目标检测 (Object Detection) (四): Faster R-CNN
Faster R-CNN是He Kaiming等人于2015年在NIPS发表的一篇论文,是R-CNN目标检测系列的第三次迭代。提到Faster R-CNN,不得不简单介绍一下它的早期版本:R-CNN和Fast R-CNN。接下来,我们首先对R-CNN,Fast R-CNN,Faster R-CNN进行简单介绍和对比,然后再详细介绍Faster R-CNN。
目录
1. R-CNN,Fast R-CNN,Faster R-CNN简单介绍和对比
2. Faster R-CNN详细介绍
2.1 RPN
2.1.1 Anchor
2.1.2 Loss Function
2.1.3 Training RPNs
2.2 Sharing Featuers for RPN and Fast R-CNN
2.3 具体实现
3. Reference
1. R-CNN,Fast R-CNN,Faster R-CNN简单介绍和对比
R-CNN, Fast R-CNN, Faster R-CNN都属于two-stage object detection方法,即:需要先提取region proposals, 再对proposals进行目标检测。下图给出了R-CNN、Fast R-CNN、Faster R-CNN的之间的差异。

从上图中可以看到:
(1)R-CNN首先使用Selective search提取region proposals(候选框);然后用Deep Net(Conv layers)进行特征提取;最后对候选框类别分别采用SVM进行类别分类,采用回归对bounding box进行调整。其中每一步都是独立的。
(2)Fast R-CNN在R-CNN的基础上,提出了多任务损失(Multi-task Loss), 将分类和bounding box回归作为一个整体任务进行学习;另外,通过ROI Projection可以将Selective Search提取出的ROI区域(即:候选框Region Proposals)映射到原始图像对应的Feature Map上,减少了计算量和存储量,极大的提高了训练速度和测试速度。
(3)Faster R-CNN则是在Fast R-CNN的基础上,提出了RPN网络用来生成Region Proposals。通过网络共享将提取候选框与目标检测结合成一个整体进行训练,替换了Fast R-CNN中使用Selective Search进行提取候选框的方法,提高了测试过程的速度。
具体的算法结构和流程见下表:
| 算法 |
算法流程和架构图 |
优缺点/描述 |
||||||
| R-CNN |
算法流程: (1) 采用selective search提取出2000个region proposals(候选框) (2) 对候选框进行压缩(warp),使其具备相同的大小 (3) 将压缩好的wrapped regions输入到CNN,R-CNN中使用的基础网络是AlexNet,提取出4096维的feature map (4) 对提取出的Feature map,使用SVM分类器进行分类,判断它是否属于特定的类别或者是背景 (5) 使用回归器进一步调整bounding box(bbox)的位置。
|
缺点: (1) 训练过程比较复杂,是一个多阶段训练的过程:先训练CNN,再训练SVM,最后训练bbox回归器 (2) 训练过程耗时、耗空间:训练SVM和bbox Regressor时,需要为每张图片提取候选框并存储到硬盘中。使用VGG16作为基础网络时,VOC07中的5000条数据作为训练集,需要使用几天时间,并且需要消耗几百G的内存 (3) 目标检测速度慢:测试过程中,需要为待检测图片提取候选框,比较耗时 |
||||||
| Fast R-CNN |
算法流程: (1) 通过selective search获得候选框 (2) 将整张图片输入到基础CNN网络中,生成feature map (3) 将候选框映射到feature map,通过ROI Pooling生成固定长度的特征向量 (4) 将生成的特征向量输入到两个Fully connected网络中,然后通过multi-task loss同时对类别和bbox回归其进行学习 |
优点: 针对R-CNN存在的缺点,Fast R-CNN做出如下改进: (1) 使用multi-task loss使得能够训练过程变成single-stage (2) 训练过程可以同时更新所有网络 不需要硬盘对feature map进行缓存
|
||||||
| Faster R-CNN |
算法流程: Faster R-CNN由两部分构成: (1) RPN用于生成region proposals (2) Fast R-CNN Detector |
创新点: 当时已有的Region Proposal提取方法耗时较长、影响检测过程的实时性的问题,Faster R-CNN提出了Region Proposal Network(RPN)用来生成region proposals。 并令RPN与目标检测网络(Fast R-CNN)共享卷积层的方式实现Attention机制,提取出对应的Region Proposals。
不同region proposals提取方法的速度对比:
|



2. Faster R-CNN详细介绍
Faster R-CNN在Fast R-CNN的基础上作出改进,提出RPN(Region Proposal Network),用来生成region proposals。正如上节介绍的,Faster R-CNN由两部分组成:(1)RPN用来生成region proposals (2) Fast R-CNN用来进行目标检测。令RPN与目标检测网络Fast R-CNN共享conv layers,相当于引入了attention机制,RPN可以告诉Fast R-CNN需要关注的区域,可以大大减少计算候选框的时间。
基于论文和对应代码的实现,给出Faster R-CNN的详细结构(如下图)。接下来,我们首先简单介绍该结构图,并引出一些关键概念,再详细介绍各个模块。

