基于Keras mnist手写数字识别---Keras卷积神经网络入门教程
目录
- 1、一些说明
- 2、常量定义
- 3、工具函数
- 4、模型定义以及训练
- 4.1、导入库
- 4.2、主入口
- 4.3、主函数
- 4.3.1、获取训练数据
- 4.3.1、定义模型
- 4.3.2、编译模型
- 4.3.3、训练模型
- 4.3.4、评估以及保存模型
- 4.3.5、预测单张图片
1、一些说明
本博客是参考Tensorflow官方的使用Tensorflow实现的mnist手写数字识别例子,使用Tensorflow内置的keras实现的mnist,获得了和原有用tensorflow编写的代码相当的性能。本文也可以作为真正意义上使用Keras实现的卷积神经网络入门Demo。参考连接如下:
- Tensorflow keras入门教程。
- Tensorflow mnist官方Demo。
- 本文项目代码。
项目目录结构如下
mnist-keras
---data/ 存放的是下载的数据集
---logs/ 存放tensorflow日志
---constants.py 定义常量
---test.py 载入模型预测单张图片
---train.py 主文件,模型定义以及训练
---utils.py 定义工具函数
关于tensorflow的数据预处理,特别是图像预处理,可参考博客:
- tf.data.Dataset图像预处理详解 。
- Tensorflow数据输入—TFRecords详解\TFRecords图像预处理 。
2、常量定义
constants.py如下
# coding=utf-8
# 全局变量定义
# CVDF mirror of http://yann.lecun.com/exdb/mnist/
SOURCE_URL = 'http://yann.lecun.com/exdb/mnist/'
# 指定工作目录,数据集就会保存在这里
WORK_DIRECTORY = 'data'
# 图像的大小
IMAGE_SIZE = 28
# 图像的通道数,为1,即为灰度图像
NUM_CHANNELS = 1
# 图像想素值的范围
PIXEL_DEPTH = 255
# 分类数目,0~9总共有10类
NUM_LABELS = 10
# 验证集大小
VALIDATION_SIZE = 5000 # Size of the validation set.
# 种子
SEED = 66478 # Set to None for random seed.
# 批次大小
BATCH_SIZE = 64
# 训练多少个epoch
NUM_EPOCHS = 10
# 验证集大小
EVAL_BATCH_SIZE = 64
3、工具函数
我把原来在convolutional.py中的部分工具函数移动到了utils.py这个文件里面,使主文件(train.py)更加简洁。知道每个函数的功能就行。utils.py如下
# coding=utf-8
# 兼容python3
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import gzip
import os
import numpy
import tensorflow as tf
from six.moves import urllib
from six.moves import xrange # pylint: disable=redefined-builtin
from constants import *
def data_type(argv):
"""根据argv.use_fp16返回是否使用半精度"""
if argv.use_fp16:
return tf.float16
else:
return tf.float32
def maybe_download(filename):
"""
如果没有下载文件filename,那么把文件下载到WORK_DIRECTORY
"""
if not tf.gfile.Exists(WORK_DIRECTORY):
tf.gfile.MakeDirs(WORK_DIRECTORY)
filepath = os.path.join(WORK_DIRECTORY, filename)
if not tf.gfile.Exists(filepath):
filepath, _ = urllib.request.urlretrieve(SOURCE_URL + filename, filepath)
with tf.gfile.GFile(filepath) as f:
size = f.size()
print('Successfully downloaded', filename, size, 'bytes.')
