回顾·爱奇艺流量反作弊的“术”与“道”

作者:张晓明
整理:DataFun社区
社区公众号ID:datafuntalk

今天主要从以下几个方面介绍,首先介绍下流量反作弊相关的介绍,然后是爱奇艺流量反作弊的“道”,爱奇艺流量反作弊涉及到的点很多,起“道”还是蛮贴切的,让大家对爱奇艺流量反作弊有个认知;接下来就是流量反作弊是怎么做的。第四个从系统应用的角度讲如何构建反作弊体系,最后就是未来的展望。

首先说一下什么是流量反作弊,书面并没有官方定义,我定义为制造非用户产生,或带有一定目的性的数据。非用户产生的就是程序员写的一些代码重复执行投递逻辑或产生一些并非人为产生的数据,带有一定目的性指有些数据并不是机器产生的,很大部分都是人产生的。如一个人在APP上重复的操作一个事情,但所有的操作都是合法的(不断打开关闭视频刷视频),这也是一种反作弊。第二点说一下流量作弊的形式,一种是机器作弊:模仿投递日志,调用接口。有些数据并不是投递的,而是访问业务数据库,提供接口访问,这种也算为流量作弊;第二种是人工作弊:微信群,QQ群,由专人指导,专业APP,指导操作并与用户分成。这两种作弊的模式机器作弊的设定模式相对固定,短期效果明显,因为是机器循环操作,通过动态ip,而且速度比较快。人工欺诈模式不固定,效果与组织规模有关。

反作弊产业现状第一个就是难辨识,机器作弊越来越趋近现实,很具欺骗性。在平台和作弊方进行博弈的过程中就如同病毒一样不停成长,就很难防范。第二是成本低,动态代理IP获取容易,还有P2P机制的刷量软件(流量精灵),虽然我们平台能识别,但是如果是个小公司,一开始还是很难识别的。第三个就是行动快,非常的有组织有规模,不是某一个人某一台电脑下一个软件刷一下。

简单介绍一下其刷量模式,中间红色部分是流量欺诈平台,首先是制片方或渠道去流量欺诈平台购买流量,欺诈平台在网站视频刷流量,网站定期向渠道方支付流量分成。右边是网店向流量欺诈平台购买流量,平台刷网店商品,提高人气,这是两种比较直接的形式。还有就是直播刷人气,与网店模式差不多,还有就是网站刷广告等其他形式。网站刷广告形式是做了一个网站,让广告联盟向网站投广告,站长向欺诈平台买流量,带动广告量,广告联盟就会支付费用。
给行业带来的伤害直接就是经济损失,第二个就是正常用户对产品的判定标准失衡,如电商你都不知道产品是人评价还是机器评价。然后就是企业信誉受损,如票房十亿但是电影很烂,长此以往信誉就会受损。企业数据分析不准确,做商业分析时各种指标对不上。企业成本上升,如爱奇艺本来十台机器就能维护正常运维,但是一旦遇到刷量情况就无法承受,大量数据导致服务卡顿,因此服务器采购成本高。
数据是一个企业的核心资产,是一种生产物料,并且表达了一系列的行为。数据可以衍生出各式各样的产品,能够帮助用户提升用户体验,如可以基于数据做一些推荐产品。数据还能帮企业做一些决策、预测。如果数据质量不过关就会导致分析不准确。
从工程技术来看,流量反作弊是一个技术问题,机器生成的数据,算异常流量。从业务方面,只要分析师认为数据表象特征不具备规律性,算异常流量。总的来说两者结合都算异常流量。但是有一个特点,从工程师的角度,这个事一旦做完就完了,如数据加密过程,你在广告、评论都能应用。

接下来讲一下流量反作弊与数据清洗之间的关系。数据清洗更加关注的是字段是否存在,枚举值是否正确,该版本的投递是否注册并审核通过。我们数据平台对数据投递是有一套规范,必须在投递平台注册并审核通过,才会认为投递是真实合法的。流量反作弊更关注数据的特征是: 指标是否正常,硬件信息是否正确,业务之间特征数据关联是否合理,是否满足预测模型。
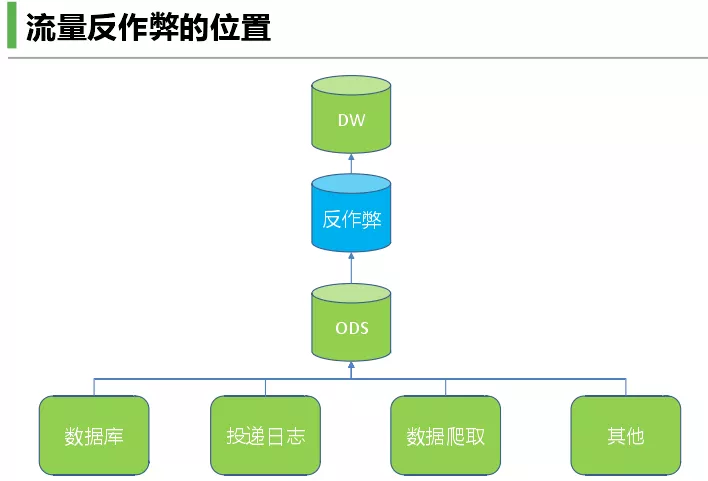
接下来说一下流量反作弊的位置,底下是各种数据源,然后将数据传到ODS上,ODS直接对接反作弊的各种技术。反作弊做的越前越好,损伤越少,因为拿到的数据是一致的。这里有两种输出方式,一种就是以黑名单方式或者几种黑名单的方式;另一种就是直接给业务方表格。我们主要采用第二种方式,加入我们以黑名单形式,A用户用来A黑名单,B用户用来B黑名单,而A和B不一致。但是反作弊最好是能拿到所有数据,因此我们给出所有数据。我们以现有数据做反作弊,但是有些机密数据是拿不到的,机密数据是以黑名单的形式给用户。
流量反作弊的难点有:被动防守,事后分析,而且不断迭代发生。业务场景复杂,没有通用模型。第三个就是持续维护旧规则,不断增加新规则。因为作弊和反作弊是一个攻防过程,需要依据作弊技术不断更新规则。

