深度学习课程导论
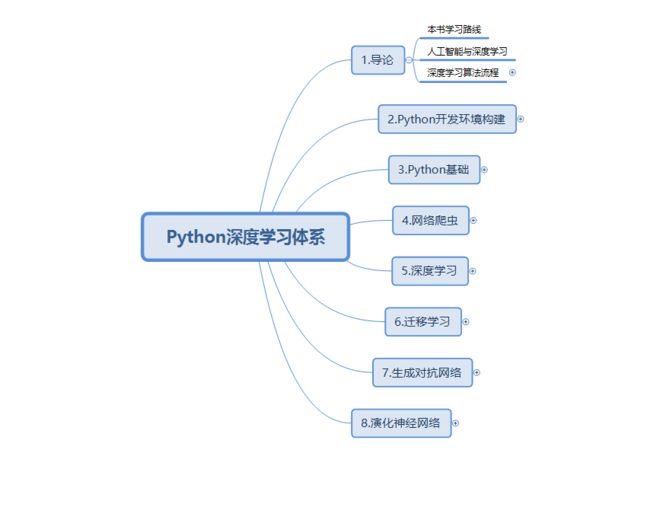
图1.1本书学习路线
Hello,又是一个分享的日子,本期推文分享的是深度学习课程的学习路线。
导论
![]()
大数据时代的来临,算力和存储的连年提升,促使人工智能迅猛发展。各大高校人工智能专业的开设和人工智能类岗位高昂的薪资,以及人工智能纳入国家重点发展计划都在说明人工智能开始迎来新的一波风口。市场对该类人才的紧缺需求是毋容置疑的。深度学习作为人工智能的重要组成部分,毫无疑问地成为了每一个初学者必须了解的一环。
一门学科的学习固然离不开大量的时间,但如何将它事半功倍,是值得我们思考的。古人云:“三思而后行”,这个“思”就是行动前规划好行动路径图,沿着有效的路径去行动,效果当然也就事半功倍。
知识体系就好比人类的骨架,骨架的健硕才能让血肉更好的生长。没有骨架,再多的血肉都是一坨烂泥。相反,一副健硕的骨架却能让你不断造血加肉,将自己感兴趣的那一块“肌肉”不断壮大,成为这一领域的专才。
在深度学习如火如荼发展的时代,大批的初学者涌入这个领域,一条行之有效的学习路径是每一个初学者所急需的。本书的编写正是为了弥补这方面的空白,帮助每一个读者构建属于自己的深度学习体系。它涵盖了深度学习的热门领域与当前科研热点,并结合实操,从简到难逐步揭开深度学习的神秘面纱。
本书学习路线
全书共八个章节,每个章节联系紧密,并且配套相应的实验与代码讲解视频,建议初学者按顺序阅读,这样能有效帮助大家建立起一套完备的深度学习体系。接下来,笔者就图1.1给各位读者介绍下本书的知识体系。
1.1.1导论
导论分为三个小节:本书学习路线、人工智能与深度学习和深度学习的算法流程。重点在第三小节----深度学习的算法流程。这将会给读者介绍一整套深度学习的操作流程是如何进行的,以及在我们学习深度学习之前,读者应该具备哪些预备知识。
1.1.2 Python开发环境搭建
这一章主要是介绍了本书使用的操作系统与编程环境。这将会给大家详细介绍Windows与Linux操作系统的Python开发环境搭建。
1.1.3 Python基础
这一章主要介绍了本书使用的编程语言,将会涉及Python的语法与其高阶用法。这是本书最为基础的一部分,而且本书所有章节的实验基本以Python为基础去编写,因此笔者将尽可能用同一套代码帮助大家将知识点串联起来。当然,已经对Python相对熟悉的读者,可以跳过本章内容。
1.1.4 网络爬虫
算法和数据是深度学习的最重要的两个元素。俗话说:“巧妇难为无米之炊”,随着大数据时代的来临,人们越来越意识到了数据的重要性,没有数据,再好的算法都是“garbage in, garbage out.”。互联网作为这个星球上最大的数据库,我们不可避免会通过它去获得数据。因此这一章,笔者将给大家系统地介绍如何使用商业爬虫框架Scrapy和虚拟浏览器去爬取互联网中的数据。
1.1.5 深度学习
这一章是整本书的精华所在,笔者将会给大家详细介绍深度学习中的常见网络,并配套相应的实验,以帮助大家掌握整个深度学习的重点。更进一步,笔者以本章为基础,衍生出第6、7、8章,帮助大家更进一步了解深度学习当前热点与未来趋势。
1.1.6 迁移学习
迁移学习讲诉了一个站在巨人肩膀的故事。随着越来越多的深度学习应用场景的出现,人们不可避免会去想,如何利用已训练的模型去完成相类似的任务,毕竟重新训练一个优秀的模型需要耗费大量的时间和算力,而在前人的模型上修修补补,举一反三无疑是最好的办法。因此,迁移学习逐步成为了人们研究的热点。
1.1.7 生成对抗网络
生成对抗网络书写了一个以假乱真的剧本。近年来AI换脸等技术火爆全球,离不开这个网络的点滴贡献。生成对抗网络能够学习数据的分布规律,并创造出类似我们真实世界的物件如图像、文本等。从假乱真的程度上看,它甚至可以被誉为深度学习中的艺术家。因此,生成对抗网络也逐步成为了人们研究的热点。
1.1.8 演化神经网络
演化神经网络描绘了一个优胜劣汰的传承。演化神经网络是结合了神经网络和遗传算法与进化策略产生的一种全新模型。它通过模仿自然界“适者生存”的原则来赋予神经网络在代际循环中优化的力量,能有效克服传统神经网络在训练过程中的缺点。因此,演化神经网络也逐步成为未来科研的热点。
人工智能与深度学习
![]()

图1.2 人工智能与深度学习关系图
在进入本书学习之前,我们得了解下人工智能与深度学习的关系,这有助于我们更好地掌握整体的深度学习知识体系。
