- 关于城市旅游的HTML网页设计——(旅游风景云南 5页)HTML+CSS+JavaScript
二挡起步
web前端期末大作业javascripthtmlcss旅游风景
⛵源码获取文末联系✈Web前端开发技术描述网页设计题材,DIV+CSS布局制作,HTML+CSS网页设计期末课程大作业|游景点介绍|旅游风景区|家乡介绍|等网站的设计与制作|HTML期末大学生网页设计作业,Web大学生网页HTML:结构CSS:样式在操作方面上运用了html5和css3,采用了div+css结构、表单、超链接、浮动、绝对定位、相对定位、字体样式、引用视频等基础知识JavaScrip
- HTML网页设计制作大作业(div+css) 云南我的家乡旅游景点 带文字滚动
二挡起步
web前端期末大作业web设计网页规划与设计htmlcssjavascriptdreamweaver前端
Web前端开发技术描述网页设计题材,DIV+CSS布局制作,HTML+CSS网页设计期末课程大作业游景点介绍|旅游风景区|家乡介绍|等网站的设计与制作HTML期末大学生网页设计作业HTML:结构CSS:样式在操作方面上运用了html5和css3,采用了div+css结构、表单、超链接、浮动、绝对定位、相对定位、字体样式、引用视频等基础知识JavaScript:做与用户的交互行为文章目录前端学习路线
- nosql数据库技术与应用知识点
皆过客,揽星河
NoSQLnosql数据库大数据数据分析数据结构非关系型数据库
Nosql知识回顾大数据处理流程数据采集(flume、爬虫、传感器)数据存储(本门课程NoSQL所处的阶段)Hdfs、MongoDB、HBase等数据清洗(入仓)Hive等数据处理、分析(Spark、Flink等)数据可视化数据挖掘、机器学习应用(Python、SparkMLlib等)大数据时代存储的挑战(三高)高并发(同一时间很多人访问)高扩展(要求随时根据需求扩展存储)高效率(要求读写速度快)
- 2021-07-31
比峰
七月的最后一天,过了今天,就是八月,心脏在颤抖……昨天两点半才睡,一直在以两倍的语速的听之前的课程,虽然隔得时间不长,但是很多知识点已经忘了差不多了,为了让自己能够掌握的稍微全面一点,还是磨刀不误砍柴工的比较好。正因为晚上睡得晚,今天一上午的状态都不好,也可能因为上午都是待在家里,所以多数时间自己是在补觉。既然太累,那就睡觉吧,总比浪费时间的好。下午到咖啡馆做题,一道差错更正一下子让自己的实力暴露
- 2023-08-08
2023梦启支教团张牧泽
学汉字历史,行传统书法——中国矿业大学梦启支教团梦启三班开展书法文化课7月20日上午8时,中国矿业大学梦启支教团在贵州省金沙县西洛街道彩虹小学开展了“书法文化”课程。该课程意在向孩子们传授汉字演变的相关知识,围绕书法发展历史讲解不同时期的字形字体特点。此课程由梦启支教团成员王耀民讲授,梦启三班全体成员参加。中国文字的发展有数千年的历史,从早期雏形的象形文字到殷商时期的甲骨文、金文,再到西周、秦朝的
- 今日有感,坚持分享第913天,2019.07.13
ZAF峰回路转
本周是假日里最忙碌的一周,连续四天晚上的课程,让我感觉到身体明显透支。昨天晚上读书会结束回到家,已经是十点半之后啦,忽然感觉身体不舒服,勉强支撑着洗漱完毕,没等上床休息,强烈的不适感警告我该吃药啦!感谢老公半夜到医院給我抓了药,今天早上当我对老公表达谢意的时候,老公说,不用感谢,我不是一直都是这样做的吗?多少年啦,今天竟然还谢谢!老公说的没错,可是以前总感觉那是他应该做的,如今感觉到,身边有一个在
- 趁吾身未老
逍遥书生111
