CUDA PTX ISA阅读笔记(一)
不知道这是个啥的看这里:Parallel Thread Execution ISA Version 5.0.
简要来说,PTX就是.cu代码编译出来的一种东西,然后再由PTX编译生成执行代码。如果不想看网页版,cuda的安装目录下的doc文件夹里有pdf版本,看起来也很舒服。
ps:因为文档是英文的(而且有二百多页= =),鉴于博主英语水平有限并且时间也有限(主要是懒),因此只意译了一些自以为重点的内容,如想要深入学习,还是乖乖看文档去吧
第一章 介绍
1.1. 使用GPU进行可扩展数据并行计算
介绍了一波并行计算的知识。
1.2. PTX的目标
PTX为提供了一个稳定的编程模型和指令集,这个ISA能够跨越多种GPU,并且能够优化代码的编译等等。
1.3. PTX ISA 5.0版本
就是PTX ISA5.0的一些新特性
1.4. 文档结构
- 编程模型:编程模型的概要
- PTX 机器模型:大致介绍PTX虚拟机
- 语法:描述PTX语言的基础语法
- 状态空间、类型和变量:就是描述这些玩意
- 指令操作数
- 应用二进制接口:描述了函数定义和调用的语法,以及PTX支持的应用二进制接口
- 指令集
- 特殊的寄存器
- 版本更新介绍
第二章 编程模型
2.1. 一个高并行度的协处理器
继续科普GPU。
2.2. 线程层级
2.2.1 合作线程阵列
2.2.2 线程阵列网格
上边这两节主要就是讲一些基本的GPU的block啊grid啊之类的东西,想了解的可以看我的另一篇文章:《GPU高性能编程 CUDA实战》(CUDA By Example)读书笔记-第五章。这里的图就用了这个手册里的。
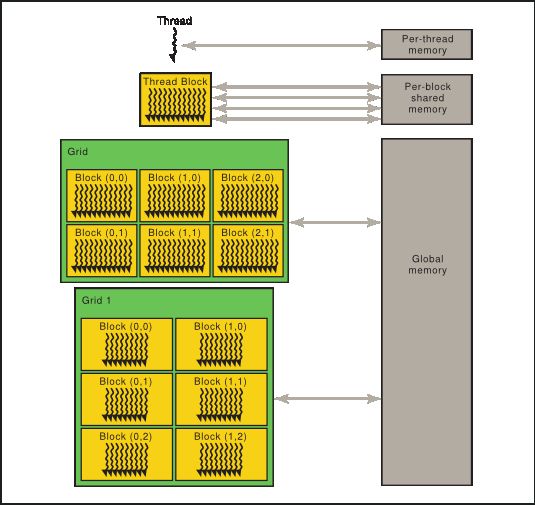
2.3. 内存层级
这个图实在是太好了:
第三章 PTX机器模型
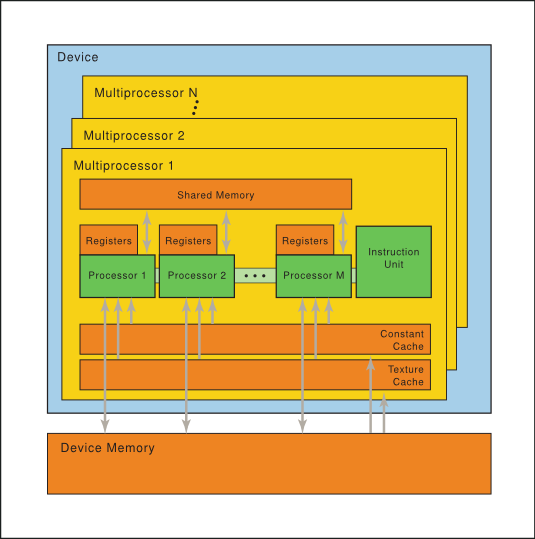
3.1. 一组带有片上共享内存的SIMT多处理器
主要讲一下硬件层级结构,果然图还是最好的:
第四章 语法
PTX语言是由操作指令和操作数组成。
4.1. 代码格式
使用\n换行,空格木有意义,#这个符号和C差不多,就是预编译指令,而且大小写敏感,每个PTX代码都是由.version打头,表示PTX的版本。
4.2. 注释
和C一样
4.3. 语句
以一个可选的标记开始,以分号结束,就像这样:
start: mov.b32 r1, %tid.x;
