CUDA C最佳实践-CUDA Best Practices(三)
10. 运行配置优化
10.1. 占用
10.1.1. 计算占用
10.2. 同步Kernel执行
10.3. 多上下文
10.4. 隐藏寄存器依赖
10.5. 线程和线程块启发
10.6. 共享内存的效果
11. 指令优化
知道底层命令是怎么执行的对优化来说很有帮助。不过文档建议要在做过所有高级优化之后再对这进行考虑。
11.1. 算数指令
强烈推荐单精度浮点数!!!
11.1.1. 除/取膜 指令
按位操作永远比普通的操作快,比如当n是2的幂的时候,(i>>log2(n))要比i/n快得多。并且i%n和(i & (n-1))也是相等的。详情查看编程指南
11.1.2. 平方根倒数
要求平方根的倒数使用rsqrtf()
11.1.3. 其他算数指令
要避免double向float的自动转换。我们要在常数后面加f来避免这种事情的发生,因为它会增加多余的时钟周期。并且对于单精度浮点数,建议使用单精度的数学函数和操作。而且在普遍意义上来说,单精度比双精度快。
11.1.4. 小指数取幂
这是啥意思呢,看这个表就知道了:

就是说,在这种情况下,要采用的这种组合的情况而不是直接无脑设置分数。
11.1.5. 数学库
当速度要求超过精度时,使用快速数学库。运行时函数库提供两种类型的函数,__functionName() 和 functionName().后面这种一般比较耗时但是比较精确。而且你还能使用-use_fast_math这种操作让nvcc让后面的转换成前面的,当精度要求不高的时候可以使用这个设置。
另外,当计算类似x^2,x^3这样的整数指数的时候,使用连续相乘会比用pow()函数要开销少。
还有,用 sinpi()替换sin(π*),其他三角函数同理。就是反正有专用的函数要用专用的,别瞎整。
11.1.6. 精度相关的编译标志
nvcc有一些编译开关:
- ftz=true (非规格化数据转换成零)
- prec-div=false (精度更低的除法)
- prec-sqrt=false (精度更低的开平方)
- -use_fast_math(精度更低的函数)
11.2. 内存指令
尽量避免使用全局内存。尽可能使用共享内存
12. 控制流
12.1. 分支与分歧
一个warp里尽量不要分支。就是一旦遇到分支,warp里的thread要等其他的都运行完才可以。任何控制流指令(if , switch , do , for , while)都能显著影响到指令吞吐量。
12.2. 分支预测
编译器会展开循环或者优化if来进行分支预测。这样的话,warp就不会有分支。程序猿可以使用#pragma unroll来展开循环。想知道更多滚去看编程指南。
在使用这种分支预测来优化指令时,编译器会给相关于各个线程的指令设置true or false,虽然每个指令都计划被运行,但是实际上只有那些被标记为true的线程执行。这种优化其实是有阈值的,当这个分支的情况少于一定值时会进行替换。
12.3. 有符号或者无符号的循环计数器
用有符号整数做计数器!!!无符号整数溢出被很好地定义,而有符号的没定义,因此编译器就给它优化。比如:
for (i = 0; i < n; i++) {
out[i] = in[offset + stride*i];
}有一个stride*i,可能溢出32位整数,因此如果i被定义为无符号数,溢出控制可能会阻止一些诸如截断之类的优化。如果i被定义为有符号整型,编译器就有机会做优化。
12.4. 循环中的线程同步分支
在分支语句中尽量避免使用__syncthreads().
如果在一些分支语句中使用同步函数,可能会造成无法预计的错误(所以到底是什么错误文档也没说)。
unsigned int imax = blockDim.x * ((nelements + blockDim.x - 1)/ blockDim.x);
for (int i = threadidx.x; i < imax; i += blockDim.x)
{
if (i < nelements)
{
...
}
__syncthreads();
if (i < nelements)
{
...
}
}这里的imax被设置成了warp大小的整数倍,可以解决这一问题。所以在使用同步语句的时候一定要注意。可以使用thread_active标志来指出哪些线程是活动的。
13. 实施CUDA应用
优化之后要将实际结果和期望结果比较,再次APOD循环。在进行更深度的优化之前,先把当前的程序部署起来,这样有很多好处,比如允许使用者对当前的应用进行评估,并且减小了应用的风险因为这是一种循序渐进的演化而不是改革。
14. 理解程序运行环境
要注意两点,一是计算能力,二是CUDA运行时和驱动API的版本。
14.1. CUDA计算能力
可以通过CUDA的一个例子deviceQuery来查看计算能力:
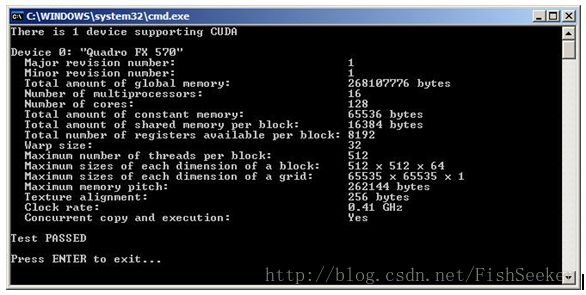
14.2. 额外的硬件数据
其他的硬件数据可以通过cudaGetDeviceProperties()这个函数来获得。
14.3. CUDA运行时和驱动API版本
CUDA运行时和驱动API是程序运行的接口。重点是,CUDA的驱动API是后向兼容而不是前向兼容(向后兼容就是新的版本能用旧的接口,旧的版本不能用新的接口):

14.4. 选择哪个运算能力的版本
在编译的时候可以用-arch 来选择计算能力