趁吾身未老池非2020年,一场突如其来的新冠脑炎疫情,打破了原有的状态。工作与生活的轨迹发生了不确定的变化。01因为隔离防疫,正常的教学不能进行,线上网课成为教学的新形式,年过五十的我面对新的教学形式有些应不暇。只得退而求次,不再负责高考班级的课程。这样,就不用上网课做直播了。感觉很轻松很闲的同时,也感觉到了英雄迟暮。不得不承认,老了。该交班了。因为不能出门,整天呆在家里,一开始还很兴奋,终于可以
- Armv8.3 体系结构扩展--原文版
代码改变世界ctw
ARM-TEE-Androidarmv8嵌入式arm架构安全架构芯片TrustzoneSecureboot
快速链接:.ARMv8/ARMv9架构入门到精通-[目录]付费专栏-付费课程【购买须知】:个人博客笔记导读目录(全部)TheArmv8.3architectureextensionTheArmv8.3architectureextensionisanextensiontoArmv8.2.Itaddsmandatoryandoptionalarchitecturalfeatures.Somefeat
- 2021-07-09
2018心如止水
张雲芳焦点解决网络课程学习坚持分享第816天20210709本周第2次(约练总291)渴了喝水;饿了吃饭;累了休息。看似简单的选择与行为,做起来却没那么容易。尤其是作为成年人,每天有工作需要完成,有孩子、家人需要陪伴,有时候各种事情赶在一起,忙的晕头转向、焦头烂额,即使自己特别累,也没有间隙去休息一下下,想象一下身体疲惫,精力耗竭是什么样的状态?对于孩子的哭闹你还会有更多的耐心吗?我想多数情况下都
- Python 课程10-单元测试
可愛小吉
Python教學python单元测试开发语言TDDunittest
前言在现代软件开发中,单元测试已成为一种必不可少的实践。通过测试,我们可以确保每个功能模块在开发和修改过程中按预期工作,从而减少软件缺陷,提高代码质量。而测试驱动开发(TDD)则进一步将测试作为开发的核心部分,先编写测试,再编写代码,以测试为指导开发出更稳定、更可靠的代码。Python提供了强大的unittest模块,它是Python标准库的一部分,专门用于编写和执行单元测试。与其他测试框架相比,
- 2022-05-22光印随思60学习要与现实打通
无名之米8
20220522光印随思60学习要与现实打通今天在匆忙中完成了新网师课程的第七次预习作业。每次完成预习作业的过程都是一次艰难的学习,先要学习相关的文本和文件,了解作业需要的理论知识,之后需要把理论知识运用于实际工作和生活中。这也是学习的真正价值所在。在很多时候,会有这样的感觉,读了很多书为什么没有啥长进?现在回想应该就是,当只有阅读和感受,没有把阅读心得转化为文字,没有把阅读的知识运用到实际的场景
- 微信小程序开发注意事项
jun778895
微信小程序小程序
微信小程序开发是一个融合了前端开发、用户体验设计、后端服务(可选)以及微信小程序平台特性的综合性项目。这里,我将详细介绍一个典型的小程序开发项目的全过程,包括项目规划、设计、开发、测试及部署上线等各个环节,并尽量使内容达到或超过2000字的要求。一、项目规划1.1项目背景与目标假设我们要开发一个名为“智慧校园助手”的微信小程序,旨在为学生提供一站式校园生活服务,包括课程表查询、图书馆座位预约、食堂
- 承担即成长
吉林付巍巍
《苏霍姆林斯基教育学》课程,几天前召开了义工培训会,我听了回放后主动联系郑老师要求加入义工团队。虽然这样每周要付出至少一天的时间进行打卡阅读和点评,但这样可以强迫规划好每日的作息时间,完成专业阅读方面的学习,这种重要的事情是必须要融入日常的生活中的,这一工作的申请也督促我合理安排自己的时间,把碎片化的时间整合好,无形中提高了每日利用时间的效率。上学期跟随着教师阅读地图课程组进行点评,发现了许多优秀