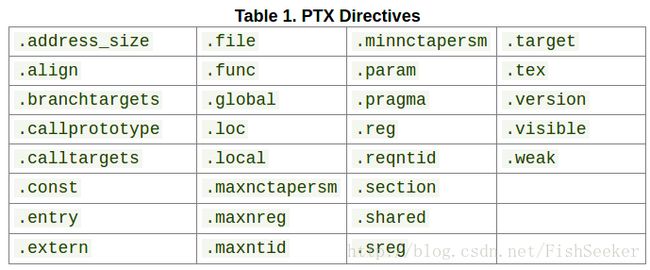
4.3.1. 指示
提供了PTX的指示
4.3.2. 指令
提供了PTX的指令:

ps:关于directive和 instruction这两个词的区别涉及一些汇编上的知识,前者这里翻译为指示,后者这里翻译成指令,因为一般directive并不会产生代码而是指示编译器的一些行为,而instruction则会产生实际的代码,想了解的可以看这里:What-is-the-difference-between-an-instruction-and-a-directive-in-assembly-language
4.4. 标识符
这个大概就是变量名的命名规则吧,基本就和C一样啦,然后系统预定义的变量都是以%开头的大佬变量。
4.5. 常量
这个,我猜,大概是是标号标错了,应该是包含下面各种常量的大标题才对。
4.6. 整型常量
每个整型常量都是64哒,分为有符号和无符号,由.s64和.u64定义,其中各个进制的数是如下定义的:
| X进制 | 表示方式 |
|---|---|
| 十六进制 | 0[xX]{十六进制数}+U? |
| 十进制 | 0{octal 十进制数}+U? |
| 二进制 | 0[bB]{0/1}+U? |
| 小数 | {非零数}{十进制数}*U? |
4.6.1. 浮点常量
浮点数都是64位的,除了用一个32位十六进制去精确表达一个单精度浮点数(黑人问号脸???),具体表达方式如下:
| 精度 | 表达方式 |
|---|---|
| 单精度 | 0[fF]{十六进制数}{8} |
| 双精度 | 0[dD]{十六进制数}{16} |
4.6.2. 判断值常量
0就是false,非零就是true
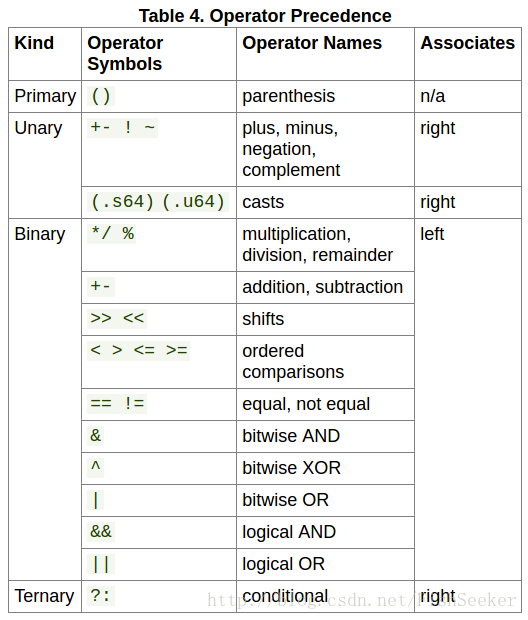
4.6.3. 常量表达式
这个大概是可以对常量能够使用的表达式,也和C基本一致啦:
4.6.4 整型常量表达式求值
和C语言一样一样的
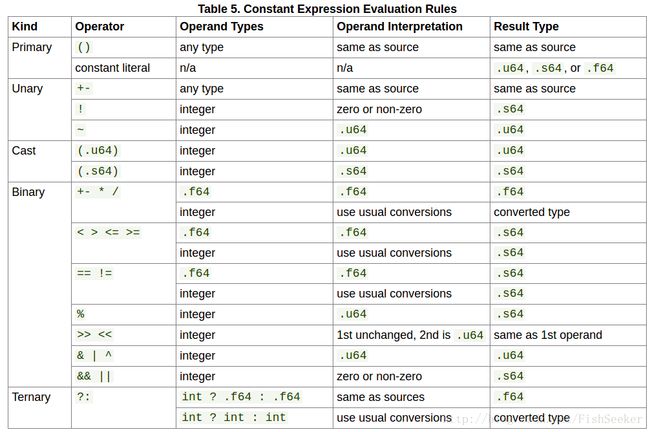
4.6.5 表达式求值规则总结
C语言+1
第五章 状态空间、类型和变量
5.1. 状态空间
这个状态空间就我理解吧,就是在哪块内存上操作。
5.1.1. 寄存器状态空间
利用.reg来声明寄存器状态空间,该空间可以使用几乎形式的数据,但是不同于其他状态空间的是寄存器是没有地址的。
