眼下自动化运维平台的建设应当考虑的方向
运维职责贯穿了产品的生命周期,需要借助自动化、智能化的平台帮助运维工程师以最低的成本和最快的速度完成面向用户的服务交付和服务质量保障。运维平台主要由运维平台研发工程师理解业务需求后开发,主要包括:机器管理、资源管理、网络管理、架构基础设施、部署平台、配置管理平台、数据管理平台、监控平台、容量管理、流量管理、故障管理、业务调度平台、工作流引擎、权限管理、运维元数据管理和运维统一门户。
运维平台概述
运维职责贯穿了产品的生命周期,需要借助自动化、智能化的平台帮助运维工程师以最低的成本和最快的速度完成面向用户的服务交付和服务质量保障。运维平台主要由运维平台研发工程师理解业务需求后开发。下面从产品的生命周期角度介绍运维工程师需要交互的运维平台。
产品发布前
产品发布前运维工程师需要产品业务熟悉、产品架构设计评审、产品所需资源评估和申请。评审产品架构时,产品研发人员通过运维准入平台进行运维准入评审,例如SQL语句评审,程序发布包规范评审,程序监控方案评审等。
产品资源评估和申请时使用机器管理平台或者资源管理平台申请物理机或者虚拟机/容器资源;使用网络管理平台申请域名和IP。
产品发布
产品发布时使用初始化平台进行运行环境初始化,使用部署平台进行程序部署,使用配置管理平台进行配置分发,使用数据配送平台进行数据分发。总之,完成了程序/配置/数据自动化发布,产品即可对外提供服务。产品迭代的过程中使用自动化平台进行程序、配置和数据的变更以完成产品功能的升级。
产品运行维护
产品运行维护阶段运维工程师需要处理以下事项:
-
排查服务隐患,处理服务故障
使用监控平台实时监测服务的运行状况和资源消耗情况,根据日常服务运行报表评估服务整体运行状态,发现服务隐患;接收监控平台产出的故障报警,参考监控平台的异常检测事件、部署平台变更事件、网络管理平台产生的网络异常事件进行故障定位。故障定位后,使用故障管理平台中针对机房、网络、程序等问题定制的预案进行自动或手动的止损。
-
提高服务性能,优化服务成本
参考容量管理平台依据服务CPU、内存、QPS、响应时间计算的容量分析数据,参考流量管理平台的实时流量监测数据,发现服务瓶颈,优化服务性能。在保障服务质量的前提下,进行容量调整和流量调整,以最节省的机器资源,最便宜的网络带宽为用户提供高质量的服务。
产品下线
产品下线时需要使用部署平台下线程序,使用机器管理/资源管理平台回收资源。
运维平台分类介绍
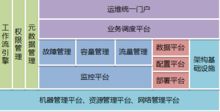
基础设施平台
基础设施平台主要用于产品发布前,包括机器管理、资源管理、网络管理以及架构基础设施。
-
机器管理
机器管理以自动化的流程管理机器,包括机器上架(机架)、下架(机架)、申请和故障修复等。
-
资源管理
资源管理管理的是虚拟机或者容器。私有云一般使用虚拟化技术例如Cgroup,LXC将物理机虚拟出若干容器,以容器为单位进行服务实例资源的分配和调度,例如docker。公有云一般使用openstack、xen、kvm将物理机虚拟为虚拟机,例如AWS的EC2,阿里云的ECS,百度开放云的BCC等。
-
网络管理
网络管理DNS、IP的申请和回收。
-
架构基础设施
架构基础设施包括但不局限于文件存储、数据库存储、缓存服务、消息队列等组件。各大公司的基础架构研发团队一般会研发一些基础组件,例如Google的GFS,BigTable,MapReduce。当然还有一些开源的基础组件可以使用,例如分布式计算类:mapreduce、spark、storm、hive;分布式存储类:hdfs、hbase、cassandra、MongoDB;缓存类:memcached,redis;消息队列类:ActiveMQ。此外,公有云也会提供类似的基础设施,例如AWS除了卖EC2还卖RDS(Relational Database Services),EMR(Elastic MapReduce),S3(Simple Storage Service),EBS(Elastic Block Service),SQS(Simple Queue service),SES(Simple Email Service)等。
构建自动化平台
