Matconvnet 构建自己的网络
前一篇文章中,我们使用已经训练好的模型,通过修改最后一层,训练最后一层实现图片分类,这种做法的好处是可以节省大量的时间,同时一会弥补数据量的不足。但是,有时候我们需要构建自己的网络来达到我们的目标,本篇文章就是讲述如何使用Matconvnet 构建自己的网络,作者水平较低,还请多多包涵与指正。
1.首先仍然是准备数据
本文采用sort_1000数据集,共有10类,每类100张图片,图片大小为384x256,

附下载链接:
链接:http://pan.baidu.com/s/1miPulsO 密码:gt8g
整理数据,取每类的前80张为训练集,后20张作为验证集,准备trainLabel.txt与testLabel.txt,形式如下
300.jpg 4
301.jpg 4
302.jpg 4
303.jpg 4
304.jpg 4
305.jpg 4
306.jpg 4
307.jpg 4
308.jpg 4
309.jpg 4
310.jpg 4
311.jpg 4
312.jpg 4
313.jpg 4
314.jpg 4
315.jpg 4
316.jpg 4
317.jpg 4
classIndex.txt
1 face
2 sky
3 building
4 bus
5 dinosaur
6 elephant
7 flower
8 horse
9 snowmoutain
10 food
整个数据集结构如下:
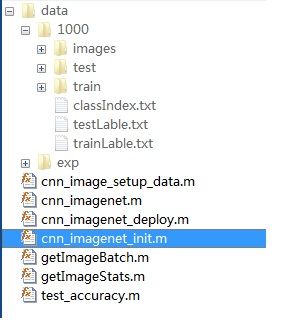
train文件夹放所有的训练图片,test为验证集
2. 函数编写
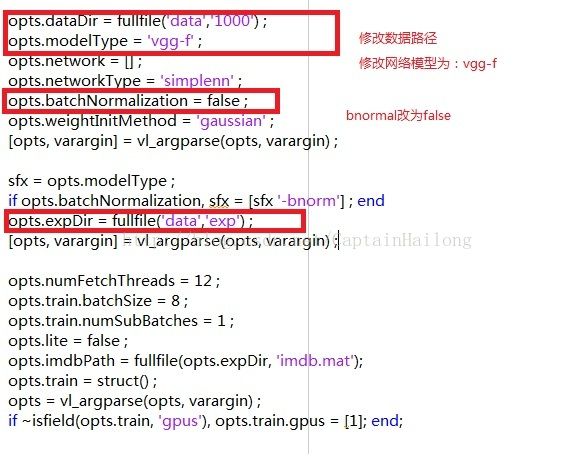
在matconvnet 根目录下新建一个文件夹myself_matconvnet 用于存放我们的代码,同时我们的数据也会放在这里。这里我使用的是matconvnet-1.0-beta24版本,
复制examples文件夹下imagenet文件夹里的cnn_imagenet.m,cnn_imagenet_deploy.m,cnn_imagenet_init.m,getImageBatch.m,getImageStats.m到myself_matconvnet下。
1.修改cnn_imagenet.m
2.cnn_imagenet_init.m 网络定义
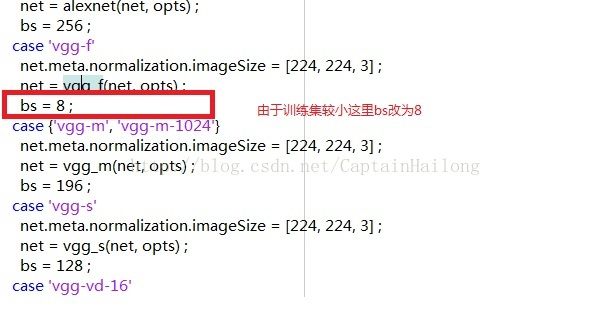

网络结构如下,
layer| 0| 1| 2| 3| 4| 5| 6| 7| 8| 9| 10| 11| 12| 13| 14| 15| 16| 17|
type|input| conv| relu| norm| mpool| conv| relu| norm|mpool| conv| relu| conv| relu| conv| relu|mpool| conv| relu|
name| n/a|conv1|relu1|norm1| pool1|conv2|relu2|norm2|pool2|conv3|relu3|conv4|relu4|conv5|relu5|pool5| fc6|relu6|
----------|-----|-----|-----|-----|-------|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|
support| n/a| 11| 1| 1| 3| 5| 1| 1| 3| 3| 1| 3| 1| 3| 1| 3| 6| 1|
filt dim| n/a| 3| n/a| n/a| n/a| 64| n/a| n/a| n/a| 256| n/a| 256| n/a| 256| n/a| n/a| 256| n/a|
filt dilat| n/a| 1| n/a| n/a| n/a| 1| n/a| n/a| n/a| 1| n/a| 1| n/a| 1| n/a| n/a| 1| n/a|
num filts| n/a| 64| n/a| n/a| n/a| 256| n/a| n/a| n/a| 256| n/a| 256| n/a| 256| n/a| n/a| 4096| n/a|
stride| n/a| 4| 1| 1| 2| 1| 1| 1| 2| 1| 1| 1| 1| 1| 1| 2| 1| 1|
pad| n/a| 0| 0| 0|0x1x0x1| 2| 0| 0| 0| 1| 0| 1| 0| 1| 0| 0| 0| 0|
----------|-----|-----|-----|-----|-------|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|
rf size| n/a| 11| 11| 11| 19| 51| 51| 51| 67| 99| 99| 131| 131| 163| 163| 195| 355| 355|
rf offset| n/a| 6| 6| 6| 10| 10| 10| 10| 18| 18| 18| 18| 18| 18| 18| 34| 114| 114|
rf stride| n/a| 4| 4| 4| 8| 8| 8| 8| 16| 16| 16| 16| 16| 16| 16| 32| 32| 32|
----------|-----|-----|-----|-----|-------|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|