5.1.2. 特殊寄存器状态空间
用.sreg来声明,存的主要是系统预定义的一些变量,比如grid的维数之类的数据。
5.1.3. 常量状态空间
常量状态空间使用.const来表示,被限制在64KB之内。并且被组织成10个区域,驱动要在这十个区域中申请空间,然后可以将这些申请到的空间用指针传递给核函数。
5.1.3.1. 存储体常量寄存器(弃用)
以前这种是需要指定确定的区域号才可以的,就像这样:
.extern .const[2] .b32 const_buffer[];
5.1.4. 全局状态空间
使用ld.global,st.globle和atom.global来访问全局状态空间。而且,访问全局变量空间是没有顺序的,是需要使用bar.sync来同步的。
5.1.5. 本地状态空间
.local声明本地状态空间,而且只能在线程内部使用。
5.1.6. 参数状态空间
参数状态空间被用于1.将输入的参数从主机传递给核函数。2.为在核函数内调用的设备函数声明形式化输入和返回参数。3.声明作为函数调用参数的本地数组,特别是用来传递大的结构体给函数。
5.1.6.1. 核函数参数
.entry foo ( .param .b32 N, .param .align 8 .b8 buffer[64])
{
.reg .u32 %n;
.reg .f64 %d;
ld.param.u32 %n, [N];
ld.param.f64 %d, [buffer];
...5.1.6.2. 核函数参数属性
5.1.6.3. 核函数参数属性: .ptr
使用这个相当于一个指针,还可以指定内存对齐的大小。
.entry foo (
.param .u32 param1,
.param .u32 .ptr.const.align 8 param3,
.param .u32 .ptr.align 16 param4
) { .. }5.1.6.4. 设备函数参数
这个最常用于传递大小和寄存器大小不一样的变量,比如结构体。
.func foo ( .reg .b32 N, .param .align 8 .b8 buffer[12] ) {
.reg .s32 %y;
ld.param.f64 %d, [buffer];
ld.param.s32 %y, [buffer+8];
...
}5.1.7. 共享状态空间
用.shared定义,共享内存有一个特点是可以广播,并且能够顺序访问(有某种一致性机制?)