- 家庭教育,先家庭后教育:家庭是硬件,教育是软件
唯唯育家
很多家长为孩子付出很多,也学习很多家庭教育课程,看很多家庭教育书籍,为什么还是教育孩子很困难?因为主次颠倒,没有抓住家庭教育的主干!家庭教育,很多家长只行使“教育”功能,忽视了“家庭”功能!家长总想着怎么教孩子,怎么教育孩子!如果单靠教育,就能把孩子教好,学校老师在教育方面比家长在行,孩子应该在学校就被教好了,哪还需要家庭教育?为什么只有学校教育不够,还需要家庭教育?家庭教育的主要功能不在“教育”
- 2023-04-18
夕彦
躺在不想起,给自己找起来的理由care,照顾自己的身体心情和家人,安好连接和共创课程设计,会议和督导
- 教师资格考试中学《教育知识与能力》知识点|高频考点汇总
小山丘
温馨提示:更多汇总详情留言小编哦!!!认知过程之易混知识点剖析社会中心课程论情绪——重要考点皮亚杰教你带孩子斯金纳强化规律你的心理足够强大吗?教育心理学的效应德育有规律常考人物思想之夸美纽斯中学常考教学原则孔子及《论语》中的重要教育思想教育学创立阶段人物之赫尔巴特学习策略分类知识点梳理教师资格证辨析题作答思路综合课程的类型班杜拉的学习理论马斯洛需要层次理论记忆类型的四大分类柏拉图和他的《理想国》感
- 第二阶段学习的第二次复盘
蓝色沫
【昵称】蓝色,沫【我的技能】第二阶段所学内容中,我学习了如何学好爆款标题,如何写好开头和结尾,如何写好媒体文等等。【我要发问】第二阶段学习的内容中,没能掌握好写媒体文。【我的闪光点】第二阶段做的好的地方,有按时完成作业,以及认真听视频课,在课程中,明白了怎样去写好开头和结尾,怎样写出爆款标题等。【不足之处】没能掌握好写媒体文。关于写好媒体文,有些吃力,针对写三至五个小标题,以及写好媒体文框架还存在
- 越长大越孤单
换个时间就好
“于今之世,孰是真身”。意思是:在今天的社会,谁是真正的自己。第一次有这种感受是在初二初三,当时平凡的我只想平凡的走完我的初中时代,不想有变故,不想多新朋友,也不想成为别人的新朋友。在数着教室里那张被多数人期待的,挂在教室后方的钟表,铃声响起结束一天百般无聊的课程,我像个机器人麻木做着和往常一样的动作,拿着装满书的书包,看着空荡荡又充满气味的凳阁,再一次想起我为什么拿着所有的书回去。直到肩膀酸痛,
- 2020.5.20【第三十八天打卡】
CY的好运很哇塞呦
2020.5.20【第三十八天打卡】:一、今日进度:1.会计直播课程:《经济法基础》两个小时,主要内容:经济法基础相关理论知识~纯理论的课程,加上心里的烦躁,完整地听完一节课,真的是太难为自己了,需要明天重新看一遍回放。2.读其他书7章。二、今日待进步:1.练字0%2.表格学习0%3.TED0%三、明日安排:(一)每日常规三件事:1.读书半小时2.练字半小时3.学习半小时(二)每日新增一事(兴趣工
- 希希~嗯嗯~
猪猪女孩小哒哒
电话铺垫无聊天当天来上课的情况:外婆陪三岁的希希,妈妈陪小的大的上课规则感建立的还算不错,二的满场跑完全坐不住妈妈想找外教早教机构,因为大的在托班,里面会有数学、外教等分支教学课程。老二妈妈没怎么带教二宝。妈妈想给她找语言妈妈问有没有英文我的回答是英文课会有中教,应该回答中外教一起妈妈夸赞宝宝10个月会走了,今天见到的情形是宝宝走几步路就会跌倒,没有联系过爬,就开始走,长大以后模仿别人动作上面做的
- 【徐远 房产投资规划课(7)】(02.18):技术进步会逆转城市聚集吗?