return filepath
def extract_data(filename, num_images):
"""
解压filename指定的图像数据集为4D tensor [num_images, y, x, channels]。
图像的值从[0, 255]被缩放到了[-0.5, 0.5]。
"""
print('Extracting', filename)
with gzip.open(filename) as bytestream:
bytestream.read(16)
buf = bytestream.read(IMAGE_SIZE * IMAGE_SIZE * num_images * NUM_CHANNELS)
data = numpy.frombuffer(buf, dtype=numpy.uint8).astype(numpy.float32)
data = (data - (PIXEL_DEPTH / 2.0)) / PIXEL_DEPTH
data = data.reshape(num_images, IMAGE_SIZE, IMAGE_SIZE, NUM_CHANNELS)
return data
def extract_labels(filename, num_images):
"""把标签解压为一个int64的向量。"""
print('Extracting', filename)
with gzip.open(filename) as bytestream:
bytestream.read(8)
buf = bytestream.read(1 * num_images)
labels = numpy.frombuffer(buf, dtype=numpy.uint8).astype(numpy.int64)
return labels
def fake_data(num_images):
"""生成MNIST需要的假的数据集。"""
data = numpy.ndarray(
shape=(num_images, IMAGE_SIZE, IMAGE_SIZE, NUM_CHANNELS),
dtype=numpy.float32)
labels = numpy.zeros(shape=(num_images,), dtype=numpy.int64)
for image in xrange(num_images):
label = image % 2
data[image, :, :, 0] = label - 0.5
labels[image] = label
return data, labels
def error_rate(predictions, labels):
"""返回错误率"""
return 100.0 - (
100.0 *
numpy.sum(numpy.argmax(predictions, 1) == labels) /
predictions.shape[0])
4、模型定义以及训练
接下来讲train.py这个文件,因为是模型定义以及训练模型的文件,我会讲的详细些。
4.1、导入库
# coding=utf-8
# 兼容python3
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import argparse
import scipy
# 从tensorflow里导入keras和keras.layer
from tensorflow import keras
from tensorflow.keras import layers
# 导入工具函数
from utils import *
4.2、主入口
解析参数use_fp16和self_test,用到是ArgumentParser,就不详细解释了。
if __name__ == '__main__':
# 定义parser
parser = argparse.ArgumentParser()
parser.add_argument(
'--use_fp16',
default=False,
help='Use half floats instead of full floats if True.',
action='store_true')
parser.add_argument(
'--self_test',
default=False,
action='store_true',
help='True if running a self test.')
# 解析参数
FLAGS, unparsed = parser.parse_known_args()
# 调用主函数
main(FLAGS)
4.3、主函数
4.3.1、获取训练数据
def main(argv=None):
if argv.self_test:
"""
为了测试模型是否可以运行,生成了一些随机数据集。
"""
print('Running self-test...')
# 生成训练集
train_data, train_labels = fake_data(256)
# 生成验证集
validation_data, validation_labels = fake_data(EVAL_BATCH_SIZE)
# 生成测试集
test_data, test_labels = fake_data(EVAL_BATCH_SIZE)
# 只训练一个epoch
num_epochs = 1
else:
"""
准备手写数字数据集。
"""
# 下载数据集
train_data_filename = maybe_download('train-images-idx3-ubyte.gz')
train_labels_filename = maybe_download('train-labels-idx1-ubyte.gz')
test_data_filename = maybe_download('t10k-images-idx3-ubyte.gz')
test_labels_filename = maybe_download('t10k-labels-idx1-ubyte.gz')
# 把下载的数据解压为numpy数组
train_data = extract_data(train_data_filename, 60000)
train_labels = extract_labels(train_labels_filename, 60000)
test_data = extract_data(test_data_filename, 10000)
test_labels = extract_labels(test_labels_filename, 10000)
# 分割train_data与train_labels,得到训练集以及验证集
validation_data = train_data[:VALIDATION_SIZE, ...]