5.1.8. 纹理状态空间(弃用)
纹理内存也是全局内存的一部分,被上下文的所有线程共享并且是只读的。使用.tex应该被.global里的.texref来代替。就像:
.tex .u32 tex_a;
//转换成下面这样
.global .texref tex_a;5.2. 类型
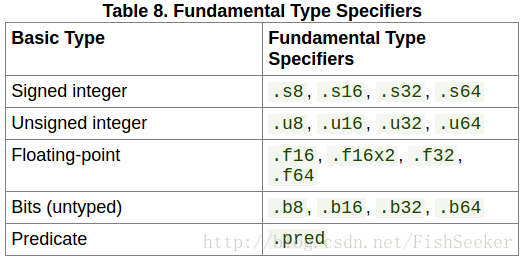
5.2.1. 基本类型
这些基本类型就好像C语言中的int,float之类的,用来定义变量的:
5.2.2. 使用子字段的尺寸限制
像.u8, .s8,和.b8这种类型仅限于在ld,st和cvt中使用。.f16只能被转换成并且只能从.f32,.f64类型。.f16×2这种浮点类型只允许被用在浮点数算法指令和纹理获取指令上。
5.3. 纹理采集器和表面类型
下面这段话是从专家手册里摘录的关于表面引用的解释:
读写纹理和表面的指令相对于其他指令涉及了更多隐秘状态。参数,例如基地址、维度、格式和纹理内容的解释方式,都包含在一个header头结构中。header是一个中间数据结构,它的软件抽象被称为纹理引用(texture reference)或表面引用(surface reference)。
这里有个表用来讲专门为纹理状态空间提供的不透明类型:
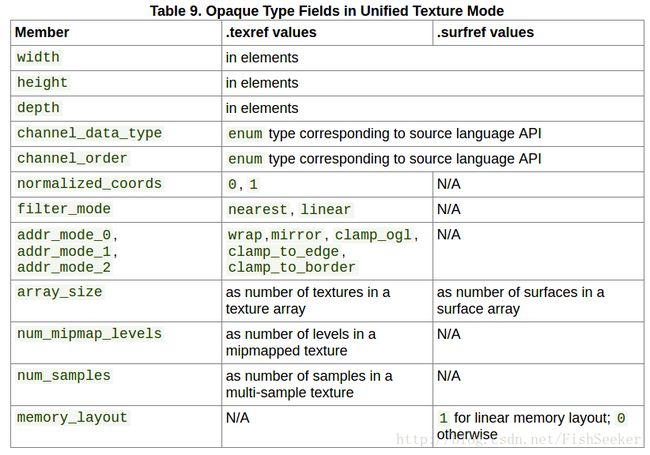
5.3.1. 纹理和表面设置
像上表中所提到的width, height, 和 depth都用来说明纹理内存的大小之类的特性。
5.3.2. 采集器设置
它有各种模式,看CUDA C Programming Guide获取更多细节。
5.3.3. 频道数据类型和频道指令字段
以前之后OpenCL能用,现在都能用了。
讲真,由于对纹理内存了解太少,这节看得很勉强。
5.4. 变量
5.4.1. 变量声明
变量声明需要同时声明状态空间和数据类型比如:
.global .u32 loc;
.reg .s32 i;
.const .f32 bias[] = {-1.0, 1.0};
.global .u8 bg[4] = {0, 0, 0, 0};
.reg .v4 .f32 accel;
.reg .pred p, q, r;5.4.2. 向量
这里的向量的长度是被ptx固定的,只能是2或者4,也不能是判断值(true of false),定义同普通变量:global .v4 .f32 V;
5.4.3. 数组声明
数组的定义和C差不多,可以指定长度也可以不指定然后初始化:
.local .u16 kernel[19][19];
.shared .u8 mailbox[128];
.global .u32 index[] = { 0, 1, 2, 3, 4, 5, 6, 7 };
.global .s32 offset[][2] = { {-1, 0}, {0, -1}, {1, 0}, {0, 1} };5.4.4. 初始化器
对于初始化,是这样的:
.const .f32 vals[8] = { 0.33, 0.25, 0.125 };
.global .s32 x[3][2] = { {1,2}, {3} };
//相当于
.const .f32 vals[4] = { 0.33, 0.25, 0.125, 0.0, 0.0 };
.global .s32 x[3][2] = { {1,2}, {3,0}, {0,0} };当前,变量的初始化只对常量和global状态空间支持,默认的初始化值是0。对于数组,还可以采用以下神奇的方法来初始化:
.const .u32 foo = 42;
.global .u32 p1 = foo; // offset of foo in .const space .global .u32 p2 = generic(foo); // generic address of foo
// array of generic-address pointers to elements of bar .global .u32 parr[] = { generic(bar), generic(bar)+4, generic(bar)+8 };5.4.5. 内存对齐
就是可以在定义数组什么的时候指定内存对齐的大小:
// allocate array at 4-byte aligned address. Elements are bytes. .const .align 4 .b8 bar[8] = {0,0,0,0,2,0,0,0};5.4.6. 参数化的变量名称
这里提供了一种快捷声明变量的方法:.reg .b32 %r<100>; //就相当于声明了 %r0, %r1, ..., %r99
5.4.7. 变量属性
参见下一节
5.4.8. 变量属性指示: .attribute
变量有个.manage属性,这个属性只能在.global状态空间上使用,使用了这个属性之后能召唤神龙可以将变量放置在一个虚拟空间上,这个空间主机和设备都能够访问。具体是这样使用的:.global .attribute(.managed) .s32 g;
第六章 指令操作数
6.1. 操作数类型信息
每个指令里的操作数都要声明其类型,而且类型必须符合指令的模板,并没有自动的类型转换。
6.2. 源操作数
PTX描述的是一个存储读取机,因此对于ALU指令的操作数必须在.reg寄存器状态空间。cvt指令可以的参数有多种类型和大小,可以转换一种类型(或者大小)到另一种类型(或大小)。ld,st,mov和cvt指令从一个地址拷贝数据到另一个地址。ld,st将内容拷贝到寄存器或者从寄存器中拷贝出来,mov指令把数据从一个寄存器换到另一个寄存器。大多数指令有个可选的判断操作,一些指令有附加的判断类型的源操作数,这些经常被定义名为p,q,r,s.
6.3. 目的操作数
用来得到一个结果,一般都在寄存器中。
6.4. 使用地址,数组和向量
6.4.1. 地址作为操作数
就类似各种类型的定义:
.shared .u16 x;
.reg .u16 r0;
.global .v4 .f32 V;
.reg .v4 .f32 W;
.const .s32 tbl[256];
.reg .b32 p; .reg .s32 q;
ld.shared.u16 r0,[x];
ld.global.v4.f32 W, [V];
ld.const.s32 q, [tbl+12];
mov.u32 p, tbl;6.4.2. 数组作为操作数
数组的使用也基本上和C语言是一样的:
ld.global.u32 s, a[0];
ld.global.u32 s, a[N-1];
mov.u32 s, a[1]; // move address of a[1] into s6.4.3. 向量作为操作数
向量的感觉更像是一个结构体或者数组,使用向量可以快速地给多个数复制,很强:
.reg .v4 .f32 V;
.reg .f32 a, b, c, d;