格式化_001
微信图片_20181005125538.png声明以下内容来自徐远的分享。徐远介绍徐远:北京大学金融学教授,美国杜克大学经济学博士。其研究领域:宏观经济、金融经济、经济政策、房地产、城市化......本节思维框架新技术的出现新技术是否会引起房价下跌历史经验人们的交流是分不同层次的总结新技术的出现昨天的课程里,我给你重点讲了城市化对房价的影响。我们平常说房价高,其实主要说的是大城市的房价高。大城市聚
- 软件测试/测试开发/全日制 |利用Django REST framework构建微服务
霍格沃兹-慕漓
django微服务sqlite
霍格沃兹测试开发学社推出了《Python全栈开发与自动化测试班》。本课程面向开发人员、测试人员与运维人员,课程内容涵盖Python编程语言、人工智能应用、数据分析、自动化办公、平台开发、UI自动化测试、接口测试、性能测试等方向。为大家提供更全面、更深入、更系统化的学习体验,课程还增加了名企私教服务内容,不仅有名企经理为你1v1辅导,还有行业专家进行技术指导,针对性地解决学习、工作中遇到的难题。让找
- 24营2组锋妈11月13日作业及阅读笔记
锋妈
第一部分,听课心得在《时间管理目标模型课程》中,主要学到了如下四点:一、为什么要制定目标二、怎么样制定目标三、制定目标后要做些什么四、立刻行动起来听完后,对照讲课提纲,是自身的存在的弱点,觉着最大的绊脚石是第四点立刻行动起来。因为再宏伟的目标,再强大的驱动力下,如果没有行动去执行,一切都是空谈。为了避免执行力弱化,结合自己目前实际情况,觉着尽量把目标制定的简单明了、可执行、可衡量、可反馈回顾的。只
- 觉察日记11.26
无限可能abc
真的天天在家的日子真是折磨,我无所事事的呆着,虽说每天在听得到,但是感觉只是例行每天的任务,我在想我生存的意义。我其实一直想成为一名作家,也觉得想成为作家并不容易。我的每天不断地写作,只是觉得进步并不大。我想输入和输出很关键。我尝试着幻想自己写作成功的样子,或许是一本书,或者是一部作品。人生或许缺少点精彩的内容,不能再这样气馁下去了。我决心改变。我报了心理学课程,想来自己每次无助时候都是愿望或者说
- 致即将逝去的2020年
斯丹钰
婚姻生活没有想象中那么完美…有时候特别痛恨小时候受的那些教育为什么要被灌输:结婚就好了结婚根本不是那么一件容易的事情…结婚是一种全新生活方式的开始是每一个人学习的新课程很讨厌传统思想中:女人的价值不就是为了生儿育女的吗!我觉得女人哪怕你不是想走所谓的事业型但是你一定要拥有一技之长无论你身在职场,还是想退隐江湖哪天再回来…至少你能在这个时代和这个社会生存下去那时候再来谈你的精神你要的所有其它的东西不
- SQL查询技巧:深入解析学生选课系统数据库
天冬忘忧
SQL数据库sqloracle
在大学的学生选课系统中,数据库的管理和查询是日常操作中的重要部分。本文通过一系列具体的SQL查询示例,深入解析如何高效地从数据库中获取所需信息,包括学生选课情况、成绩分析、教师课程管理等。系统数据库结构首先,我们有一个包含以下表的数据库:course-存储课程信息建表CREATETABLE`course`(`CNO`varchar(5)NOTNULL,`CNAME`varchar(10)NOTNU
- 新媒体人#自媒体魂!新手到入门|一篇足矣
ph萝卜
最近已学习《新媒体写作平台策划与运营》课程,先梳理梳理学习感悟,后上满满的干货!希望阅读文章的你可以带来一丝想法,目的就达到了!想干成一件事,最靠谱的就是去认识一个已经做成了这件事情的人,或是认识与这件事情相关的人。做到不耻下问,足或有所长,你找他们聊天一小时,足以比你看多少书来的实际,就打个比方,我想利用我的空余时间做微信公众平台,我想到的是学习相关知识,包括编辑,美化,排版,运营,与其同时,我
