hadoop学习笔记之配置、三种模式配置及区别
目录
JDK、Hadoop安装、配置
本地模式(standalone operation)配置
实例1
实例2
伪分布式模式配置
本地运行
YARN上运行
三种模式区别
单机模式
伪分布式模式
完全分布式模式
JDK、Hadoop安装、配置
- 先去官网http://hadoop.apache.org/下载hadoop,我下的是hadoop2.5.2.tar.gz
- 去jdk官网下载jdk1.7 linux.tar.gz 或者百度网盘https://pan.baidu.com/s/1qWoS4ws
- 下载filezilla https://filezilla-project.org/download.php ,登录的时候端口号为22,主机位ip地址,将下载的hadoop和jdk复制到/opt/softwares里面。
- 打开虚拟机,打开Xshell5,输入su定位到根目录,rpm -qa|grep java 找到含java的文件,然后输入rpm -e --nodeps (……上面过滤的目录),强制删除这些文件。我的是这样的:


- cd到/opt/softwares,然后给此目录下所有文件用户权限加上可执行(x),

- 解压:

- 配置环境变量:新建一个xshell窗口,然后编辑/etc/profile

按G到达结尾,把刚才的安装的目录
/opt/modules/jdk1.7.0_79编辑进/etc/profile
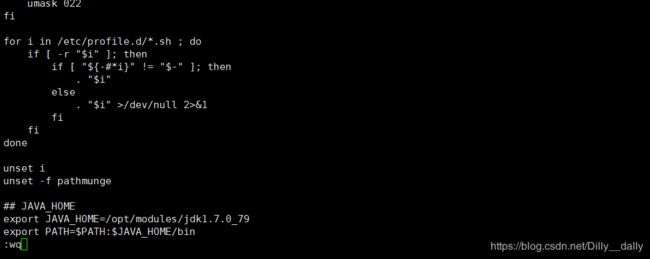
然后source一下生效,![]()
退出后重新连接 输入java -version验证是否配置成功:
hadoop配置操作类似:

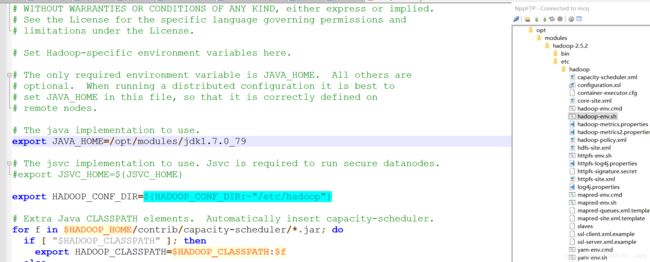
用notepad++连接虚拟机,如果第一次用可能要安装NppFTP插件,否则没有 ,配置文件就在图片灰色的hadoop下,然后
,配置文件就在图片灰色的hadoop下,然后
在hadoop下找到hadoop-env.sh用notepad++打开,输入echo ${JAVA_HOME} ,将得到的路径粘贴到下图位置:
本地模式(standalone operation)配置
定义:MapReduce程序运行在本地,启动JVM。
方法:
在hadoop-2.5.2目录下创建Input目录;
在input目录下创建某某.input;
在hadoop-2.5.2目录调用bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.2.jar 指令 input output ;
cat output/part-r-00000 查看结果集。
实例1
复制.xml文件到input中:

查询input里面含dfs加上a-z或.出现至少一次的字串,并把结果集输出到output里面:
![]()

如果是_SUCCESS则成功,_SUCCESS什么用都没有,只是起标识作用。这里part-r-00000就是结果集。

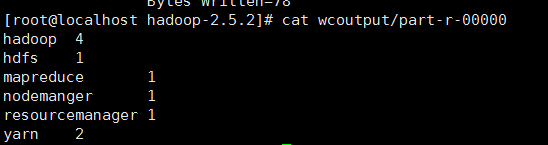
实例2
统计每个单词数量


![]()
伪分布式模式配置
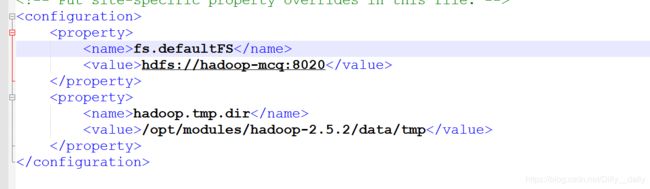
在etc/hadoop下找到core-site.xml,用notepad++打开,
![]() ,
,


在etc/hadoop找到hdfs-site.xml,用notepad++打开

本地运行
格式化:
![]()
启动:
启动成功:

hdfs web:在linux系统网页里输入主机名:50070,我的是:
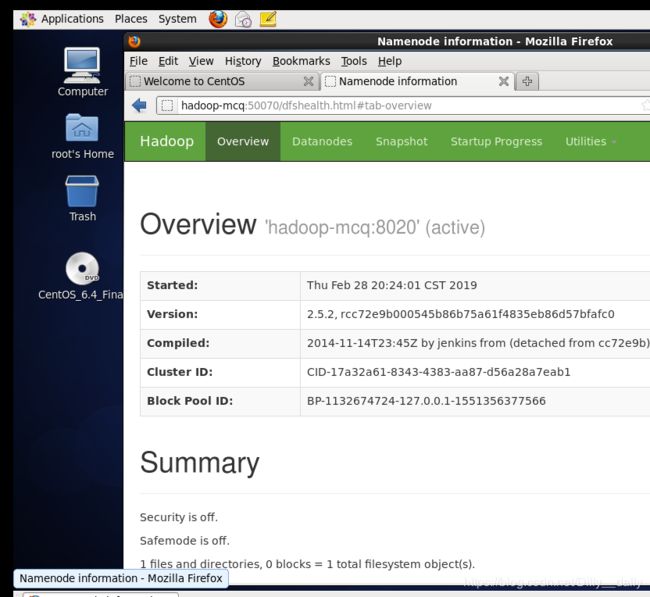
修改主机名看这个:https://jingyan.baidu.com/article/574c52192a1d8d6c8d9dc1ce.html
创建目录:![]()
从本地上传文件:
查看文件内容: 也可以通过web查看,utilities---browse the file system
也可以通过web查看,utilities---browse the file system
统计单词数量:
查看结果: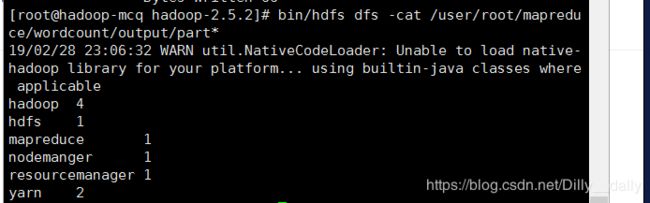 ,web上也有
,web上也有
YARN上运行
/etc/hadoop下找到 yarn-env.sh配置JAVA_HOME(通过echo $JAVA_HOME):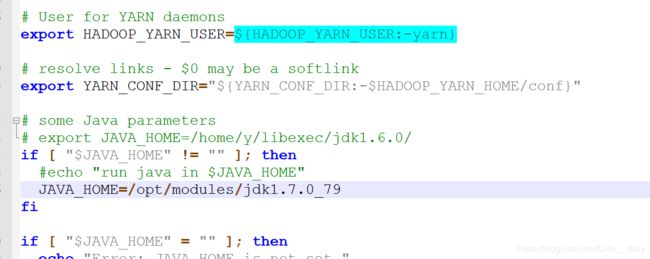
yarn-site.xml:
slaves:改成自己的主机名:
不用格式化,启动resourcemanager和nodemanager: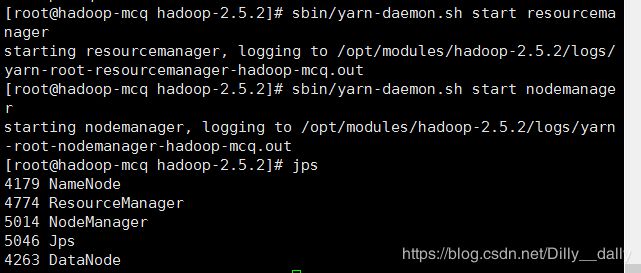
默认端口号8088,web打开方式:hadoop-mcq(主机名):8088
mapred-env.sh配置JAVA_HOME: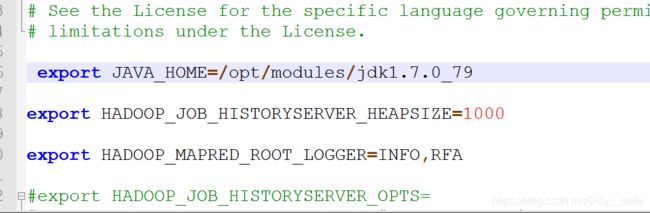
找到mapred-site.xml.template并重命名为mapred-site.xml,然后配置
先把以前的输出删掉: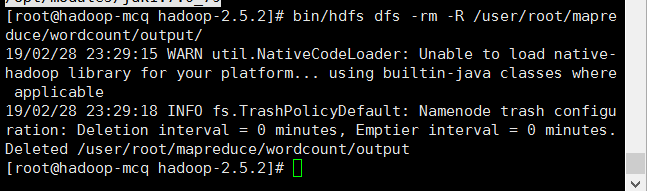
运行:
三种模式区别
单机模式
-默认模式。
-不对配置文件进行修改。
-使用本地文件系统,而不是分布式文件系统。
-Hadoop不会启动NameNode、DataNode、JobTracker、TaskTracker等守护进程,Map()和Reduce()任务作为同一个进程的不同部分来执行的。
-用于对MapReduce程序的逻辑进行调试,确保程序的正确。
伪分布式模式
-在一台主机模拟多主机。
-Hadoop启动NameNode、DataNode、JobTracker、TaskTracker这些守护进程都在同一台机器上运行,是相互独立的Java进程。
-在这种模式下,Hadoop使用的是分布式文件系统,各个作业也是由JobTraker服务,来管理的独立进程。在单机模式之上增加了代码调试功能,允许检查内存使用情况,HDFS输入输出,以及其他的守护进程交互。类似于完全分布式模式,因此,这种模式常用来开发测试Hadoop程序的执行是否正确。
-修改3个配置文件:core-site.xml(Hadoop集群的特性,作用于全部进程及客户端)、hdfs-site.xml(配置HDFS集群的工作属性)、mapred-site.xml(配置MapReduce集群的属性)
-格式化文件系统
完全分布式模式
-Hadoop的守护进程运行在由多台主机搭建的集群上,是真正的生产环境。
-在所有的主机上安装JDK和Hadoop,组成相互连通的网络。
-在主机间设置SSH免密码登录,把各从节点生成的公钥添加到主节点的信任列表。
-修改3个配置文件:core-site.xml、hdfs-site.xml、mapred-site.xml,指定NameNode和JobTraker的位置和端口,设置文件的副本等参数
-格式化文件系统