data size| 224| 54| 54| 54| 27| 27| 27| 27| 13| 13| 13| 13| 13| 13| 13| 6| 1| 1|
data depth| 3| 64| 64| 64| 64| 256| 256| 256| 256| 256| 256| 256| 256| 256| 256| 256| 4096| 4096|
data num| 8| 8| 8| 8| 8| 8| 8| 8| 8| 8| 8| 8| 8| 8| 8| 8| 8| 8|
----------|-----|-----|-----|-----|-------|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|-----|
data mem| 5MB| 6MB| 6MB| 6MB| 1MB| 6MB| 6MB| 6MB| 1MB| 1MB| 1MB| 1MB| 1MB| 1MB| 1MB|288KB|128KB|128KB|
param mem| n/a| 91KB| 0B| 0B| 0B| 2MB| 0B| 0B| 0B| 2MB| 0B| 2MB| 0B| 2MB| 0B| 0B|144MB| 0B|
layer| 18| 19| 20| 21| 22| 23|
type| dropout| conv| relu| dropout| conv|softmxl|
name|dropout6| fc7|relu7|dropout7| fc8| loss|
----------|--------|-----|-----|--------|-----|-------|
support| 1| 1| 1| 1| 1| 1|
filt dim| n/a| 4096| n/a| n/a| 4096| n/a|
filt dilat| n/a| 1| n/a| n/a| 1| n/a|
num filts| n/a| 4096| n/a| n/a| 10| n/a|
stride| 1| 1| 1| 1| 1| 1|
pad| 0| 0| 0| 0| 0| 0|
----------|--------|-----|-----|--------|-----|-------|
rf size| 355| 355| 355| 355| 355| 355|
rf offset| 114| 114| 114| 114| 114| 114|
rf stride| 32| 32| 32| 32| 32| 32|
----------|--------|-----|-----|--------|-----|-------|
data size| 1| 1| 1| 1| 1| 1|
data depth| 4096| 4096| 4096| 4096| 10| 1|
data num| 8| 8| 8| 8| 8| 1|
----------|--------|-----|-----|--------|-----|-------|
data mem| 128KB|128KB|128KB| 128KB| 320B| 4B|
param mem| 0B| 64MB| 0B| 0B|160KB| 0B|
这个为vgg-f网络,共23层
3.cnn_image_setup_data.m 准备数据
function imdb = cnn_image_setup_data(varargin)
opts.dataDir = fullfile('data','1000') ;
opts.lite = false ;
opts = vl_argparse(opts, varargin) ;
% ------------------------------------------------------------------------
% Load categories metadata
% -------------------------------------------------------------------------
metaPath = fullfile(opts.dataDir, 'classIndex.txt') ;
fprintf('using metadata %s\n', metaPath) ;
tmp = importdata(metaPath);
nCls = numel(tmp);
if nCls ~= 10
error('Wrong meta file %s',metaPath);
end
cats = cell(1,nCls);
for i=1:numel(tmp)
t = strsplit(tmp{i});
cats{i} = t{2};
end
imdb.classes.name = cats ;
imdb.imageDir.train = fullfile(opts.dataDir, 'train') ;
imdb.imageDir.test = fullfile(opts.dataDir, 'test') ;
%% -----------------------------------------------------------------
% load image names and labels
% -------------------------------------------------------------------------
