Keras中写一个网络的步骤
Keras中写一个网络的步骤
1. 载入数据
2. 数据预处理
包括对数据进行归一化,分成训练集,测试集,验证集,对标签进行to_categorical()操作等等。
3. 定义模型model
(1)贯序模型方式

(2)函数式方式
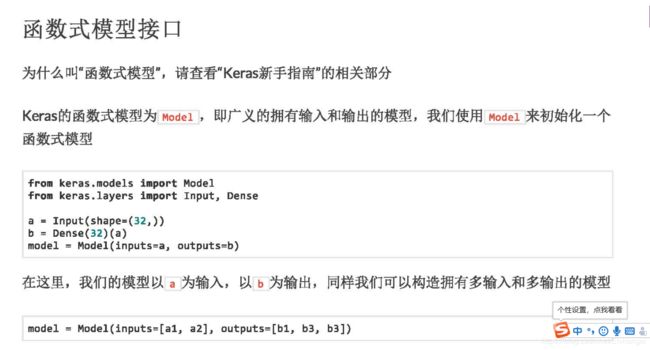
4. 编译模型
(1)选择优化器
这是选择训练模型时更新权重的特定算法。如Adam、SGD、Moment等。
(2)选择目标函数
这是选择损失函数,用于确定权重空间。如MSE、Binary corss_entropy等。
(3)评估训练好的模型
常用的指标有Auccary、Precision、Recall等。
model.compile()
model.compile (optimizer=Adam(lr=1e-4), loss=’binary_crossentropy’, metrics=[‘accuracy’])optimizer:优化器,如Adam
loss:计算损失,这里用的是交叉熵损失
metrics: 列表,包含评估模型在训练和测试时的性能的指标,典型用法是metrics=[‘accuracy’]。如果要在多输出模型中为不同的输出指定不同的指标,可向该参数传递一个字典,例如metrics={‘output_a’: ‘accuracy’}
5. 训练模型
model.fit()函数
fit( x, y, batch_size=32, epochs=10, verbose=1, callbacks=None,
validation_split=0.0, validation_data=None, shuffle=True,
class_weight=None, sample_weight=None, initial_epoch=0)
- x:输入数据。如果模型只有一个输入,那么x的类型是numpy
array,如果模型有多个输入,那么x的类型应当为list,list的元素是对应于各个输入的numpy array - y:标签,numpy array
- batch_size:整数,指定进行梯度下降时每个batch包含的样本数。训练时一个batch的样本会被计算一次梯度下降,使目标函数优化一步。
- epochs:整数,训练终止时的epoch值,训练将在达到该epoch值时停止,当没有设置initial_epoch时,它就是训练的总轮数,否则训练的总轮数为epochs - inital_epoch
- verbose:日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个epoch输出一行记录
- callbacks:list,其中的元素是keras.callbacks.Callback的对象。这个list中的回调函数将会在训练过程中的适当时机被调用,参考回调函数
- validation_split:0~1之间的浮点数,用来指定训练集的一定比例数据作为验证集。验证集将不参与训练,并在每个epoch结束后测试的模型的指标,如损失函数、精确度等。注意,validation_split的划分在shuffle之前,因此如果你的数据本身是有序的,需要先手工打乱再指定validation_split,否则可能会出现验证集样本不均匀。
- validation_data:形式为(X,y)的tuple,是指定的验证集。此参数将覆盖validation_spilt。
- shuffle:布尔值或字符串,一般为布尔值,表示是否在训练过程中随机打乱输入样本的顺序。若为字符串“batch”,则是用来处理HDF5数据的特殊情况,它将在batch内部将数据打乱。
- class_weight:字典,将不同的类别映射为不同的权值,该参数用来在训练过程中调整损失函数(只能用于训练)
- sample_weight:权值的numpy array,用于在训练时调整损失函数(仅用于训练)。可以传递一个1D的与样本等长的向量用于对样本进行1对1的加权,或者在面对时序数据时,传递一个的形式为(samples,sequence_length)的矩阵来为每个时间步上的样本赋不同的权。这种情况下请确定在编译模型时添加了sample_weight_mode=’temporal’。
- initial_epoch: 从该参数指定的epoch开始训练,在继续之前的训练时有用。
fit函数返回一个History的对象,其History.history属性记录了损失函数和其他指标的数值随epoch变化的情况,如果有验证集的话,也包含了验证集的这些指标变化情况
6. evaluate模型评估
model.evaluate()
evaluate(self, x, y, batch_size=32, verbose=1, sample_weight=None)
本函数按batch计算在某些输入数据上模型的误差,其参数有:
- x:输入数据,与fit一样,是numpy array或numpy array的list
- y:标签,numpy array
- batch_size:整数,含义同fit的同名参数
- verbose:含义同fit的同名参数,但只能取0或1
- sample_weight:numpy array,含义同fit的同名参数
本函数返回一个测试误差的标量值(如果模型没有其他评价指标),或一个标量的list(如果模型还有其他的评价指标)。model.metrics_names将给出list中各个值的含义。
如果没有特殊说明,以下函数的参数均保持与fit的同名参数相同的含义
如果没有特殊说明,以下函数的verbose参数(如果有)均只能取0或1
7. predict 模型评估
model.predict()
predict(self, x, batch_size=32, verbose=0)
predict_classes(self, x, batch_size=32, verbose=1)
predict_proba(self, x, batch_size=32, verbose=1)
本函数按batch获得输入数据对应的输出,其参数有:
函数的返回值是预测值的numpy array
predict_classes:本函数按batch产生输入数据的类别预测结果;
predict_proba:本函数按batch产生输入数据属于各个类别的概率