#pragma omp parallel
{
…
#pragma omp for
for(…){
…
sub1();
…
}
…
sub2();
….
}
4,OpenMP在vs2008中的使用方法
1)在源文件中添加头文件 omp.h。
2)属性页->配置属性->c/c++->语言中OpenMP支持中选择是。
3)在需要并且可以并行的代码中按照OpenMP的语法优化代码即可。
OpenMP具体的使用方法及其注意事项。
首先声明本文主要是参考下面的网址内容进行的总结。详细信息可以参考下面的网址。
http://software.intel.com/zh-cn/articles/intel-guide-for-developing-multithreaded-applications/
对于多个嵌套式循环,选择最外层循环进行并行化最为安全。这种方法通常会生成最为粗糙的粒度。确保工作能够平均分配给每个线程。如果因最外层循环的迭代次数较低而无法实施平均分配,则最好选择具有较大迭代次数的内层循环进行线程分配。例如,考虑下面包含四个嵌套循环的代码:
- void processQuadArray (int imx, int jmx, int kmx,
- double**** w, double**** ws)
- {
- for (int nv = 0; nv < 5; nv++)
- for (int k = 0; k < kmx; k++)
- for (int j = 0; j < jmx; j++)
- for (int i = 0; i < imx; i++)
- ws[nv][k][j][i] = Process(w[nv][k][j][i]);
- }
如果线程数量多余或少于五个,并行外部循环将会导致负载不平衡和闲置线程。如果阵列维数imx、jmx和kmx非常大的话,并行效率将会很低。这种情况下最好选择并行其中一个内部循环。
如果能确保安全性,应尽可能排除工作分享结构底端的隐性障碍。所有 OpenMP 工作分享结构(不论整段还是单个)均在结构块底端含有一个隐性障碍。只有所有线程都在此障碍处集合后,并行才能执行。有时,这些障碍很不必要,并且会影响性能。应使用 OpenMP nowait 子句来消除这些障碍,如下面这个示例:
- void processQuadArray (int imx, int jmx, int kmx,
- double**** w, double**** ws)
- {
- #pragma omp parallel shared(w, ws)
- {
- int nv, k, j, i;
- for (nv = 0; nv < 5; nv++)
- for (k = 0; k < kmx; k++) // kmx is usually small
- #pragma omp for shared(nv, k) nowait
- for (j = 0; j < jmx; j++)
- for (i = 0; i < imx; i++)
- ws[nv][k][j][i] = Process(w[nv][k][j][i]);
- }
- }
由于最内层循环的计算都是独立的,因此在进行下一次迭代之前,线程没有必要在隐性障碍处等待。如果每次迭代的工作量各不相同,nowaitnowait 子句可使线程继续处理有用工作,而非闲置在隐性障碍处。
如果一个循环带有一种可防止循环被并行执行的循环传递相关性,可以将循环体分裂成单独的循环,进而实现并行执行。一个循环体被划分为两个或两个以上的循环被称为“循环分裂”。下面的示例演示了循环分裂过程,一个具有循环传递相关性的循环体创建出新的循环,进而完成并行执行。
- float *a, *b;
- int i;
- for (i = 1; i < N; i++) {
- if (b[i] > 0.0)
- a[i] = 2.0 * b[i];
- else
- a[i] = 2.0 * fabs(b[i]);
- b[i] = a[i-1];
- }
但是,若将一个循环体分裂成两个独立的操作,这两个操作均可并行执行,如下面的代码:
[+]
在执行计算任务时拥有一枚闲置内核无异于拥有一项废弃资源,在该内核上实施有效并行操作会延长线程化应用的整体运行时间。这枚内核处于闲置状态的原因有很多种,需要从内存或 I/O 中取出便是其中一个原因。尽管完全避免内核进入闲置状态不太可能,但编程人员仍然可以采取一些措施来缩短闲置时间,如采用重叠 I/O、内存预取的方式或重新排列数据访问模式的顺序,提高高速缓存利用率。
同样,闲置线程在执行多线程任务时也相当于废弃资源。分配给各线程的工作量不一样会导致名为“负载不均衡”的状况发生。这种不均衡程度越大,保持闲置状态的线程就会越多,完成计算任务所需的时间便会越长。分配给可用线程的各部分计算任务越均衡,完成整个计算任务的时间将会越短。
