【题目】VGG-16网络详细分析(Keras代码)
【时间】2018.09.23
【题目】VGG-16网络分析(Keras代码)
目录
一、VGG-16的基本架构
二、Keras代码
三、代码详解
1、ZeroPadding2D层
2、Conv2D层
3、MaxPooling2D层
4、Flatten层
5、Dense层
6.Dropout层
一、VGG-16的基本架构
【VGG-16的架构】:
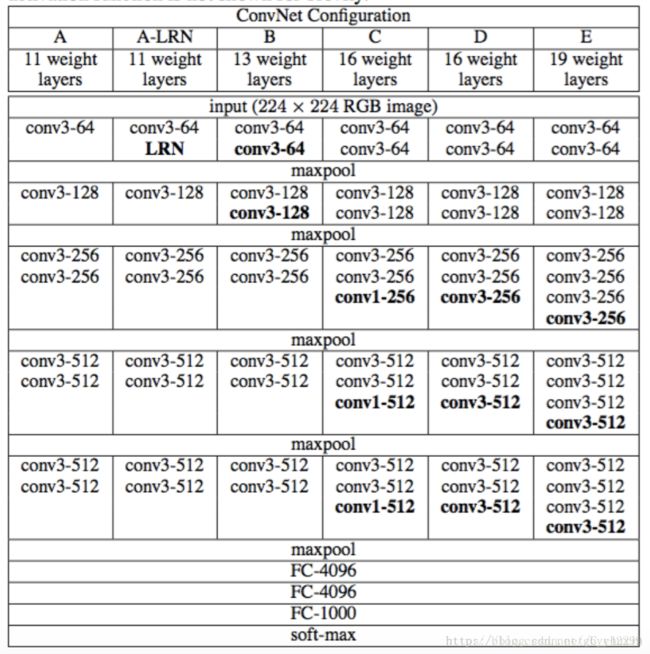
【架构说明】:
-
输入224x224x3的图片,经过64个卷积核的两次卷积后,采用一次pooling。经过第一次卷积后,c1有(3x3x3)个可训练参数
-
之后又经过两次128的卷积核卷积之后,采用一次pooling
-
再经过三次256的卷积核的卷积之后,采用pooling
-
重复两次三个512的卷积核卷积之后再pooling。
-
三次Fc
【由VGG-16改动而成的FASNet】:前面部分一致,只是在全连接层部分有所改动

二、Keras代码
(代码部分来自https://blog.csdn.net/u012606764/article/details/80495630)
【代码】:
def VGG_16(weights_path=None):
model = Sequential()
model.add(ZeroPadding2D((1,1),input_shape=(3,224,224)))#卷积输入层,指定了输入图像的大小
model.add(Convolution2D(64, 3, 3, activation='relu'))#64个3x3的卷积核,生成64*224*224的图像,激活函数为relu
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(64, 3, 3, activation='relu'))#再来一次卷积 生成64*224*224
model.add(MaxPooling2D((2,2), strides=(2,2)))#pooling操作,相当于变成64*112*112
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(128, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(128, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))#128*56*56
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))#256*28*28
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))#512*14*14
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2))) #到这里已经变成了512*7*7
model.add(Flatten())#压平上述向量,变成一维25088
model.add(Dense(4096, activation='relu'))#全连接层有4096个神经核,参数个数就是4096*25088
model.add(Dropout(0.5))#0.5的概率抛弃一些连接
model.add(Dense(4096, activation='relu'))#再来一个全连接
model.add(Dropout(0.5))
model.add(Dense(1000, activation='softmax'))
if weights_path:
model.load_weights(weights_path)
return model
【网络参数】:
INPUT: [224x224x3] memory: 224*224*3=150K weights: 0
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*3)*64 = 1,728
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*64)*64 = 36,864
POOL2: [112x112x64] memory: 112*112*64=800K weights: 0
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*64)*128 = 73,728
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*128)*128 = 147,456
POOL2: [56x56x128] memory: 56*56*128=400K weights: 0
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*128)*256 = 294,912
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
POOL2: [28x28x256] memory: 28*28*256=200K weights: 0
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*256)*512 = 1,179,648
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
POOL2: [14x14x512] memory: 14*14*512=100K weights: 0
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
POOL2: [7x7x512] memory: 7*7*512=25K weights: 0
FC: [1x1x4096] memory: 4096 weights: 7*7*512*4096 = 102,760,448
FC: [1x1x4096] memory: 4096 weights: 4096*4096 = 16,777,216
FC: [1x1x1000] memory: 1000 weights: 4096*1000 = 4,096,000
TOTAL memory: 24M * 4 bytes ~= 93MB / image (only forward! ~*2 for bwd)
TOTAL params: 138M parameters
三、代码详解
1、ZeroPadding2D层
keras.layers.convolutional.ZeroPadding2D(padding=(1, 1), data_format=None)
对2D输入(如图片)的边界填充0,以控制卷积以后特征图的大小
例如:
model.add(ZeroPadding2D((1,1),input_shape=(3,224,224)))
参数
-
padding:整数tuple,表示在要填充的轴的起始和结束处填充0的数目,这里要填充的轴是轴3和轴4(即在'th'模式下图像的行和列,在‘channels_last’模式下要填充的则是轴2,3)
说明:这是keras中的补零操作,下面举2个例子。
padding= (1,0),会在行的最前和最后都增加一行0。比方说,原来的尺寸为(None,20,11,1),padding之后就会变成(None,22,11,1).