早在1956年,人工智能这个概念就被人们所提出。从概念的提出到成为现实,人工智能经历了两次起伏,从奉为明珠到避之不及再到趋之若鹜,这其中伴随着的是技术的革命:运算和存储资源变得廉价以及数据开始成为“黄金”,这都在推动着人工智能的发展。
人工智能顾名思义就是人工赋予机器智能,但与人工智能先驱们所设想的赋予机器独立思考能力的“强人工智能”所不一样,目前我们所说的人工智能都是“弱人工智能”。它能跟人一样实现一些既定的任务,比如人脸识别、垃圾邮件分类等,有时甚至超越人类。
深度学习则是人们通过仿生学创造性提出的一种人工神经网络技术。人们通过训练这些神经网络,使其出色地完成了很多机器学习任务。因此,深度学习是人工智能历史上一个重大突破,它拓展了人工智能的领域范围和促进了人工智能的发展。
从图1.2可知,人工智能包裹着机器学习,机器学习包裹着深度学习。简单来讲,人工智能是一个概念,机器学习是实现人工智能的一种方法,而深度学习是实现机器学习的一种技术。当然,实现机器学习的方法包含但不仅限于深度学习,如强化学习或者传统的机器学习技术等。
深度学习算法流程
![]()
![]()
从本节开始,我们正式进入本书的学习。为此,我们先了解深度学习的整体流程是怎么一回事。如图1.3所示的深度学习整体流程:数据集切分为训练集、验证集和测试集。训练集用以训练深度学习模型;验证集用以评估模型结果,进而辅助模型调参;测试集用以模型的预测。一般而言,训练集、验证集与测试集的比例为:7:2:1。
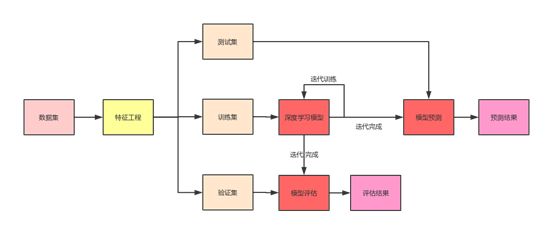
图1.3深度学习算法流程图
1.3.1特征工程
目前业界有句话被广为流传:“数据和特征决定了机器学习的上限,而模型与算法则是逼近这个上限而已。”因此,特征工程做得好,我们得到的预期结果也就好。那特征工程到底是什么呢?在此之前,我们得了解特征的类型:文本特征、图像特征、数值特征和类别特征等。我们知道计算机并不能直接处理非数值型数据,那么在我们要将数据灌入机器学习算法之前,就必须将数据处理成算法能理解的格式,有时甚至需要对数据进行一些组合处理如分桶、缺失值处理和异常值处理等。这也就是特征工程做的事:提取和归纳特征,让算法最大程度地利用数据,从而得到更好的结果。
不过,相较于传统的机器学习,深度学习的特征工程会简单许多,我们一般将数据处理成算法能够理解的格式即可,后期对神经网络的训练,就是提取和归纳特征的过程。这也是深度学习能被广泛使用的原因之一:特征工程能够自动化。因此,本书所涉及的特征工程主要是文本预处理、图像预处理和数值预处理(归一化),这些均会通过实验来进行讲解。
1.3.2模型评估
模型评估指标有很多种,因此根据问题去选择合适的评估指标是衡量结果好坏的重要方法。所以,我们需要知道评估指标的定义,从而选择正确的模型评估方式,才能知道模型的问题所在,进而对模型进行参数调优。深度学习模型执行的任务可以归为两类:分类任务和回归(预测)任务。为此我们也有不同的指标去评估模型。
1.分类任务评估指标
1)准确率:对于给定数据集的预测结果,分类正确的样本数占总样本数的百分比。但对于不均衡的训练集来说,会有致命的缺陷,如当负样本占比在 99%时,模型只要将结果都预测为负样本,准确率就达到了 99%,这并不是最合理的评估方式。
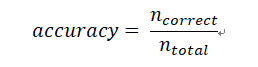
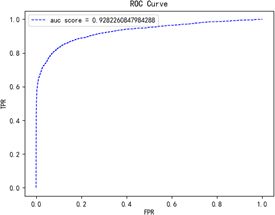
2)精确率和召回率:它们是一对衡量检索系统的指标,精确率衡量的是检索系统推送出来的正确结果与推送出来的所有结果占比,召回率衡量的是系统推送出来的正确结果与整个系统的实际正确结果的占比。但精确率和召回率是矛盾统一的一对指标,为了提高精确率,模型需要更有“把握”把真正的正样本识别出来,这样必然会放弃一些很多没有“把握”(但实际是正样本)的正样本,从而导致召回率降低。下面我们通过一个二分类混淆矩阵来示意这两个指标是如何计算的。下表中,是正类样本中被分类器预测为正类的数目,是正类样本中被分类器预测为负类的数目,是负类样本中被分类器预测为正类的数目,是负类样本中被分类器预测为负类的数目。




总结
![]()
本章内容并不多,总体是为了介绍整本书的学习路线和人工智能与深度学习的关系,以及深度学习算法的整体流程,让大家对深度学习有个全局的认识。对于接下来的章节,笔者将会按照本章所设计的学习路线,逐步带领大家揭开深度学习的神秘面纱。