例如,一项任务由十二项独立任务组成,完成这些独立任务所需要的时间分别是:{10, 6, 4, 4, 2, 2, 2, 2, 1, 1, 1, 1}。假设现有四条线程共同承担这项计算任务,最简单的任务分配法是按照上述时间排列顺序为每条线程分配三项任务,即线程 0 完成所有分配的任务需要 20 个时间单元(10+6+4),线程 1 需要 8 个时间单元(4+2+2),线程 2 需要 5 个时间单元(2+2+1),线程 3 则只需要 3 个时间单元(1+1+1)。图 1(a)展示了这一任务分配状态,由此可见,完成全部十二项任务总共需要 20 个时间单元(完成整个任务所需时间应以最后完成的子任务用时为准)。
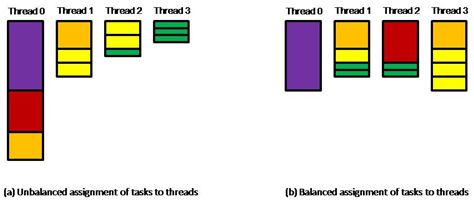
您也可以采用一种更合理的任务分配法,即线程 0 完成一项任务所需时间是 {10},线程 1 完成四项任务所需时间是 {4, 2, 1, 1},线程 2 完成三项任务所需时间是 {6, 1, 1},而线程 3 完成四项任务所需时间是 {4, 2, 2, 2}(如图 1(b)所示)。这样安排时间的优势是完成整个任务只需 10 个时间单元,四条线程中只有两条线程分别闲置了 2 个时间单元。
建议
如果完成所有任务所需时间长度相同,则在可用线程之间实施静态任务分配(即将整个任务划分为相同数量的子任务组并将每个子任务组分配给每条线程)是一种简单且合理的解决方案。但实际上就算事先已知道所有任务的执行时间长度,要找到一个在线程间实施最佳任务分配的方法仍然十分困难。如果各项子任务的执行时间长度不同,则可能需要采用一种更加动态的任务分配法来分配线程任务。
在默认情况下,OpenMP* 向线程调度迭代的策略是静态调度(如果不是静态调度则会另外注明)。当迭代之间的工作负载不同以及负载模式不可预知时,采用动态调度迭代的方法可以更好地平衡负载。动态调度和指数调度这两种静态调度替代方案都会通过 schedule 子句指定。在动态调度下,迭代数据块分配给线程;一旦分配完成,线程会申请获得一个新的迭代数据块。Schedule 子句的可选数据块参数会指明用于动态调度的迭代数据块固定尺寸。
- #pragma omp parallel for schedule(dynamic, 5)
- for (i = 0; i < n; i++)
- {
- unknown_amount_of_work(i);
- }
- #pragma omp parallel for schedule(dynamic, 5)
for (i = 0; i < n; i++)
{
unknown_amount_of_work(i);
}
指数调度最初会向线程分配大型迭代数据块;分配给所需线程的迭代数量会随着未分配迭代集的减少而减少。由于分配模式不同,指数调度的开销往往少于动态调度。Schedule 子句的可选数据块参数会指明在指数调度下一个数据块中所分配的迭代最低数量。
- #pragma omp parallel for schedule(guided, 8)
- for (i = 0; i < n; i++)
- {
- uneven_amount_of_work(i);
- }
- #pragma omp parallel for schedule(guided, 8)
for (i = 0; i < n; i++)
{
uneven_amount_of_work(i);
}
其中一个特例是迭代之间的工作负载单调递增或递减。例如,下三角形矩阵中每行元素数量会以正则表达式的形式增加。在此类情况下,通过静态调度设置一个相对较低的数据块尺寸(创建大量数据块/任务)可能有助于实现良好的负载平衡,同时还不会产生采用动态调度或指数调度所导致的开销。
- #pragma omp parallel for schedule(static, 4)
- for (i = 0; i < n; i++)
- {
- process_lower_triangular_row(i);
- }
- #pragma omp parallel for schedule(static, 4)
for (i = 0; i < n; i++)
{
process_lower_triangular_row(i);
}
如果调度策略不明显,采用运行时调度可以随意改变数据块尺寸和调度类型,而无需对程序进行重新编译。
在使用英特尔® 线程构建模块(英特尔® TBB)的 parallel_for 算法时,调度程序会将迭代空间划分为可分配给线程的小型任务。一旦某些迭代的计算用时比其它迭代长,英特尔® TBB 调度程序能够从线程中动态“盗取”任务,以便更好地实现线程间的工作负载平衡。
