Spark集群搭建(三台虚拟机)以及运行实验项目经验总结
Spark集群部署(三台虚拟机)以及在虚拟集群上运行项目经验总结
- 1 实验环境说明
- 1.1 软硬件环境
- 1.2 集群网络环境
- 2 虚拟机环境配置
- 2.1 Vmware下载安装以及在VMware虚拟机安装Ubuntu18.04
- 2.2 网络配置(设置静态IP地址)
- 2.2.1 在VMware中配置网络环境
- 2.2.2 通过Terminal命令行来设置IP地址
- 3 Hadoop2.6.5+Spark2.2.0分布式集群搭建过程
- 3.1 分布式环境搭建
- 3.2 免密ssh配置
- 3.3 Java环境配置
- 3.4 scala环境配置
- 3.5 hadoop环境配置
- 3.6 Spark环境配置
- 3.7 节点环境配置以及测试是否配置成功
- 4 实验代码运行
- 4.1 第一个项目配置
- 4.1.1 项目指定Spark运行说明
- 4.1.2 maven环境配置
- 4.1.3 编译项目给的Spark
- 4.1.4 运行实验代码
- 4.2 第二个项目配置
1 实验环境说明
1.1 软硬件环境
处理器:Intel® Core™ i5-7200U CPU @2.50GHZ 2.71GHZ
主机操作系统:Windows 10,64位
内存: 16G
虚拟软件:VMware Workstation Pro 15
虚拟机操作系统:ubuntu 18.04(64位), 4G内存
虚拟机运行环境:
- jdk 1.8.0_201
- Scala 2.11.8
- Hadoop 2.6.5
- Spark 2.2.3(最开始)(后来因实验要求改为2.2.0)
- maven 3.3.9
- sbt 0.13.11
VMware Workstation Pro 15
卡号:ZG50K-0VF80-4892Q-YGYNV-PLKE4
卡号:FU748-2FX5H-M85ZZ-EMPQC-WF8R0
卡号:YC7HK-FQG90-0883Y-ZYZ7E-Q28ZD
阿里云镜像下载
ubuntu 14.04: http://mirrors.aliyun.com/ubuntu-releases/14.04/
ubuntu 16.04: http://mirrors.aliyun.com/ubuntu-releases/16.04/
ubuntu 18.04: http://mirrors.aliyun.com/ubuntu-releases/18.04/
1.2 集群网络环境
| 序号 | IP地址 | 主机名 | 系统 | User |
|---|---|---|---|---|
| 1 | 192.168.153.100 | Master | Ubuntu18.04 | todd |
| 2 | 192.168.153.101 | Slaver1 | Ubuntu18.04 | todd |
| 3 | 192.168.153.102 | Slaver2 | Ubuntu18.04 | todd |
2 虚拟机环境配置
2.1 Vmware下载安装以及在VMware虚拟机安装Ubuntu18.04
VMware官网下载地址:http://www.vmware.com,最上面有我用的激活号码。安装过程较简单,没有问题。
- 启动VMware,点击“创建新的虚拟机”。
- 点击“自定义”,再点击下一步。

- 选择安装程序光盘镜像文件(ios), 并选择自己的镜像文件,再点击下一步。
- 设置简易安装信息,第一台机器设置为Master,后面通过克隆的时候设置名称为Slaver1和Slaver2(现在还不需要)。然后设置存放位置,设置处理器配置,设置虚拟机内存,设置网络类型(NAT),选择I/O控制器类型(默认),选择磁盘控制器类型(默认),指定磁盘容量(40G),后面一直下一步,直至点击完成,如下图所示。

- 打开Ubuntu,进行必要的更新和设置后,安装网络工具: sudo apt install net-tools。
2.2 网络配置(设置静态IP地址)
2.2.1 在VMware中配置网络环境