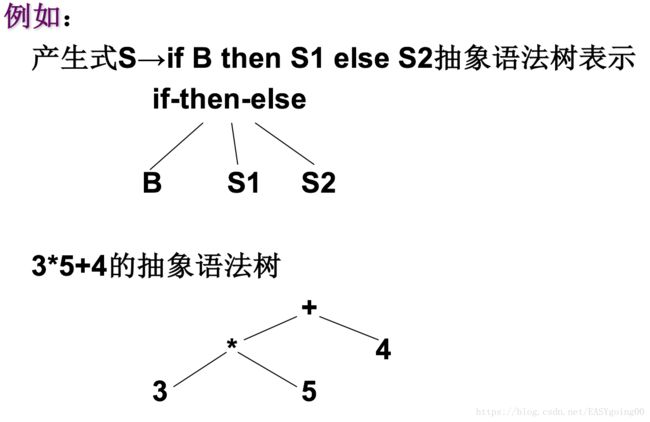
- 【编译原理】方舟编译技术课程 — 词法分析
CSU_THU_SUT
编译原理编译器编译原理llvm
打开目录阅读更佳参考视频:方舟·编译技术入门与实战以及西交冯博琴老师的相关视频编译的过程包括词法分析(分析程序符号)、语法分析(分析语法单位)、中间代码生成、代码优化和目标代码生成。一、编译过程各部分的任务(1)词法分析:输入源程序,扫描分解源程序字符串,识别五类符号,包括定义符、标识符、运算符、界符和常数,转为单词符号。(2)语法分析:在词法分析基础上,将单词符号转为语法单位(如短句、子句、句子
- 四、模型的下载与使用
梦中星华
AI画图人工智能
模型的下载与使用在我们已经熟悉的文生图和图生图的基础知识之上,现在是时候选择我们的艺术伙伴——AI模型了。在本篇讲义中,我们将学习掌握模型的下载和安装过程,以及如何在实际创作中灵活调用它们。通过本课程的学习,我们将能够更加自如地驾驭AI绘画工具,让我们的艺术创作更加多元和高效。让我们一起迈出这一步,选择一位能够理解我们创意愿景的AI画家,共同创作出令人赞叹的艺术作品。§1.模型的基本概念与下载\S
- 锋哥写一套前后端分离Python权限系统 基于Django5+DRF+Vue3.2+Element Plus+Jwt 视频教程 ,帅呆了~~
java1234_小锋
Python权限系统django权限系统pythonweb权限系统djangoDRFVUE权限python
大家好,我是java1234_小锋老师,最近写了一套【前后端分离Python权限系统基于Django5+DRF+Vue3.2+ElementPlus+Jwt】视频教程,持续更新中,计划月底更新完,感谢支持。视频在线地址:打造前后端分离Python权限系统基于Django5+DRF+Vue3.2+ElementPlus+Jwt视频教程(火爆连载更新中..)_哔哩哔哩_bilibili项目介绍本课程采
- xml解析
小猪猪08
xml
1、DOM解析的步奏
准备工作:
1.创建DocumentBuilderFactory的对象
2.创建DocumentBuilder对象
3.通过DocumentBuilder对象的parse(String fileName)方法解析xml文件
4.通过Document的getElem
- 每个开发人员都需要了解的一个SQL技巧
brotherlamp
linuxlinux视频linux教程linux自学linux资料
对于数据过滤而言CHECK约束已经算是相当不错了。然而它仍存在一些缺陷,比如说它们是应用到表上面的,但有的时候你可能希望指定一条约束,而它只在特定条件下才生效。
使用SQL标准的WITH CHECK OPTION子句就能完成这点,至少Oracle和SQL Server都实现了这个功能。下面是实现方式:
CREATE TABLE books (
id &
- Quartz——CronTrigger触发器
eksliang
quartzCronTrigger
转载请出自出处:http://eksliang.iteye.com/blog/2208295 一.概述
CronTrigger 能够提供比 SimpleTrigger 更有具体实际意义的调度方案,调度规则基于 Cron 表达式,CronTrigger 支持日历相关的重复时间间隔(比如每月第一个周一执行),而不是简单的周期时间间隔。 二.Cron表达式介绍 1)Cron表达式规则表
Quartz
- Informatica基础
18289753290
InformaticaMonitormanagerworkflowDesigner
1.