显式线程模式(如 Windows* 线程、Pthreads* 和 Java* 线程)无法自动为线程调度一系列独立任务。编程人员必须根据需要将这种能力编入应用程序中。静态调度任务是一种十分简单、直接的调度方法,而动态调度任务则可通过两种相关的方法轻松予以实施:生产者/消费者(Producer/Consumer)模式和老板/工人(Boss/Worker)模式。在前一个模式下,一条线程(生产者)会将任务置入共享队列结构中,而消费者线程会根据需要清除要处理的任务。生产者/消费者模式通常适用于在任务分配给消费者线程之前需要进行预处理之时(但也并非一定得采用这种模式)。
在老板/工人模式下,工人线程与老板线程会在需要直接分配的工作任务增多时会合。在划分任务十分简单的情况下(如将各类指数分配给数组进行处理),可以采用具备适宜同步化程度的全局计数器来取代单独的老板线程,即工人线程访问当前数值并针对下一条需要承担更多工作任务的线程调整(可能增加)计数器。
无论采用哪种任务调度模式,您都必须使用适量的线程和正确的线程组合,以确保这些肩负工作任务的线程执行所需计算任务,而不是进入闲置状态。例如,如果消费者线程有时处于闲置状态,则您需要减少消费者线程数量或可能需要再配备一条生产者线程。采用何种解决方案主要取决于算法以及需要分配的任务数量与执行时间长度。
使用指南
所有动态任务调度方法都将因分配任务而产生一定的开销。将独立的小型任务整合成为一项可分配的工作任务有助于减少上述开销;相应地,如果采用 OpenMP schedule 子句,您需要在任务内设置代表最少迭代次数的非默认数据块尺寸。将一项任务划分成多项计算任务的最佳方法取决于需要完成的计算量、线程的数量以及执行计算任务时可以使用的其它资源。
使用OpenMP优化for循环进行并行处理需要for的每次训话是彼此独立的。看下面的实例伪代码:
用相邻图像中的加权平均像素(包括该图像)来替换每个图像像素,便可通过模糊的方式来弱化图像。以下伪代码介绍了 3x3 模糊模板:
1)-for each pixel in (imageIn)
- sum = value of pixel
- // compute the average of 9 pixels from imageIn
- for each neighbor of (pixel)
- sum += value of neighbor
- // store the resulting value in imageOut
- pixelOut = sum / 9
2)另一个常见的例子是循环内部的指针发生偏移:
ptr = &someArray[0]
- for (i = 0; i < N; i++)
- {
- Compute (ptr);
- ptr++;
- }
3)下面是用OpenCV编写的横向合并两张图片的测试源代码:
IplImage *pImgOne = cvLoadImage("Result45678.jpg");
IplImage *pImgTwo = cvLoadImage("R009_9.jpg");
if (pImgOne==NULL || pImgTwo==NULL)
{
printf("Load Pic failed!/r/n");
return;
}
int iWidthResult = pImgOne->width + pImgTwo->width;
int iHightResult = pImgOne->height;
IplImage *pImgResult = cvCreateImage(cvSize(iWidthResult,iHightResult), pImgOne->depth, pImgOne->nChannels);
char *pResult = pImgResult->imageData;
char *pOne = pImgOne->imageData;
char *pTwo = pImgTwo->imageData;
for(int i=0; i
memcpy(pResult, pOne, pImgOne->widthStep);
pResult += pImgOne->widthStep;
pOne += pImgOne->widthStep;
memcpy(pResult, pTwo, pImgTwo->widthStep);
pResult += pImgTwo->widthStep;
pTwo += pImgTwo->widthStep;
}
这个三个例子都不能简单的利用OpenMP进行for并行优化。但我们可以人工消除并行依赖。
对于1)和3)我们可以采用分块处理,充分机器的多核优势!使每个处理器单独的处理每个数据块。
为了有效地实现模糊运算线程化,可以考虑将图像细分为子图像,或固定大小的数据块。模糊算法支持独立地对数据块进行计算。以下伪代码阐释了图像模块化的使用方法:
// Decompose the image into non-overlapping blocks.