- 点击编辑–>> 虚拟网路编辑器,打开虚拟网路编辑器。VMware在默认安装完成之后,会创建三个虚拟的网络环境:VMnet0、VMnet1和VMnet8。其类型分别为:桥接网络,Host-only和NAT。其中,NAT表示VMWware内安装的Ubuntu将会在一个子网中,VMware通过网络地址转换,通过物理机的IP上网。选择NAT方式,来实现Ubuntu的静态IP地址配置。在Vmnet8(NAT)下,点击更改设置,查看子网IP,去掉“使用本地DHCP服务奖IP地址分配给虚拟机”前面的√。这里的子网IP为:192.168.153.0,子网掩码为:255.255.255.0。在后面,我设置三个虚拟机的IP地址分别为192.168.153.100(Master),192.168.153.101(Slaver1),192.168.153.102(Slaver2)。

- 点击NAT设置,查看网关,这里我的网关为192.168.153.2。

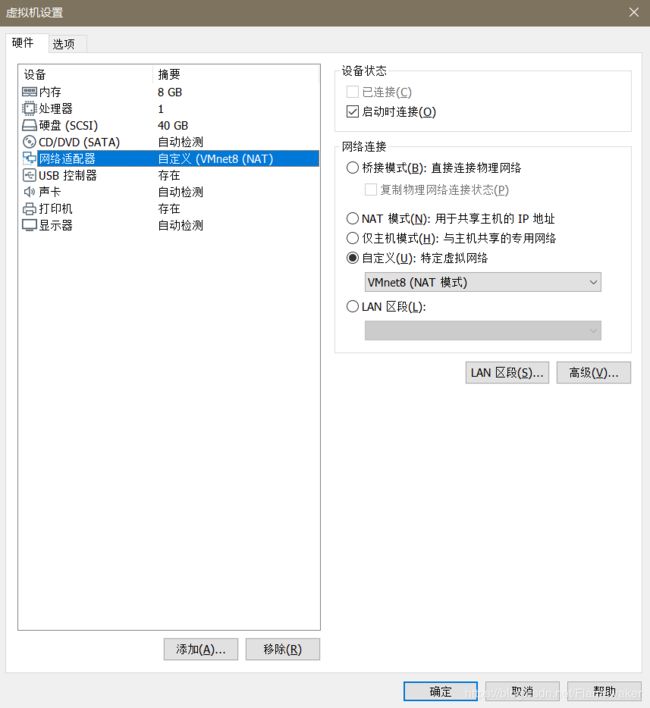
- 右键点击自己建立的虚拟机,点击“设置”,查看如下界面,选择网络适配器,确定网络连接选中的是“自定义”中的VMnet8(NAT模式)。最后点击确定,开启虚拟机。
2.2.2 通过Terminal命令行来设置IP地址
- 打开Ubuntu的终端,输入:sudo gedit /etc/network/interfaces,进行如下编辑并保存。
auto lo
iface lo inet loopback
auto ens33
iface ens33 inet static
address 192.168.153.100
netmask 255.255.255.0
gateway 192.168.153.2
dns-nameservers 223.5.5.5 #解决Ubuntu下 /etc/resolv.conf文件总是自动清除问题的解决方案
注意:系统的不同,上面的网卡端口信息可能会不一样。使用ifconfig命令对相关信息进行查看。

- 配置DNS服务器,在终端中输入:sudo gedit /etc/resolv.conf,进行如下编辑并保存。
nameserver 223.5.5.5。
- 然后,在终端中输入:sudo /etc/init.d/networking restart,重启网络。如果虚拟机不能连接网络,可能有如下几种情况出现:(1)在编写interfaces文件的时候,存在编写错误。(2)网卡端口ens33填写错误,可以使用ifconfig命令进行查看。(3)某些时候,重启虚拟机发现连接不了网络,可以检查/etc/resolv.conf文件,我有几次重启系统后,该文件DNS信息发生了变化。(4)(未验证)重启系统之后,发现网络无法使用,右上角的网络图标点击之后显示“device not managed”。解决方法:sudo gedit /etc/NetworkManager/NetworkManager.conf。打开该文件,将“managed=false”修改为“managed=true”。重启network manager:sudo service network-manager restart。
3 Hadoop2.6.5+Spark2.2.0分布式集群搭建过程
可以参考使用VMware进行基于Ubuntu16.04LTS的Spark集群搭建
3.1 分布式环境搭建
- 在进行分布式环境的搭建时候,可以先搭建基础环境,如java环境、scala环境等,再对Master虚拟机进行克隆,可以省去不少时间。也可以在Master虚拟机上搭建相关环境,再将相关环境配置文件发送到其他节点,这里看个人需求。下面步骤中,我在Master虚拟机上搭建相关环境后,再拷贝环境在其他节点上。
- 修改hosts文件,将IP与主机名的映射添加到每一台机器的hosts文件中 。在终端中输入:sudo gedit /etc/hosts,进行如下编辑并保存。
192.168.153.100 Master
192.168.153.101 Slaver1
192.168.153.102 Slaver2
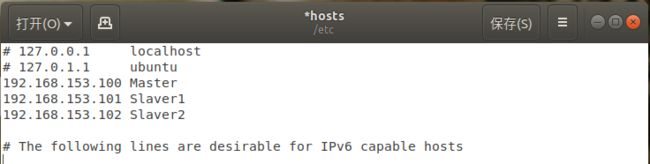
修改完成后保存执行如下命令:source /etc/hosts
4. 关闭虚拟机,在Vmware界面对Master进行克隆,克隆出两个节点Slaver1和Slaver2。
5. 在每个机器上使用以下命令修改本机名称:sudo gedit /etc/hostname。分别改成Master,Slaver1,Slaver2。