如上图所示,
(1)共享卷积层部分:论文中使用VGG/ZF作为基础网络。上图是基于VGG进行绘制的,因此共享网络输出的特征图Feature Map的shape=(W,H,512),512代表channel数。
(2)Region Proposal Network (RPN):
Part 1: 使用3*3*512大小的卷积核对Feature Map进行卷积得到intermediate layer,intermediate layer的shape=(W, H, 512),与Feature Map具有相同大小。则每一个特征点可以表示成一个512维的向量。
Part 2: cls layer 和 reg layer
首先简单引入anchor的概念:其思想就是将特征图上的每一个点映射回原始输入图像上,在原始图像上以该点为中心生成不同尺寸、不同比例的候选框,作为RPN待分类的候选框。这些候选框就是所谓的anchor。设为每个特征点生成k个anchor,若Feature Map大小为W*H,则该特征图共有W*H*k个anchor。
RPN网络包括两部分,分别为cls layer和reg layer。RPN网络需要为每个特征点的所有anchor进行分类,区分每个anchor是否为目标;并对每个anchor的bounding box进行回归,调整其边界。
- cls layer:RPN中的分类属于二分类,只区分anchor是否包括目标。使用2位对每个anchor的分类结果进行表示,因此对于每个特征点,cls layer的输出shape=(1,1,2k),相当于对每一个点进行1*1*2k的卷积运算;而对于整个特征图,cls layer的输出shape=(W,H,2k)。注意,不必在意后续的两个reshape操作,它们只是为了使用softmax输出每个候选框的类别概率而已。
- reg layer:RPN中的reg layer用来对每个anchor的边界进行回归。由于每个anchor需要使用4位来表示其边界,因此对于特征图上的每个点,reg layer的输出shape=(1,1,4k),相当于对每一个点进行1*1*2k的卷积运算;而对于整个特征图,reg layer的输出shape=(W,h,4k)。
这样,RPN就可以为每一张图片生成对于的region proposals,用于后续的检测。虽然Faster R-CNN中,在RPN网络生成Region Proposals后还进行了一些后处理,但是该部分不在图中进行体现。
注意:
cls layer和reg layer中,对每一个特征点来讲,是一个全连接网络。
从整体上来讲,由于所有的特征点使用相同的卷积核,因此cls layer和reg layer相当于是一个卷积层,其卷积核大小分别为:1*1*2k和1*1*4k。
(3)Fast R-CNN用于目标检测
由于RPN给出的Region Proposal是基于原始图像的坐标,故而首先需要将RPN提取出Region Proposal映射到步骤(1)共享网络提取出的Feature map中,再将其输入到Fast R-CNN的ROI-Pooling部分进行后续的检测,给出最后的预测框和类别得分。
2.1 RPN
RPN就是使用卷积神经网络直接产生Region Proposals,使用的方法的本质就是滑动窗口。RPN的设计比较巧妙,只需在conv layers最后一层输出的feature map进行滑动,利用anchor机制和bbox回归得到多尺度,多长宽比的region proposals。
输入:任一大小的图像
输出:一组矩形候选区域,这些候选框带有目标得分
RPN网络和目标检测网络Fast R-CNN共享conv layers,论文中建议使用ZF(5层共享conv layers)或VGG-16 (13 共享conv layers)。本文使用VGG16进行介绍。

上图给出了RPN网络的主要结构。图中最下层为conv layers输出的feature map,可以看到:
(1)首先,对feature map进行卷积,卷积核大小为(n*n*512) (if VGG, #channel = 512),得到中间层intermediate layer。中间层的大小和feature map一样。其中,每一个特征点可以被表示成512维的向量。
(2)然后,图中以一个特征点为例,给出了RPN如何为该点生成region Proposals。
此处引入anchor思想:将特征图上的每一个点映射回原始输入图像上,在原始图像上以该点为中心生成不同尺寸、不同比例的候选框,作为RPN待分类的候选框。这些候选框就是所谓的anchor。设为每个特征点生成k个anchor,若Feature Map大小为W*H,则该特征图共有W*H*k个anchor。
RPN要做的就是判定每一个特征点对应的k个anchor是否包含目标,并通过回归对每个anchor的bounding box进行修正。
RPN网络包含两部分,分别为:cls layer和reg layer:
- cls layer:每一个特征点包括k个anchor,使用2位来标记每个anchor是否包含目标的概率。相当于对每一个特征点进行了1*1*2k卷积,全部特征点使用相同的1*1*2k的卷积核。
- reg layer:每一个特征点对应k个anchor,使用4位来表示每个anchor的bounding box,reg layer对bounding box进行回归修正其边界。相当于每一个特征点进行1*1*4k的卷积,同样全部特征点使用相同的1*1*4k的卷积核。
Q:使用anchor的好处是什么?
A:虽然也是使用滑动窗口思想,但是滑动窗口操作是在卷积层特征图上进行的,维度较原始图像降低了16x16倍(中间经过了4次2x2的pooling操作);另外采用了9种anchor可以获得多尺度特征,对应了三种尺度和三种长宽比,加上后边接了边框回归,所以即便只使用这9种anchor外的窗口也能得到一个跟目标比较接近的region proposal。
2.1.1 Anchor
到目前为止,相信大家对RPN网络的结构有了充分的了解。那么接下来,我们详细介绍一下anchor是什么。
我们知道,RPN网络首先对conv layers输出的Feature Map进行3*3的卷积生成同样大小的intermediate layer。
如下图所示,对intermediate layer上的每一个特征点,可以通过映射找到其在原始输入图像上的对应点。再以该点为中心,可以在原始图像上得到k个不同尺寸、不同比例的候选区域,这些候选区域就是anchor。