构建自动化平台服务于产品发布,包括程序、配置和数据的变更。构建自动化平台提供小流量或者分级发布机制控制产品升级的风险,保障产品的持续交付。构建自动化平台包括部署平台、配置管理平台和数据管理平台。
部署平台包括部署包版本的管理、部署执行器、部署调度平台。常见的部署执行器例如ansible、sshpt。配置平台包括配置版本管理,配置分发工具以及配置分发策略平台。常见的配置分发工具包括puppet、cfengine、Chef。数据管理平台包括数据版本管理,数据传输工具以及数据分发策略平台。开源的P2P数据传输工具例如utorrent。
数据运营平台
数据运营平台服务于产品运行维护操作,包括监控平台、容量管理、流量管理和故障管理。
-
监控平台
监控平台采集、存储、计算服务相关的业务(例如收入,流量,响应时间)、系统(cache命中率,队列大小,进程句柄等)、机器/容器(CPU,内存,磁盘使用量)和网络数据(机房、网段状态),并对这些指标进行异常检测,以仪表盘和通知(电话、短信、邮件)方式和运维工程师交互,帮助运维工程师进行日常排查发现服务隐患;帮助运维工程师快速发现业务异常,并借助多维度指标分析(地域、运营商、机房多维度综合分析)、事件关联分析(指标异常事件、网络故障事件和变更事件等)等手段辅助故障诊断,快速定位问题。
监控管理通常和故障管理打通,为故障管理提供自动化预案执行的决策数据。业界开源的监控软件有Ganglia,Nagios,Cacti,Zabbix;国内的监控产品有:监控宝、OneApm、Qmonitor(侧重于数据库监控);国外的监控产品有NewRelic [2] ,AppDynamics [3] 。
-
容量管理
容量管理收集监控系统采集的服务相关的资源数据(例如CPU,内存,磁盘使用量)和性能数据(例如qps,响应时间),评估系统容量,发现系统瓶颈,并以服务扩容、缩容方式最大化服务性能,最小化服务成本。
-
流量管理
流量管理提供统一的流量接入方案,进行流量的接入和转发,实施全局的流量调度(外网和内网流量调度)。流量管理还承担产品的安全和防攻击(黑名单,反DDoS攻击,应用层防火墙)职责。
-
故障管理
故障管理实现故障快速定位和止损,提升服务稳定性。故障管理一般包括预案管理和故障记录。预案主要应对以下场景,比如突发的用户流量、网络攻击、大规模网络故障、大规模程序故障、数据丢失等。故障记录便于运维工程师事后的原因分析和问题挖掘。例如某个业务、某个基础设施、某个机器经常性故障,就需要重点关注。通过调整产品部署策略、业务架构避免故障;或者总结故障预案,在故障发生时能够自动化快速止损。
业务调度平台
运维平台如此之多,在设计开发的过程中都必须以接口化、标准化、服务化的思维进行平台研发。这样在代码规范、接口规范、数据规范、稳定性高的平台之上就可以通过搭积木的方式快速构建更复杂业务调度平台。例如在资源管理平台、构建自动化平台、监控平台、流量管理平台、容量管理平台之上可以搭建Paas平台,实现服务实例的自动化扩容、缩容和故障自动迁移。各大互联通公司都有自己的业务调度平台。例如Google内部的Brog,Omega(borg 2.0),facebook的Corona,tencent的 typhoon。开源的业务调度平台例如Google的Kubernetes和 Apache Mesos。
-
业务平台
业务平台服务于运维工程师的日常运维工作,主要包括工作流引擎、权限管理、运维元数据管理和运维统一门户。
-
工作流引擎
运维操作中需要多人协作处理的流程通常都需要发操作单。例如机器故障维修单、DNS变更操作单、数据库访问权限申请单等。这些操作流程都需要工作流引擎的支持。
-
权限管理
权限管理平台,所有的运维操作都需要角色和用户权限管理。例如运维工程师对机器的操作权限,对服务监控采集和报警策略的修改权限,对服务部署变更的权限等;例如运维经理对运维操作单的审批权限。
-
元数据管理
元数据管理,包括机房、服务器、服务、产品、人员信息以及他们之间的物理和业务拓扑关系等,所有的运维平台都需要此类信息。
-
运维统一门户
运维统一门户使得运维人员不必面对众多运维系统,运维门户中的任务中心收集了运维工程师要处理的工作;运维门户中的信息中心以仪表盘的方式收集了运维工程师需要关注的业务状态。
- 参考资料
-
- 1. 运维平台规划体系全介绍 .InfoQ[引用日期2015-08-11]