validation_labels = train_labels[:VALIDATION_SIZE]
train_data = train_data[VALIDATION_SIZE:, ...]
train_labels = train_labels[VALIDATION_SIZE:]
num_epochs = NUM_EPOCHS
# 保存一下第一张图片,用来测试
img0 = test_data[0]
# 因为test_data被缩放到了-0.5~0.5,所以要恢复到原来的范围[0, 255]
img0 = img0*PIXEL_DEPTH+PIXEL_DEPTH/2
# 保存
cv2.imwrite('test0.png', img0)
# 对label进行one-hot编码,因为模型的最后一层有10个输出单元(10个类别)
train_labels = keras.utils.to_categorical(train_labels)
validation_labels = keras.utils.to_categorical(validation_labels)
test_labels = keras.utils.to_categorical(test_labels)
4.3.1、定义模型
在 Tensorflow mnist官方Demo中的手写数字识别的网络结构如下(从下往上看)。最下的那个是输入input(定义了每张图的大小和通道),然后依次是卷积层conv1、池化层pool1、conv2、pool2,接着是一个flatten层(把pool2之后输出展开为一维向量),然后全连接层fc1,然后是一个dropout层(在调用evalute和predict时自动失效),fc2,最后是softmax层。
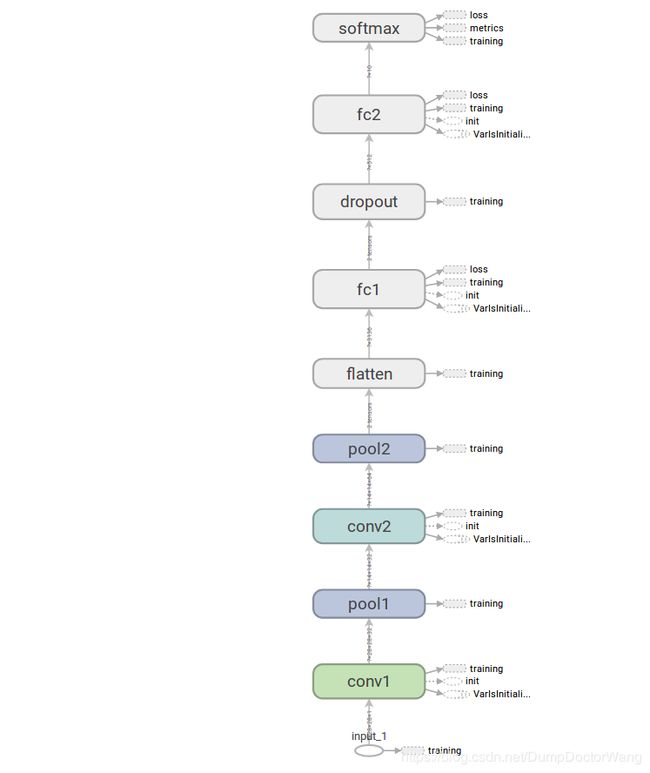
模型的主要参数如下:
| Name | Output shape | Kernel size | Kernel count | Strides | Activation | Padding | Use bias |
|---|---|---|---|---|---|---|---|
| input_1 | (None, 28, 28, 1) | ||||||
| conv1 | (None, 28, 28, 32) | (5, 5) | 32 | (1, 1) | relu | same | True |
| pool1 | (None, 14, 14, 32) | (2, 2) | (2, 2) | same | |||
| conv2 | (None, 14, 14, 64) | (5, 5) | 64 | (1, 1) | relu | same | True |
| pool2 | (None, 7, 7, 64) | (2, 2) | (2, 2) | same | |||
| flatten | (None, 3136) | ||||||
| fc1 | (None, 512) | relu | True | ||||
| fc2 | (None, 10) | ||||||
| softmax | (None, 10) |
实现模型的代码如下:
def inference(dtype):
"""
使用keras定义mnist模型
"""
# define a truncated_normal initializer
tn_init = keras.initializers.truncated_normal(0, 0.1, SEED, dtype=dtype)
# define a constant initializer
const_init = keras.initializers.constant(0.1, dtype)
# define a L2 regularizer
l2_reg = keras.regularizers.l2(5e-4)
# inputs: shape(None, 28, 28, 1)
inputs = layers.Input(shape=(IMAGE_SIZE, IMAGE_SIZE, NUM_CHANNELS), dtype=dtype)
# conv1: shape(None, 28, 28, 32)
conv1 = layers.Conv2D(32, (5, 5), strides=(1, 1), padding='same',
activation='relu', use_bias=True,
kernel_initializer=tn_init, name='conv1')(inputs)
# pool1: shape(None, 14, 14, 32)
pool1 = layers.MaxPool2D(pool_size=(2, 2), strides=(2, 2), padding='same', name='pool1')(conv1)
# conv2: shape(None, 14, 14, 64)
conv2 = layers.Conv2D(64, (5, 5), strides=(1, 1), padding='same',
activation='relu', use_bias=True,
kernel_initializer=tn_init,
bias_initializer=const_init, name='conv2')(pool1)
# pool2: shape(None, 7, 7, 64)
pool2 = layers.MaxPool2D(pool_size=(2, 2), strides=(2, 2), padding='same', name='pool2')(conv2)
# flatten: shape(None, 3136)
flatten = layers.Flatten(name='flatten')(pool2)
# fc1: shape(None, 512)
fc1 = layers.Dense(512, 'relu', True, kernel_initializer=tn_init,
bias_initializer=const_init, kernel_regularizer=l2_reg,
bias_regularizer=l2_reg, name='fc1')(flatten)
# dropout
dropout1 = layers.Dropout(0.5, seed=SEED)(fc1)
# dense2: shape(None, 10)
fc2 = layers.Dense(NUM_LABELS, activation=None, use_bias=True,
kernel_initializer=tn_init, bias_initializer=const_init, name='fc2',