name = {};
labels = {} ;
imdb.images.sets = [] ;
%%
fprintf('searching training images ...\n') ;
train_label_path = fullfile(opts.dataDir, 'trainLable.txt') ;
train_label_temp = importdata(train_label_path);
temp_l = train_label_temp.data;
for i=1:numel(temp_l)
train_label{i} = temp_l(i);
end
if length(train_label) ~= length(dir(fullfile(imdb.imageDir.train, '*.jpg')))
error('training data is not equal to its label!!!');
end
temp_n=train_label_temp.textdata;
for i=1:numel(temp_n)
name{end+1}=temp_n{i};
labels{end+1} = train_label{i} ;
imdb.images.sets(end+1) = 1;
end
fprintf('searching testing images ...\n') ;
test_label_path = fullfile(opts.dataDir, 'testLable.txt') ;
test_label_temp = importdata(test_label_path);
temp_l = test_label_temp.data;
for i=1:numel(temp_l)
test_label{i} = temp_l(i);
end
if length(test_label) ~= length(dir(fullfile(imdb.imageDir.test, '*.jpg')))
error('testing data is not equal to its label!!!');
end
temp_n=test_label_temp.textdata;
for i=1:numel(temp_n)
name{end+1}=temp_n{i};
labels{end+1} = test_label{i} ;
imdb.images.sets(end+1) = 3;
end
labels = horzcat(labels{:}) ;
imdb.images.id = 1:numel(name) ;
imdb.images.name = name ;
imdb.images.label = labels ;
4.test_accuracy.m 测试
function test_accuracy()
net = load('data/exp/net-deployed.mat') ;
net = vl_simplenn_tidy(net) ;
imdb = load('data/exp/imdb.mat') ;
opts.dataDir = fullfile('data','1000') ;
opts.expDir = fullfile('exp') ;
opts.train.train = find(imdb.images.sets==1) ;
opts.train.val = find(imdb.images.sets==3) ;
for i = 1:length(opts.train.val)
index = opts.train.val(i);
label = imdb.images.label(index);
im = imread(fullfile(imdb.imageDir.test,imdb.images.name{index}));
im_ = single(im) ; % note: 255 range
im_ = imresize(im_, net.meta.normalization.imageSize(1:2)) ;
% im_ = im_ - net.meta.normalization.averageImage ;
im_(:,:,1)= im_(:,:,1)-net.meta.normalization.averageImage(1);
im_(:,:,2)= im_(:,:,2)-net.meta.normalization.averageImage(2);
im_(:,:,3)= im_(:,:,3)-net.meta.normalization.averageImage(3);
res = vl_simplenn(net, im_) ;
scores = squeeze(gather(res(end).x)) ;
[bestScore, best] = max(scores) ;
% i,scores,best
truth(i) = label;
pre(i) = best;
end
accurcy = length(find(pre==truth))/length(truth);
disp(['accurcy = ',num2str(accurcy*100),'%']);
3.运行程序


附项目含数据
链接:http://pan.baidu.com/s/1mhAkUDi 密码:wmab