6. 在每个机器的/etc/network/interfaces中,按照2.2.2中所示,将机器的ip设置为static,并分别分配固定ip。分别为:192.168.153.100,192.168.153.101,192.168.153.102。
7. 对虚拟机进行重启,使相关配置生效。
3.2 免密ssh配置
- 在三台虚拟机中,使用以下命令安装ssh:sudo apt-get install openssh-server
- 在Master节点上进行ssh配置,在Master节点上执行以下命令:
su root
cd /root/.ssh
ssh-keygen -t rsa #产生公钥与私钥对,执行三次回车
ssh-copy-id -i /root/.ssh/id_rsa.pub Master #用ssh-copy-id将公钥复制到远程机器中,ssh-copy-id 将key写到远程机器的 ~/ .ssh/authorized_key.文件中
- 将Master的公钥添加到另外2台机器上:
ssh-copy-id -i /root/.ssh/id_rsa.pub Slaver1
ssh-copy-id -i /root/.ssh/id_rsa.pub Slaver2
- 在Master上对每一个节点进行测试,看是否能进行免密登录:
ssh Slaver1(ssh root@Slaver1)。
3.3 Java环境配置
- 在/usr目录下新建java文件夹,然后将jdk压缩包复制在java文件夹下并进行解压。执行:
cd /usr
mkdir java
sudo tar -zxvf jdk-8u8201-linux-x64.tar.gz
- 在/etc/profile内配置环境变量:gedit /etc/profile。添加如下信息:
export JAVA_HOME=/usr/java/jdk1.8.0_201
export CLASSPATH=:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
- 刷新环境配置。然后检测Java版本:
source /etc/profile
java -version
3.4 scala环境配置
- 将jdk压缩包复制在java文件夹下并进行解压。执行:
sudo tar -zxvf scala-2.11.8.tgz
- 在/etc/profile内配置环境变量:gedit /etc/profile。添加如下信息:
export SCALA_HOME=/usr/scala-2.11.8
export PATH=$PATH:$SCALA_HOME/bin
- 刷新环境配置。然后检测scala版本:
source /etc/profile
scala -version
3.5 hadoop环境配置
可以参考Hadoop2.7.3+Spark2.1.0完全分布式集群搭建过程
- 下载二进制包hadoop-2.6.5.tar.gz。
- 解压并移动到/usr目录:
mv hadoop-2.6.5.tar.gz
tar -zxvf hadoop-2.6.5.tar.gz
- 修改相应的配置文件。修改/etc/profile,增加如下内容:
export HADOOP_HOME=/usr/hadoop-2.6.5
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
- 在hadoop-2.6.5目录下添加目录:
mkdir tmp
mkdir hdfs
mkdir hdfs/name
mkdir hdfs/data
- 修改$HADOOP_HOME/etc/hadoop/hadoop-env.sh,修改JAVA_HOME 如下:
export JAVA_HOME=/usr/java/jdk1.8.0_201
- 修改$HADOOP_HOME/etc/hadoop/slaves,将原来的localhost删除,添加如下内容:
Slaver1
Slaver2
- 修改$HADOOP_HOME/etc/hadoop/core-site.xml,修改为如下内容:
fs.defaultFS
hdfs://Master:9000
io.file.buffer.size
131072
hadoop.tmp.dir
/usr/hadoop-2.6.5/tmp
- 修改$HADOOP_HOME/etc/hadoop/hdfs-site.xml。
dfs.namenode.secondary.http-address
Master:50090
