应用KNN算法识别手机传感器数据交通方式





def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = np.tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
#print(sortedDistIndicies)
#print(len(sortedDistIndicies))
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
voteIlabel=voteIlabel[0]####这一步不做就会报错
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#print('step:',i,' voteIlabel:',voteIlabel)
#print(classCount)
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
#print('result:',sortedClassCount[0][0])
return sortedClassCount[0][0]
def autoNorm(dataSet):
minVals = dataSet.min(axis=0)
maxVals = dataSet.max(axis=0)
ranges = maxVals - minVals
normDataSet = np.zeros(np.shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - np.tile(minVals, (m,1))
normDataSet = normDataSet/np.tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals
def TrafficClassTest():
normMat, ranges, minVals = autoNorm(data_xnew)
normMat1, ranges1, minVals1 = autoNorm(Data_xnew)
numTestVecs = Data_ynew.shape[0]
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat1[i,:],normMat,data_ynew,3)
print ("the classifier came back with: %d, the real answer is: %d" % (classifierResult,Data_ynew[i]))
if (classifierResult != Data_ynew[i]): errorCount += 1.0
print ("the total error rate is: %f" % (errorCount/float(numTestVecs)))

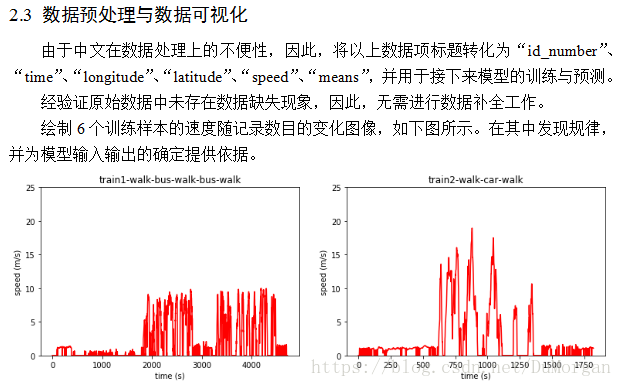
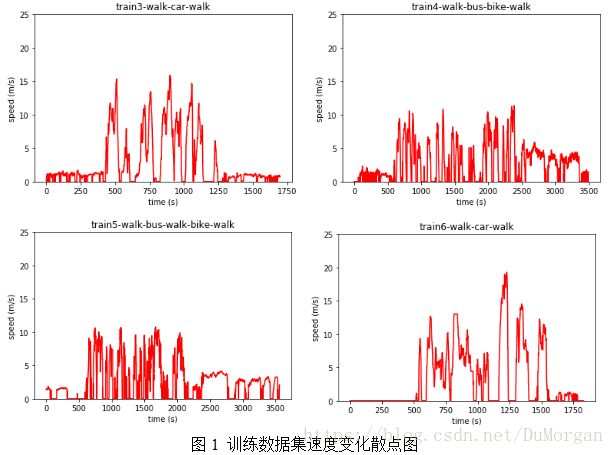
表1 识别率分布图
标签\预测 |
1:步行 |
2:自行车 |
3:公交车 |
4:小汽车 |
求和 |
1:步行 |
0.9767 |
0.0021 |
0.0163 |
0.0049 |
1.0000 |
2:自行车 |
0.0024 |
0.9904 |
0.0072 |
0.0000 |
1.0000 |
3:公交车 |
0.0230 |
0.0000 |
0.9641 |
0.0129 |
1.0000 |
4:小汽车 |
0.0138 |
0.0000 |
0.0453 |
0.9409 |
1.0000 |