mov.v4.f32 {a,b,c,d}, V;
//也可以反过来
ld.global.v4.f32 {a,b,c,d}, [addr+offset];
ld.global.v2.u32 V2, [addr+offset2];6.4.4. 标记和函数名作为操作数
这个主要是用来获得标记或者函数名,在分支语句中做跳转使用。
6.5. 类型转换
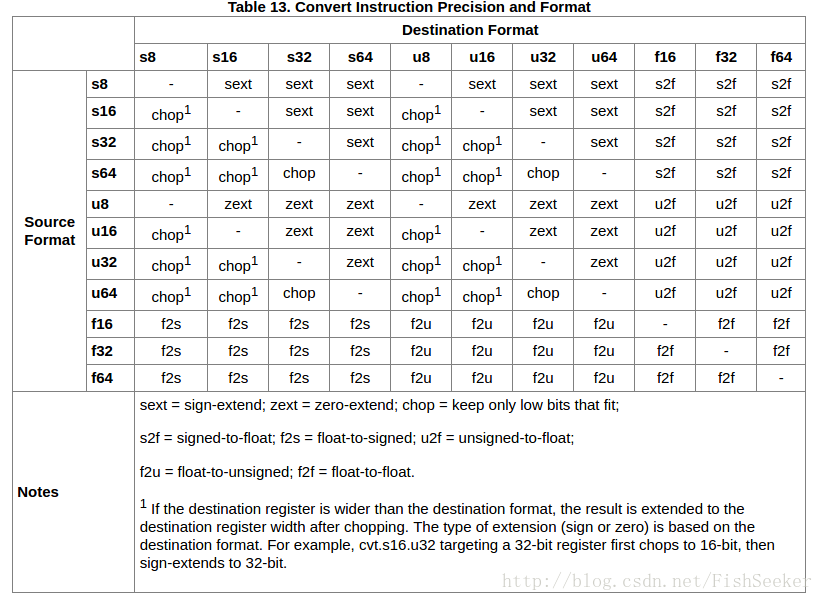
6.5.1. 标量转换
sext:符号扩展。zext:零扩展。chop:只保留低位。s是有符号整数,f是浮点数,u是无符号整数。2就是转换成
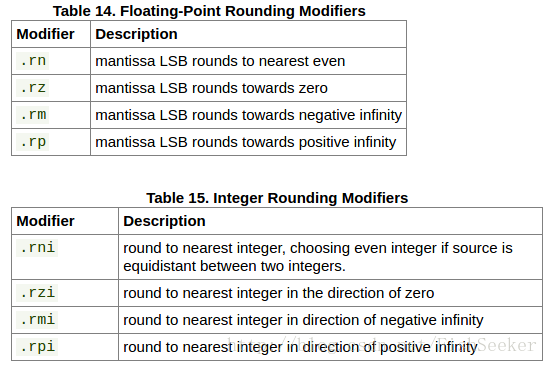
6.5.2. 取整修改器
这里是表示取整的标志,有什么向下取证向上取整之类的。(最低有效位(英语:Least Significant Bit,lsb)是指一个二进制数字中的第0位(即最低位),权值为2^0,可以用它来检测数的奇偶性。)
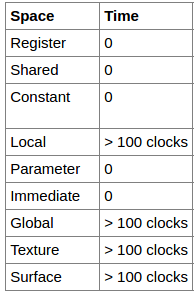
6.6. 操作数耗时
不同状态空空间的操作数会影响一个操作的速度。寄存器最快,全局变量最慢,而多线程可以掩盖这种延迟,或者让取值指令越简单越好。下面是从这些地方取值的延迟:
第七章 抽象ABI
ABI是Application Binary Interface的缩写,翻译过来是二进制程序接口。直白点讲就是系统提供的一系列函数。
7.1. 函数的声明和定义
话不多说就看代码好了
//定义了一个结构体
struct {
double dbl;
char c[4];
};
//有返回值和传入参数
.func (.reg .s32 out) bar (.reg .s32 x, .param .align 8 .b8 y[12])
{
.reg .f64 f1;
.reg .b32 c1, c2, c3, c4;
...
ld.param.f64 f1, [y+0];
ld.param.b8 c1, [y+8];
ld.param.b8 c2, [y+9];
ld.param.b8 c3, [y+10];
ld.param.b8 c4, [y+11];
... ... // computation using x,f1,c1,c2,c3,c4;
}
{
.param .b8 .align 8 py[12];
...
//通过位移来使用参数
st.param.b64 [py+ 0], %rd;
st.param.b8 [py+ 8], %rc1;
st.param.b8 [py+ 9], %rc2;
st.param.b8 [py+10], %rc1;
st.param.b8 [py+11], %rc2;
// scalar args in .reg space, byte array in .param space
call (%out), bar, (%x, py);
...要注意,对于参数的st.param和对返回值的ld.out都必须紧跟着函数调用call。这样才能让编译器优化是的.param不占用多余的空间。并且这个.param允许简单的映射将有多个地址的结构映射到能够传给函数的变量上。
7.1.1. PTX ISA Version 1.x的改变
1.x只支持.reg,后来开始支持.param。
7.2. 列表函数
现在的ptx并不支持列表函数。(不支持说个毛,下一位!)
7.3. Alloca
同上同上