注意:
1. Anchor具有平移不变性(translation-invariant); 平移不变性可以减小model size,即:参数的数量。
2. Anchor的提出其实是为了引入多尺度的特征。
常用的两种引入多尺度的方法有:
A. 基于image/feature pyramids : 将图像resize成不同尺度大小,然后使用conv layers计算每一个尺度下的feature maps。虽然效果很好,但是却time-consuming。
B. 基于多尺度滑动窗口Sliding windows of multiple scales:在feature maps上使用不同尺度的滑动窗口。第二种方法通常与第一种方法结合使用。
Anchor则是在单一尺度图像上计算卷积特征,并且通过与Fast R-CNN共享特征,而不需要引入其他的计算就可以得到多尺度特性。

2.1.2 Loss Function
为了训练RPN,需要解决以下两个问题:(1) anchor标签怎么打? (2) RPN网络的损失函数如何定义?
(1) anchor标签怎么打?
为了训练RPN,需要给每个anchor分配类别标签:{目标,非目标}。正负样本标记规则如下:
| 目标 Positive Label |
满足下列条件之一的anchor就可以被标记为正样本: (1) 与任意ground-truth (GT) box的IoU重叠率最大的anchor(也许不到0.7) (2) 与任意ground-truth (GT) box的IoU重叠率大于0.7的anchor 基本采用条件2就可以获得足够的正样本,但是对于一些极端情况,可以采用条件1生成正样本 |
| 非目标 Negative Label |
与所有GT box的IoUdou'xiao都小于0.3的anchorb被标记为负样本 |
注意:
1. 舍弃既没有被标记为正样本,也没有被标记非负样本的anchor。
2. 舍弃跨越图像边界的anchor。
(2) RPN网络的损失函数如何定义?
与Fast R-CNN类似,RPN使用multi-class损失,由两部分组成:分类损失+回归损失,其定义为:
| 公式(1) |
其中,![]() 代表mini-batch中anchor的index;
代表mini-batch中anchor的index;![]() 代表预测第
代表预测第![]() 个anchor为目标的概率;
个anchor为目标的概率;![]() 代表anchor的真实标签,如果是1则代表是正样本,如果是0则代表负样本;
代表anchor的真实标签,如果是1则代表是正样本,如果是0则代表负样本; ![]() 代表用来计算回归损失的参数,其具体定义见公式(3);
代表用来计算回归损失的参数,其具体定义见公式(3);![]() 代表与该正样本anchor相关联的ground-truth box相关的参数。
代表与该正样本anchor相关联的ground-truth box相关的参数。
注意:第二部分的回归损失中,![]() 代表只有被预测为目标的anchor训练样本才会计算回归损失。
代表只有被预测为目标的anchor训练样本才会计算回归损失。
![]() 用来平衡
用来平衡![]() 和
和![]() 两个归一化稀疏。论文中:
两个归一化稀疏。论文中:![]() the size of mini-batch;
the size of mini-batch; ![]() the number of anchor locations (~2400);
the number of anchor locations (~2400);![]() =10。
=10。
- 类别分类损失:使用log loss
| 公式(2) |
- 回归损失:Smooth L1损失 (与Fast R-CNN中回归损失一样)
首先给出![]() 和
和![]() 的定义:
的定义:
 |
公式(3) |
其中![]() 分别代表bounding box的中心点坐标以及width和height。
分别代表bounding box的中心点坐标以及width和height。![]() 分别表示预测框,anchor box,和ground-truth box。根据公式(3)计算出
分别表示预测框,anchor box,和ground-truth box。根据公式(3)计算出![]() 和
和![]() ,可以通过公式(4)求得Smooth L1 Loss:
,可以通过公式(4)求得Smooth L1 Loss:
|
|
公式(4)
|