kernel_regularizer=l2_reg, bias_regularizer=l2_reg)(dropout1)
# softmax: shape(None, 10)
softmax = layers.Softmax(name='softmax')(fc2)
# make new model
model = keras.Model(inputs=inputs, outputs=softmax, name='nmist')
return model
接下来对上面用到的函数进行一些说明:
- Conv2D:Keras的卷积可由这一个函数完成,参数包含了一层的所需要的所有参数。主要参数如下
- filters: 整数。指定卷积核(在Keras中对应的概念为kernel,在tesorflow中为weights)的个数。这个数目也是本层输出shape的最后一个元素大小。
- kernel_size: 一个整数(2D卷积窗口的宽和高均为这个整数)或者两个整数组成的列表(分别指定2D卷积窗口的高和宽)。和tensorflow不同的是,这里指定卷积核大小时,只需要指定2D卷积窗口的宽和高,而不需要指定卷积核的第三个维度的大小(卷积核第三个维度的大小和输入的shape的最后一个元素相同);例如,在tensorflow中,一个图像批次(batch)的shape为(16,28,28,1),卷积核的个数32,卷积核的大小为5,那么,卷积核的shape需要为(32,5,5,1);在Keras中,32应该是第一个参数的值,(5,5)是kernel_size的值,而1,会根据输入(16,28,28,1)的最后一个元素自动推算为1(相等)。
- strides: 一个整数(strides的宽和高均为这个整数)或者两个整数组成的列表(分别strides的高和宽)。对于Conv2D,strides也只需要指定宽和高。
- padding: “valid” 或者 “same”。 请参考吴恩达的卷积神经网络课程。
- data_format: 字符串。 “channels_last” 或者 “channels_first”。如果是"channels_last"(默认),那么,输入数据的shape为(batch_size, height, width, channels);如果为"channels_first",那么输入数据为shape为(batch_size, channels, height, width)。这个参数就是指定通道数的位置。
- dilation_rate: 请参考官方文档。
- activation: 此层使用的激活函数的名称。不指定的话就不使用激活函数。
- use_bias: 布尔值。是否使用bias。
- kernel_initializer: 指定kernel_initializer。参见: initializers。
- bias_initializer: 指定bias_initializer。参见: initializers。
- kernel_regularizer: 指定kernel_regularizer。参见regularizer。
- bias_regularizer: 指定bias_regularizer。参见regularizer。
- activity_regularizer: 请参考官方文档。
- kernel_constraint: 请参考官方文档。
- bias_constraint:请参考官方文档。
其他函数请自行查阅文档,反正定义模型是要比tensorflow简单多了。
4.3.2、编译模型
# 获取模型
model = inference(data_type(argv))
# 打印模型的信息
model.summary()
# 编译模型;第一个参数是优化器;第二个参数为loss,因为是多元分类问题,固为
# 'categorical_crossentropy';第三个参数为metrics,就是在训练的时候需
# 要监控的指标列表。
model.compile(optimizer=keras.optimizers.SGD(lr=0.01, momentum=0.9, decay=1e-5),
loss='categorical_crossentropy', metrics=['accuracy'])
4.3.3、训练模型
# 设置回调
callbacks = [
# 把TensorBoard的日志写入文件夹'./logs'
keras.callbacks.TensorBoard(log_dir='./logs'),
]
# 开始训练
model.fit(train_data, train_labels, BATCH_SIZE, epochs=num_epochs,
validation_data=(validation_data, validation_labels), callbacks=callbacks)
4.3.4、评估以及保存模型
# evaluate
print('', 'evaluating on test sets...')
loss, accuracy = model.evaluate(test_data, test_labels)
print('test loss:', loss)
print('test Accuracy:', accuracy)
# save model
model.save('mnist-model.h5')
4.3.5、预测单张图片
test.py如下
# coding=utf-8
# 兼容python3
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import cv2
import numpy as np
from tensorflow import keras
if __name__ == '__main__':
# 读图片
img0 = cv2.imread('test0.png', cv2.IMREAD_UNCHANGED)
print(img0.shape)
# 扩展维度为4维,因为模型的输入需要是4维
img0 = np.resize(img0, (1, img0.shape[0], img0.shape[1], 1))
print(img0.shape)
# 恢复模型以及权重
model = keras.models.load_model('mnist-model.h5')
# 获取模型最后一层,也就是softmax层的输出,输出的shape为(1, 10)
last_layer_output = model.predict(img0)
# 获取最大值的索引
max_index = np.argmax(last_layer_output, axis=-1)
print('predict number: %d' % (int(max_index[0])))
print('probability: ', last_layer_output[0][max_index])
、