- blockList = Decompose (image, xRes, yRes)
- foreach (block in blockList)
- {
- BlurBlock (block, imageIn, imageOut)
- }
同理,横向复制每行图像的程序3)也可以采用分块处理。
int iBlockSize = 512;//分块的大小与机器的处理器个数有关,笔者本机4核处理器,图像的总高度为2048,512=2048/4呵呵!
int iEveryBlockH = iHightResult/iBlockSize;
#pragma omp parallel for
for (int i=0; i
JointPicForMP(pImgOne, pImgTwo, pImgResult, i, iEveryBlockH);
}
void JointPicForMP(IplImage *pImgOne, IplImage *pImgTwo, IplImage *pImgResult, int iIndex, int iHight)
{
char *pResult = pImgResult->imageData + iIndex * pImgResult->widthStep * iHight;
char *pOne = pImgOne->imageData + iIndex * pImgOne->widthStep * iHight;
char *pTwo = pImgTwo->imageData + iIndex * pImgTwo->widthStep * iHight;
for (int i=0; i
memcpy(pResult, pOne, pImgOne->widthStep);
pResult += pImgOne->widthStep;
pOne += pImgOne->widthStep;
memcpy(pResult, pTwo, pImgTwo->widthStep);
pResult += pImgTwo->widthStep;
pTwo += pImgTwo->widthStep;
}
}
对于程序2)可以这样修改即可应用并行处理。
- ptr = &someArray[0]
- for (i = 0; i < N; i++)
- {
- Compute (ptr[i]);
- }
实验一:
利用蒙特卡罗算法计算半径为 1 单元的球体体积:
#include "stdafx.h"
#include
#include
#include "Windows.h"
#include
#include
using namespace std;
int main()
{
long int max=10000000;
long int i,count=0;
double x,y,z,bulk,start_time,end_time;
start_time=clock();
time_t t;
srand((unsigned) time(&t));//函数产生一个以当前时间开始的随机种子
for(i=0;i
x=rand();
x=x/32767;
y=rand();
y=y/32767;
z=rand();
z=z/32767;
if((x*x+y*y+z*z)<=1)
count++;
}
bulk=8*(double(count)/max);
end_time=clock();
cout<<"球体的体积为"<
return 0;
}
使用OpenMP的运行程序及其结果:
long long max=10000000;
long long i,count=0;
double x,y,z,bulk,start_time,end_time;
start_time=clock();
time_t t;
srand((unsigned) time(&t));//函数产生一个以当前时间开始的随机种子
//omp_set_num_threads( 4 );
#pragma omp parallel for private(x,y,z) reduction(+:count)
for(i=0;i
x=rand();
x=x/32767;
y=rand();
y=y/32767;
z=rand();
z=z/32767;
if((x*x+y*y+z*z)<=1)
count++;
}
bulk=8*(double(count)/max);
end_time=clock();
cout<<"球体的体积为"<
}
实验二:
横向拼接两张图片(把第二张图片连接到第一张图片的右边),利用OpenCV。
普通程序,未用OpenMP优化。
IplImage *pImgOne = cvLoadImage("Result45678.jpg");
IplImage *pImgTwo = cvLoadImage("R009_9.jpg");