1)PowerCenter Designer:设计开发环境,定义源及目标数据结构;设计转换规则,生成ETL映射。
2)Workflow Manager:合理地实现复杂的ETL工作流,基于时间,事件的作业调度
3)Workflow Monitor:监控Workflow和Session运行情况,生成日志和报告
4)Repository Manager:
- linux下为程序创建启动和关闭的的sh文件,scrapyd为例
酷的飞上天空
scrapy
对于一些未提供service管理的程序 每次启动和关闭都要加上全部路径,想到可以做一个简单的启动和关闭控制的文件
下面以scrapy启动server为例,文件名为run.sh:
#端口号,根据此端口号确定PID
PORT=6800
#启动命令所在目录
HOME='/home/jmscra/scrapy/'
#查询出监听了PORT端口
- 人--自私与无私
永夜-极光
今天上毛概课,老师提出一个问题--人是自私的还是无私的,根源是什么?
从客观的角度来看,人有自私的行为,也有无私的
- Ubuntu安装NS-3 环境脚本
随便小屋
ubuntu
将附件下载下来之后解压,将解压后的文件ns3environment.sh复制到下载目录下(其实放在哪里都可以,就是为了和我下面的命令相统一)。输入命令:
sudo ./ns3environment.sh >>result
这样系统就自动安装ns3的环境,运行的结果在result文件中,如果提示
com
- 创业的简单感受
aijuans
创业的简单感受
2009年11月9日我进入a公司实习,2012年4月26日,我离开a公司,开始自己的创业之旅。
今天是2012年5月30日,我忽然很想谈谈自己创业一个月的感受。
当初离开边锋时,我就对自己说:“自己选择的路,就是跪着也要把他走完”,我也做好了心理准备,准备迎接一次次的困难。我这次走出来,不管成败
- 如何经营自己的独立人脉
aoyouzi
如何经营自己的独立人脉
独立人脉不是父母、亲戚的人脉,而是自己主动投入构造的人脉圈。“放长线,钓大鱼”,先行投入才能产生后续产出。 现在几乎做所有的事情都需要人脉。以银行柜员为例,需要拉储户,而其本质就是社会人脉,就是社交!很多人都说,人脉我不行,因为我爸不行、我妈不行、我姨不行、我舅不行……我谁谁谁都不行,怎么能建立人脉?我这里说的人脉,是你的独立人脉。 以一个普通的银行柜员
- JSP基础
百合不是茶
jsp注释隐式对象
1,JSP语句的声明
<%! 声明 %> 声明:这个就是提供java代码声明变量、方法等的场所。
表达式 <%= 表达式 %> 这个相当于赋值,可以在页面上显示表达式的结果,
程序代码段/小型指令 <% 程序代码片段 %>
2,JSP的注释
<!-- -->
- web.xml之session-config、mime-mapping
bijian1013
javaweb.xmlservletsession-configmime-mapping
session-config
1.定义:
<session-config>
<session-timeout>20</session-timeout>
</session-config>
2.作用:用于定义整个WEB站点session的有效期限,单位是分钟。
mime-mapping
1.定义:
<mime-m
- 互联网开放平台(1)
Bill_chen
互联网qq新浪微博百度腾讯
现在各互联网公司都推出了自己的开放平台供用户创造自己的应用,互联网的开放技术欣欣向荣,自己总结如下:
1.淘宝开放平台(TOP)
网址:http://open.taobao.com/
依赖淘宝强大的电子商务数据,将淘宝内部业务数据作为API开放出去,同时将外部ISV的应用引入进来。
目前TOP的三条主线:
TOP访问网站:open.taobao.com
ISV后台:my.open.ta
- 【MongoDB学习笔记九】MongoDB索引
bit1129
mongodb
索引
可以在任意列上建立索引
索引的构造和使用与传统关系型数据库几乎一样,适用于Oracle的索引优化技巧也适用于Mongodb
使用索引可以加快查询,但同时会降低修改,插入等的性能
内嵌文档照样可以建立使用索引
测试数据
var p1 = {
"name":"Jack",
"age&q
- JDBC常用API之外的总结
白糖_
jdbc