附录程序源代码:
#-*- coding=utf-8 -*-
##一次平滑用于预测
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from collections import Counter
import operator
##定义用于将多维list整合成为1维list的函数
def flat(l):
for k in l:
if not isinstance(k, (list, tuple)):
yield k
else:
yield from flat(k)
SCALE = 60#定义SCALE长度,滚动每段数据实际为2SCALE长度
data_x=[]
data_y=[]#训练集
Data_x=[]
Data_y=[]#测试集
##定义文件读入函数
def choose_file(filenumber):
traindata = pd.read_excel('train%s.xlsx'%filenumber)
tempspeed=[]
tempfirstplant=[]
tempmeans=[]
tempspeed.append(list(traindata['speed']))
tempmeans.append(list(traindata['means']))
tempfirstplant.append(list(traindata['firstplant']))
tempspeed = list(flat(tempspeed))
tempmeans = list(flat(tempmeans))
tempfirstplant=list(flat(tempfirstplant))
for i in range(SCALE):#每个文件前SCALE个数据的读入
speed=np.array(tempspeed[0 : i+SCALE])
speed_in=tempspeed[i]
firstplant=tempfirstplant[i]
mean_speed=speed.mean()
max_speed=speed.max()
std_speed=speed.std()
data_x.append(list([speed_in,firstplant,mean_speed,max_speed,std_speed]))
data_y.append(list([tempmeans[i]]))
for i in range(SCALE,(len(tempspeed)-SCALE)):#每个文件可以正常选择SCALE的数据的读入
speed = np.array(tempspeed[i-SCALE : i+SCALE])
speed_in=tempspeed[i]
firstplant=tempfirstplant[i]
mean_speed=speed.mean()
max_speed=speed.max()
std_speed=speed.std()
data_x.append(list([speed_in,firstplant,mean_speed,max_speed,std_speed]))
data_y.append(list([tempmeans[i]]))
for i in range((len(tempspeed)-SCALE),len(tempspeed)):#每个文件尾部的SCALE个数据的读入
speed=np.array(tempspeed[i-SCALE:(len(tempspeed))])
speed_in=tempspeed[i]
firstplant=tempfirstplant[i]
mean_speed=speed.mean()
max_speed=speed.max()
std_speed=speed.std()
data_x.append(list([speed_in,firstplant,mean_speed,max_speed,std_speed]))
data_y.append(list([tempmeans[i]]))
return data_x,data_y#返回用于训练模型的x和y
##读入5个出行个体的训练文件
l=[1,2,3,4,5,6]
for i in l:
choose_file(i)
data_y=np.array(data_y)
import random
a=range((len(data_x)))
b=random.sample(a,int(0.8*len(data_x)))
c=list(set(a).difference(set(b)))
data_xnew=[]
data_ynew=[]
Data_xnew=[]
Data_ynew=[]
for i in b:
data_xnew.append(data_x[i])
data_ynew.append(data_y[i])
for i in c:
Data_xnew.append(data_x[i])
Data_ynew.append(data_y[i])
data_xnew=np.array(data_xnew)
data_ynew=np.array(data_ynew)
Data_xnew=np.array(Data_xnew)
Data_ynew=np.array(Data_ynew)
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = np.tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
#print(sortedDistIndicies)
#print(len(sortedDistIndicies))
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
voteIlabel=voteIlabel[0]####这一步不做就会报错
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#print('step:',i,' voteIlabel:',voteIlabel)
#print(classCount)
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
#print('result:',sortedClassCount[0][0])
return sortedClassCount[0][0]
def autoNorm(dataSet):
minVals = dataSet.min(axis=0)
maxVals = dataSet.max(axis=0)
ranges = maxVals - minVals
normDataSet = np.zeros(np.shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - np.tile(minVals, (m,1))
normDataSet = normDataSet/np.tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals
CLASSFIERRESULT=[]
def TrafficClassTest():
normMat, ranges, minVals = autoNorm(data_xnew)
normMat1, ranges1, minVals1 = autoNorm(Data_xnew)
numTestVecs = Data_ynew.shape[0]
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat1[i,:],normMat,data_ynew,3)
CLASSFIERRESULT.append(classifierResult)
#print ("the classifier came back with: %d, the real answer is: %d" % (classifierResult, Data_ynew[i]))
if (classifierResult != Data_ynew[i]): errorCount += 1.0
print ("the total error rate is: %f" % (errorCount/float(numTestVecs)))
print(errorCount,numTestVecs)
TrafficClassTest()
CLASSFIERRESULT = np.array(CLASSFIERRESULT)
#Data_ynew标签(真实)true;CLASSFIERRESULT预测pre
count1,count2,count3,count4=0,0,0,0
true_walk = Data_ynew[Data_ynew==1].shape[0]
true_walk_index = np.argwhere(Data_ynew==1)[:,0]
for o in true_walk_index:
if CLASSFIERRESULT[o]==1:
count1+=1
elif CLASSFIERRESULT[o]==2:
count2+=1
elif CLASSFIERRESULT[o]==3:
count3+=1
elif CLASSFIERRESULT[o]==4:
count4+=1
else:pass
w_w,w_b,w_s,w_c=count1/true_walk,count2/true_walk,count3/true_walk,count4/true_walk
count1,count2,count3,count4=0,0,0,0
true_bike = Data_ynew[Data_ynew==2].shape[0]
true_bike_index = np.argwhere(Data_ynew==2)[:,0]
for o in true_bike_index:
if CLASSFIERRESULT[o]==1:
count1+=1
elif CLASSFIERRESULT[o]==2:
count2+=1
elif CLASSFIERRESULT[o]==3:
count3+=1
elif CLASSFIERRESULT[o]==4:
count4+=1
else:pass
b_w,b_b,b_s,b_c=count1/true_bike,count2/true_bike,count3/true_bike,count4/true_bike
count1,count2,count3,count4=0,0,0,0
true_bus = Data_ynew[Data_ynew==3].shape[0]
true_bus_index = np.argwhere(Data_ynew==3)[:,0]
for o in true_bus_index:
if CLASSFIERRESULT[o]==1:
count1+=1
elif CLASSFIERRESULT[o]==2:
count2+=1
elif CLASSFIERRESULT[o]==3:
count3+=1
elif CLASSFIERRESULT[o]==4:
count4+=1
else:pass
s_w,s_b,s_s,s_c=count1/true_bus,count2/true_bus,count3/true_bus,count4/true_bus
count1,count2,count3,count4=0,0,0,0
true_car = Data_ynew[Data_ynew==4].shape[0]
true_car_index = np.argwhere(Data_ynew==4)[:,0]
for o in true_car_index:
if CLASSFIERRESULT[o]==1:
count1+=1
elif CLASSFIERRESULT[o]==2:
count2+=1
elif CLASSFIERRESULT[o]==3:
count3+=1
elif CLASSFIERRESULT[o]==4:
count4+=1
else:pass
c_w,c_b,c_s,c_c=count1/true_car,count2/true_car,count3/true_car,count4/true_car
print('line1',w_w,w_b,w_s,w_c)
print('line2',b_w,b_b,b_s,b_c)
print('line3',s_w,s_b,s_s,s_c)
print('line4',c_w,c_b,c_s,c_c)