padding= (1,1),会在行和列的最前和最后都增加一行0。比方说,原来的尺寸为(None,20,11,1),padding之后就会变成(None,22,13,1).
在使用核大小为(3,3)的卷积,只要在输入的行列的前后先各补一行0,就可以保证卷积层前后输出的尺寸是一样的。(2D的行X列)
-
data_format:字符串,“channels_first”或“channels_last”之一,代表图像的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。以128x128的RGB图像为例,“channels_first”应将数据组织为(3,128,128),而“channels_last”应将数据组织为(128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channels_last”。
输入shape
‘channels_first’模式下,形如(samples,channels,first_axis_to_pad,second_axis_to_pad)的4D张量
‘channels_last’模式下,形如(samples,first_axis_to_pad,second_axis_to_pad, channels)的4D张量
输出shape
‘channels_first’模式下,形如(samples,channels,first_paded_axis,second_paded_axis)的4D张量
‘channels_last’模式下,形如(samples,first_paded_axis,second_paded_axis, channels)的4D张量
2、Conv2D层
keras.layers.convolutional.Conv2D(filters, kernel_size, strides=(1, 1), padding='valid', data_format=None, dilation_rate=(1, 1), activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
二维卷积层,即对图像的空域卷积。该层对二维输入进行滑动窗卷积,当使用该层作为第一层时,应提供input_shape参数。例如input_shape = (128,128,3)代表128*128的彩色RGB图像(data_format='channels_last')
例如:
model.add(Convolution2D(64, 3, 3, activation='relu'))
参数:
-
filters:卷积核的数目(即输出的维度)
-
kernel_size:单个整数或由两个整数构成的list/tuple,卷积核的宽度和长度。如为单个整数,则表示在各个空间维度的相同长度。
-
strides:单个整数或由两个整数构成的list/tuple,为卷积的步长。如为单个整数,则表示在各个空间维度的相同步长。任何不为1的strides均与任何不为1的dilation_rate均不兼容
-
padding:补0策略,为“valid”, “same” 。“valid”代表只进行有效的卷积,即对边界数据不处理。“same”代表保留边界处的卷积结果,通常会导致输出shape与输入shape相同。
-
activation:激活函数,为预定义的激活函数名(参考激活函数),或逐元素(element-wise)的Theano函数。如果不指定该参数,将不会使用任何激活函数(即使用线性激活函数:a(x)=x)
-
dilation_rate:单个整数或由两个个整数构成的list/tuple,指定dilated convolution中的膨胀比例。任何不为1的dilation_rate均与任何不为1的strides均不兼容。
-
data_format:字符串,“channels_first”或“channels_last”之一,代表图像的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。以128x128的RGB图像为例,“channels_first”应将数据组织为(3,128,128),而“channels_last”应将数据组织为(128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channels_last”。
-
use_bias:布尔值,是否使用偏置项
-
kernel_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
-
bias_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
-
kernel_regularizer:施加在权重上的正则项,为Regularizer对象
-
bias_regularizer:施加在偏置向量上的正则项,为Regularizer对象
-
activity_regularizer:施加在输出上的正则项,为Regularizer对象
-
kernel_constraints:施加在权重上的约束项,为Constraints对象
-
bias_constraints:施加在偏置上的约束项,为Constraints对象
输入shape
‘channels_first’模式下,输入形如(samples,channels,rows,cols)的4D张量
‘channels_last’模式下,输入形如(samples,rows,cols,channels)的4D张量
注意这里的输入shape指的是函数内部实现的输入shape,而非函数接口应指定的input_shape,请参考下面提供的例子。
输出shape
‘channels_first’模式下,为形如(samples,nb_filter, new_rows, new_cols)的4D张量
‘channels_last’模式下,为形如(samples,new_rows, new_cols,nb_filter)的4D张量
输出的行列数可能会因为填充方法而改变
3、MaxPooling2D层
keras.layers.pooling.MaxPooling2D(pool_size=(2, 2), strides=None, padding='valid', data_format=None)
为空域信号施加最大值池化
例如:
model.add(MaxPooling2D((2,2), strides=(2,2)))
参数
-
pool_size:整数或长为2的整数tuple,代表在两个方向(竖直,水平)上的下采样因子,如取(2,2)将使图片在两个维度上均变为原长的一半。为整数意为各个维度值相同且为该数字。
-
strides:整数或长为2的整数tuple,或者None,步长值。
-
border_mode:‘valid’或者‘same’
-
data_format:字符串,“channels_first”或“channels_last”之一,代表图像的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。以128x128的RGB图像为例,“channels_first”应将数据组织为(3,128,128),而“channels_last”应将数据组织为(128,128,3)。该参数的默认值是~/.keras/keras.json中设置的值,若从未设置过,则为“channels_last”。
输入shape
‘channels_first’模式下,为形如(samples,channels, rows,cols)的4D张量
‘channels_last’模式下,为形如(samples,rows, cols,channels)的4D张量
输出shape
‘channels_first’模式下,为形如(samples,channels, pooled_rows, pooled_cols)的4D张量
‘channels_last’模式下,为形如(samples,pooled_rows, pooled_cols,channels)的4D张量
4、Flatten层
keras.layers.core.Flatten()
Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。Flatten不影响batch的大小。
例子
model = Sequential()
model.add(Convolution2D(64, 3, 3,
border_mode='same',
input_shape=(3, 32, 32)))
# now: model.output_shape == (None, 64, 32, 32)
model.add(Flatten())
# now: model.output_shape == (None, 65536)
5、Dense层
keras.layers.core.Dense(units, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
Dense就是常用的全连接层,所实现的运算是output = activation(dot(input, kernel)+bias)。其中activation是逐元素计算的激活函数,kernel是本层的权值矩阵,bias为偏置向量,只有当use_bias=True才会添加。
如果本层的输入数据的维度大于2,则会先被压为与kernel相匹配的大小。
这里是一个使用示例:
# as first layer in a sequential model:# as first layer in a sequential model:
model = Sequential()
model.add(Dense(32, input_shape=(16,)))
# now the model will take as input arrays of shape (*, 16)# and output arrays of shape (*, 32)
# after the first layer, you don't need to specify# the size of the input anymore:
model.add(Dense(32))
参数:
-
units:大于0的整数,代表该层的输出维度(即相当于卷积中“核数目”)。
-
activation:激活函数,为预定义的激活函数名(参考激活函数),或逐元素(element-wise)的Theano函数。如果不指定该参数,将不会使用任何激活函数(即使用线性激活函数:a(x)=x)
-
use_bias: 布尔值,是否使用偏置项
-
kernel_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
-
bias_initializer:偏置向量初始化方法,为预定义初始化方法名的字符串,或用于初始化偏置向量的初始化器。参考initializers
-
kernel_regularizer:施加在权重上的正则项,为Regularizer对象
-
bias_regularizer:施加在偏置向量上的正则项,为Regularizer对象
-
activity_regularizer:施加在输出上的正则项,为Regularizer对象
-
kernel_constraints:施加在权重上的约束项,为Constraints对象
-
bias_constraints:施加在偏置上的约束项,为Constraints对象
输入
形如(batch_size, ..., input_dim)的nD张量,最常见的情况为(batch_size, input_dim)的2D张量
输出
形如(batch_size, ..., units)的nD张量,最常见的情况为(batch_size, units)的2D张量
6.Dropout层
keras.layers.core.Dropout(rate, noise_shape=None, seed=None)
为输入数据施加Dropout。Dropout将在训练过程中每次更新参数时按一定概率(rate)随机断开输入神经元,Dropout层用于防止过拟合。
参数
-
rate:0~1的浮点数,控制需要断开的神经元的比例
-
noise_shape:整数张量,为将要应用在输入上的二值Dropout mask的shape,例如你的输入为(batch_size, timesteps, features),并且你希望在各个时间步上的Dropout mask都相同,则可传入noise_shape=(batch_size, 1, features)。
-
seed:整数,使用的随机数种子
参考文献
-
Dropout: A Simple Way to Prevent Neural Networks from Overfitting