if (pImgOne==NULL || pImgTwo==NULL)
{
printf("Load Pic failed!/r/n");
return;
}
int iWidthResult = pImgOne->width + pImgTwo->width;
int iHightResult = pImgOne->height;
IplImage *pImgResult = cvCreateImage(cvSize(iWidthResult,iHightResult), pImgOne->depth, pImgOne->nChannels);
DWORD dwStart = ::GetTickCount();
char *pResult = pImgResult->imageData;
char *pOne = pImgOne->imageData;
char *pTwo = pImgTwo->imageData;
for(int i=0; i
memcpy(pResult, pOne, pImgOne->widthStep);
pResult += pImgOne->widthStep;
pOne += pImgOne->widthStep;
memcpy(pResult, pTwo, pImgTwo->widthStep);
pResult += pImgTwo->widthStep;
pTwo += pImgTwo->widthStep;
}
DWORD dwEnd = ::GetTickCount();
printf("...JointPic process not using MP cost %dms.../n",(dwEnd-dwStart));
循环上述代码100次得到的实验结果:
4核处理器的使用情况为:
从上图我们可以发现,四核使用不均衡,cpu最高使用率不会超过30%。
经过OpenMP优化的图片拼接程序,(分块处理)。
//iBlockSize 的大小根据目标机器的cpu个数及其优化任务所定,iBlockSize = task/NumberCpu->512=2048/4(2048为图像的高度)
int iBlockSize = 512;
int iEveryBlockH = iHightResult/iBlockSize;
DWORD dwStart = ::GetTickCount();
#pragma omp parallel for
for (int i=0; i
JointPicForMP(pImgOne, pImgTwo, pImgResult, i, iEveryBlockH);
}
DWORD dwEnd = ::GetTickCount();
printf("...JointPic process using MP cost %dms.../n",(dwEnd-dwStart));
void JointPicForMP(IplImage *pImgOne, IplImage *pImgTwo, IplImage *pImgResult, int iIndex, int iHight)
{
char *pResult = pImgResult->imageData + iIndex * pImgResult->widthStep * iHight;
char *pOne = pImgOne->imageData + iIndex * pImgOne->widthStep * iHight;
char *pTwo = pImgTwo->imageData + iIndex * pImgTwo->widthStep * iHight;
for (int i=0; i
memcpy(pResult, pOne, pImgOne->widthStep);
pResult += pImgOne->widthStep;
pOne += pImgOne->widthStep;
memcpy(pResult, pTwo, pImgTwo->widthStep);
pResult += pImgTwo->widthStep;
pTwo += pImgTwo->widthStep;
}
}
循环上述代码100次得到的实验结果:
4核处理器的使用情况为:
从上图我们可以发现,四核几乎被同时使用,cpu最高使用率可以达到100%。
结论(仅限于上述实验):
1)在四核机器上,使用OpenMP优化的程序可以使程序运行速率提高30%。
2)在四核机器上,使用OpenMP优化的程序,CPU的使用率会由30%提高到90%~100%。
3)使用OpenMP优化,属于编译语句级优化,使用简单,但有时需要对循环进行优化和重构。
4)当然,你可以使用Inter IPP(我不是给做广告哦!),但是,你得花钱,并且要遵循IPP的规范;如果不想花钱,所有的自己的代码都可控的情况下,不妨学习使用下OpenMP吧!