做流量反作弊需要提前做一些准备工作。第一个就是掌握投递的日志或者数据库中的元数据含义,这个不可或缺,是所有工作的前提。第二个掌握主体业务的工作模式和场景,如视频相关,需要了解播放器相关的场景和工作模式,信息流是怎样的。第三个是避免信息孤岛,必须找到所有相关联的信息。第四个是了解作弊的目的什么,从目的入手比较好操作。第五个是与业务部门良好的沟通,确认作弊的口径,并做好保密工作。需要沟通确定作弊口径,如视频需要给业务方解释不以视频观看为目的的流量都算是作弊流量。

认定为技术问题也是可以做的,一旦做完都可以用。具体方式有:做一些IP信誉机制,如果IP机制做好了,所有流量通过这个IP都是作弊流量。第二个安全画像,利用打分机制。第三个就是加密信息检测,运行起来所以机制都是一样的。然后是设备硬件信息检测,这是目前比较重要的机制,不管你是手机端的网页或是APP网页都能识别设备唯一ID。
认定为业务问题的解决办法分为两个方面,一个基于规则统计,一种是基于机器学习。机器学习优点可以实现十分复杂的逻辑,但是需要关注模型的选择和效果,缺点解释性比较差。统计有一个很好地解释性,但是缺点要求统计模型的复杂程度限制在一定范围内。能找一些特征,但是选择特征有限。
认定为业务问题的解决思路先建立一个指标库,指标库要足够强大,第二个就是业务数据的上下文分析,业务发生时日志文件记录上面发生了什么还有下面要发生什么。第三个是行为特征的分析,如用户先访问A再访问B,再访问C,但是它直接从A到C就不正常了。第四个是基于时间序列的分析,数据访问要符合一定的时间序列规则,如A-B-C不能C-B-A。

基于机器学习的反作弊思路是将数据从源日志中取出,进行数据清洗和抽样。然后做正反样例标定以及特征工程,然后将其放入标签库。分为测试集和训练集,然后进行模型训练,利用测试集进行模型评价,通过后构建特征库,进入反作弊服务体系。

机器学习最重要的就是特征工程,特征工程决定数据的天花板。如果特征工程好,模型一般也可以很好,但是如果特征工程不好模型再好一定不能做好。上图介绍了特征工程如何做、使用方案、专业评估,然后如何获取特征,这些特征如何称呼,还有特征预处理、分级以及做一些降维。然后就是模型训练,主要使用LR、RF、GBDT、XGBoost。
效果评估就是敏感数据更关注TP,因此精确率必须要好,否则就无法使用。还有一般数据,如F1,ROC,AUC。这些指标低点并不影响后续分析。业务不断维护旧规则创建新规则,对旧规则而言对作弊数据打标签,创建特征标签验证,基于作弊数据和标签进行分析,最后进行验证。比如今天做了一些反作弊,有两条规则都对数据进行验证,交集越来越大,最后一个包围另一个,那么被包围的规则就没有用了。
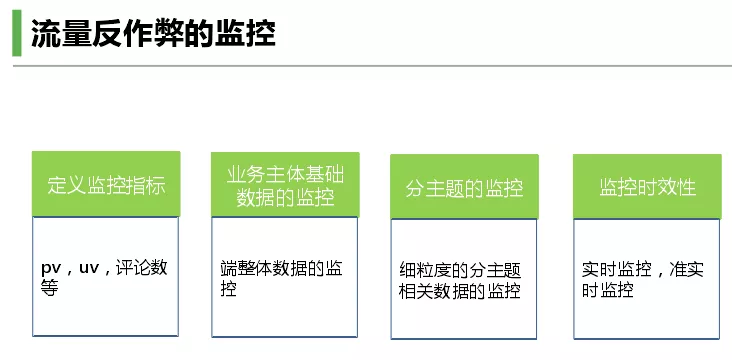
还有重要的一点是监控,如果被业务方反应已经很被动,需要在业务方发现之前解决。需要做一个监控提醒,首先定义定义监控指标(pv,uv,评论数等),业务主体基础数据的监控,端整体数据的监控。然后分主题监控,如细粒度的分主题相关数据的监控,还有一点是监控的时效性,需要实时监控,准实时监控。

从系统应用的角度看反作弊体系,反作弊离不开征信,首先确定征信对象,对于我们就是渠道征信。还有发展阶段,短期做什么,中期做什么,长期做什么。其价值就是做一些决策、信用监测以及成本节制。体系结构构件作弊与反作弊特征库,建立一些征信模型,建立信用评价体系然后做一些预测。
流量反作弊的服务应用第一个就是数据报表,具体有:内容流量&反作弊总体分析,单个内容流量&作弊情况查询,攻防效果分析,征信总体分析,单个征信对象信用报告查询智能分析。第二个智能分析,就是负责作弊识别-扣量-减付业务流程自动化, 作弊概率预测,异常预警,策略分析。第三个就是接口服务,反作弊结果以接口形式服务于各个业务。
未来展望在技术方面引入深度学习方法,蚕蛹模型融合技术,产品方面加快信用体系建设,形成产业联盟。
作者介绍
2014年加入爱奇艺,主要从事爱奇艺大数据平台搭建以及流量反作弊项目,见证了爱奇艺在流量反作弊、规范市场环境方面的发展历史,带领团队完成了流量反作弊的系统体系建设。
——END——