做JAVA的人玩JDBC肯定已经很熟练了,像DriverManager、Connection、ResultSet、Statement这些基本类大家肯定很常用啦,我不赘述那些诸如注册JDBC驱动、创建连接、获取数据集的API了,在这我介绍一些写框架时常用的API,大家共同学习吧。
ResultSetMetaData获取ResultSet对象的元数据信息
- apache VelocityEngine使用记录
bozch
VelocityEngine
VelocityEngine是一个模板引擎,能够基于模板生成指定的文件代码。
使用方法如下:
VelocityEngine engine = new VelocityEngine();// 定义模板引擎
Properties properties = new Properties();// 模板引擎属
- 编程之美-快速找出故障机器
bylijinnan
编程之美
package beautyOfCoding;
import java.util.Arrays;
public class TheLostID {
/*编程之美
假设一个机器仅存储一个标号为ID的记录,假设机器总量在10亿以下且ID是小于10亿的整数,假设每份数据保存两个备份,这样就有两个机器存储了同样的数据。
1.假设在某个时间得到一个数据文件ID的列表,是
- 关于Java中redirect与forward的区别
chenbowen00
javaservlet
在Servlet中两种实现:
forward方式:request.getRequestDispatcher(“/somePage.jsp”).forward(request, response);
redirect方式:response.sendRedirect(“/somePage.jsp”);
forward是服务器内部重定向,程序收到请求后重新定向到另一个程序,客户机并不知
- [信号与系统]人体最关键的两个信号节点
comsci
系统
如果把人体看做是一个带生物磁场的导体,那么这个导体有两个很重要的节点,第一个在头部,中医的名称叫做 百汇穴, 另外一个节点在腰部,中医的名称叫做 命门
如果要保护自己的脑部磁场不受到外界有害信号的攻击,最简单的
- oracle 存储过程执行权限
daizj
oracle存储过程权限执行者调用者
在数据库系统中存储过程是必不可少的利器,存储过程是预先编译好的为实现一个复杂功能的一段Sql语句集合。它的优点我就不多说了,说一下我碰到的问题吧。我在项目开发的过程中需要用存储过程来实现一个功能,其中涉及到判断一张表是否已经建立,没有建立就由存储过程来建立这张表。
CREATE OR REPLACE PROCEDURE TestProc
IS
fla
- 为mysql数据库建立索引
dengkane
mysql性能索引
前些时候,一位颇高级的程序员居然问我什么叫做索引,令我感到十分的惊奇,我想这绝不会是沧海一粟,因为有成千上万的开发者(可能大部分是使用MySQL的)都没有受过有关数据库的正规培训,尽管他们都为客户做过一些开发,但却对如何为数据库建立适当的索引所知较少,因此我起了写一篇相关文章的念头。 最普通的情况,是为出现在where子句的字段建一个索引。为方便讲述,我们先建立一个如下的表。
- 学习C语言常见误区 如何看懂一个程序 如何掌握一个程序以及几个小题目示例
dcj3sjt126com
c算法
如果看懂一个程序,分三步
1、流程
2、每个语句的功能
3、试数
如何学习一些小算法的程序
尝试自己去编程解决它,大部分人都自己无法解决
如果解决不了就看答案
关键是把答案看懂,这个是要花很大的精力,也是我们学习的重点
看懂之后尝试自己去修改程序,并且知道修改之后程序的不同输出结果的含义
照着答案去敲
调试错误
- centos6.3安装php5.4报错
dcj3sjt126com
centos6
报错内容如下:
Resolving Dependencies
--> Running transaction check
---> Package php54w.x86_64 0:5.4.38-1.w6 will be installed
--> Processing Dependency: php54w-common(x86-64) = 5.4.38-1.w6 for
- JSONP请求
flyer0126
jsonp
使用jsonp不能发起POST请求。
It is not possible to make a JSONP POST request.