2.1.3 Training RPNs
方法:使用反向传播和SGD实现RPN的端到端训练
采样:由于对于一张图片来说,通常负样本的数量远大于正样本的数量。因此,为了平衡正负样本并降低计算量,随机的从每张图片中采出256个anchor,正负样本的比例为1:1。如果一个图像中的正样本数小于128,则多用一些负样本以满足有256个Proposal可以用于训练。
初始化:新增的2层参数用均值为0,标准差为0.01的高斯分布来进行初始化,其余层(都是共享的卷积层,与VGG共有的层)参数用ImageNet分类预训练模型来初始化。
在PASCAL数据集上:(1)前60k个mini-batch进行迭代,学习率设为0.001;(2)后20k个mini-batch进行迭代,学习率设为0.0001;(3)设置动量momentum=0.9,权重衰减weightdecay=0.0005。
2.2 Sharing Featuers for RPN and Fast R-CNN
Faster R-CNN采用RPN提取region proposals,采用Fast R-CNN进行目标检测,那么如何训练才能够实现RPN和Fast R-CNN共享卷积层呢?我们知道,如果是分别训练两种不同任务的网络模型,即使它们的结构、参数完全一致,但各自的卷积层内的卷积核也会向着不同的方向改变,导致无法共享网络权重,下面我们介绍4种不同的训练方式。
- Alternating training:
此方法就是一个不断迭代的过程:
(1) 首先独立训练一个RPN,然后用这个RPN的网络权重对Fast-RCNN网络进行初始化并且用之前RPN输出proposal作为此时Fast-RCNN的输入训练Fast R-CNN。
(2) 用Fast R-CNN的网络参数去初始化RPN。之后不断迭代这个过程,即循环训练RPN、Fast-RCNN。
- Approximate Joint Training
这里与前一种方法不同,不再是串行训练RPN和Fast-RCNN,而是尝试把二者融入到一个网络内。在backward计算梯度时,把提取的ROI区域当做固定值看待;在反向传播更新参数时,来自RPN和来自Fast RCNN的增量合并输入原始特征提取层。 此方法和前方法效果类似,但能将训练时间减少20%-25%。公布的python代码中包含此方法。
- Non-approximate Joint Training
直接在网络结构上进行训练。但在反向传播时,要考虑ROI区域的变化的影响。推导超出本文范畴,请参看15年NIP论文。
- 4-step Alternating Training:论文中使用的方法
- Step 1:训练RPN,该网络用ImageNet预训练的模型初始化,并端到端微调用于region proposals生成
- Step 2:使用RPN生成的proposal,训练一个单独的Fast R-CNN,该网络也是用ImageNet预训练的模型进行初始化。这时候两个网络还没有共享卷积层。
- Step 3:使用上一步训练得到的网络初始化RPN,并固定共享层,只对RPN网络特有的层进行微调,此时两个网络共享卷积层。
- Step 4:保持共享的卷积层固定,微调Fast R-CNN的fc层。这样,两个网络共享相同的卷积层,构成一个统一的网络。
2.3 具体实现
- Rescale input images -> 短边=600 pixels
- 对于anchors:
-
使用3种scales:
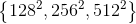 ,3种ratio
,3种ratio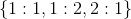 的组合,共9种anchor
的组合,共9种anchor
-
-
训练RPN:
-
与图像边缘相交的anchor不用作训练 (对于1000*600大小的图片可能会有20000~(60*40*9)个anchor,经过该操作后可以减少到6000 anchors)
-
从每张图像中按照1:1的正负样本比采样出256个anchors用作训练 (in Step1)
-
-
训练Fast R-CNN
-
如果RPN生成的proposals相交很多,可以使用NMS去除RPN提取出的高度重叠的region proposals;使用IoU阈值=0.7,可以得到2000个proposal regions/per image.
-
然后,建议选用Top_N ranked proposal regions用来训练Fast-RCNN, 论文中共使用2000个候选框进行训练Fast R-CNN。
-
-
测试过程:
-
在RPN中,与图像边缘相交的anchor被裁剪后继续使用
-
在Fast R-CNN中,也利用NMS去除高度重叠的region proposal;在测试过程中可以视情况调整IoU阈值,进而得到不同数量的proposal输入到Fast R-CNN中
-
NMS之后,我们用建议区域中的top-N个来检测(即排过序后取N个)
-
3. Reference
- Faster R-CNN: https://arxiv.org/abs/1506.01497
- Fast R-CNN: https://arxiv.org/abs/1504.08083
- R-CNN: https://arxiv.org/abs/1311.2524
- Blogs:
- https://blog.csdn.net/Zachary_Co/article/details/78890768
- https://blog.csdn.net/zziahgf/article/details/79311275
- https://blog.csdn.net/lanyuelvyun/article/details/77720260