JSONP works by creating a <script> tag that executes Javascript from a different domain; it is not pos
- Spring Security(03)——核心类简介
234390216
Authentication
核心类简介
目录
1.1 Authentication
1.2 SecurityContextHolder
1.3 AuthenticationManager和AuthenticationProvider
1.3.1 &nb
- 在CentOS上部署JAVA服务
java--hhf
javajdkcentosJava服务
本文将介绍如何在CentOS上运行Java Web服务,其中将包括如何搭建JAVA运行环境、如何开启端口号、如何使得服务在命令执行窗口关闭后依旧运行
第一步:卸载旧Linux自带的JDK
①查看本机JDK版本
java -version
结果如下
java version "1.6.0"
- oracle、sqlserver、mysql常用函数对比[to_char、to_number、to_date]
ldzyz007
oraclemysqlSQL Server
oracle &n
- 记Protocol Oriented Programming in Swift of WWDC 2015
ningandjin
protocolWWDC 2015Swift2.0
其实最先朋友让我就这个题目写篇文章的时候,我是拒绝的,因为觉得苹果就是在炒冷饭, 把已经流行了数十年的OOP中的“面向接口编程”还拿来讲,看完整个Session之后呢,虽然还是觉得在炒冷饭,但是毕竟还是加了蛋的,有些东西还是值得说说的。
通常谈到面向接口编程,其主要作用是把系统��设计和具体实现分离开,让系统的每个部分都可以在不影响别的部分的情况下,改变自身的具体实现。接口的设计就反映了系统
- 搭建 CentOS 6 服务器(15) - Keepalived、HAProxy、LVS
rensanning
keepalived
(一)Keepalived
(1)安装
# cd /usr/local/src
# wget http://www.keepalived.org/software/keepalived-1.2.15.tar.gz
# tar zxvf keepalived-1.2.15.tar.gz
# cd keepalived-1.2.15
# ./configure
# make &a
- ORACLE数据库SCN和时间的互相转换
tomcat_oracle
oraclesql
SCN(System Change Number 简称 SCN)是当Oracle数据库更新后,由DBMS自动维护去累积递增的一个数字,可以理解成ORACLE数据库的时间戳,从ORACLE 10G开始,提供了函数可以实现SCN和时间进行相互转换;
用途:在进行数据库的还原和利用数据库的闪回功能时,进行SCN和时间的转换就变的非常必要了;
操作方法: 1、通过dbms_f
- Spring MVC 方法注解拦截器
xp9802
spring mvc
应用场景,在方法级别对本次调用进行鉴权,如api接口中有个用户唯一标示accessToken,对于有accessToken的每次请求可以在方法加一个拦截器,获得本次请求的用户,存放到request或者session域。
python中,之前在python flask中可以使用装饰器来对方法进行预处理,进行权限处理
先看一个实例,使用@access_required拦截:
?