dfs.replication
2
dfs.namenode.name.dir
file:/usr/hadoop-2.6.5/hdfs/name
dfs.datanode.data.dir
file:/usr/hadoop-2.6.5/hdfs/data
- 在$HADOOP_HOME/etc/hadoop目录下复制template,生成xml,命令如下:
cp mapred-site.xml.template mapred-site.xml
修改$HADOOP_HOME/etc/hadoop/mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
Master:10020
mapreduce.jobhistory.address
Master:19888
- 修改$HADOOP_HOME/etc/hadoop/yarn-site.xml。
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.address
Master:8032
yarn.resourcemanager.scheduler.address
Master:8030
yarn.resourcemanager.resource-tracker.address
Master:8031
yarn.resourcemanager.admin.address
Master:8033
yarn.resourcemanager.webapp.address
Master:8088
3.6 Spark环境配置
- 下载二进制包spark-2.2.3-bin-hadoop2.6.tgz
- 解压并移动到相应目录,命令如下:
tar -zxvf spark-2.2.3-bin-hadoop2.6.tgz
- 修改/etc/profie,增加如下内容:
export SPARK_HOME=/usr/spark-2.4.0-bin-hadoop2.6/
export PATH=$PATH:$SPARK_HOME/bin
- 在$SPARK_HOME/conf/目录下复制spark-env.sh.template成spark-env.sh
cp spark-env.sh.template spark-env.sh
修改$SPARK_HOME/conf/spark-env.sh,添加如下内容:
export SCALA_HOME=/usr/scala-2.11.8
export JAVA_HOME=/usr/java/jdk1.8.0_201
export HADOOP_HOME=/usr/hadoop-2.6.5
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/usr/hadoop-2.6.5/etc/hadoop
- 在$SPARK_HOME/conf/目录下复制slaves.template成slaves
cp slaves.template slaves
修改$SPARK_HOME/conf/slaves,添加如下内容:
Master
Slaver1
Slaver2
3.7 节点环境配置以及测试是否配置成功
- 将配置好的环境拷贝到Slaver1和Slaver2节点。
scp -r /usr/java root@Slaver1:/usr
scp -r /usr/scala-2.11.8 root@Slaver1:/usr
scp -r /usr/hadoop-2.6.5 root@Slaver1:/usr
scp -r /usr/spark-2.2.3-bin-hadoop2.6 root@Slaver1:/usr
scp -r /etc/profile root@Slaver1:/etc/profile
scp -r /usr/java root@Slaver2:/usr
scp -r /usr/scala-2.11.8 root@Slaver2:/usr
scp -r /usr/hadoop-2.6.5 root@Slaver2:/usr
scp -r /usr/spark-2.2.3-bin-hadoop2.6 root@Slaver2:/usr
scp -r /etc/profile root@Slaver2:/etc/profile
- 在每个节点上刷新环境配置: source /etc/profile。
可以ssh登录后进行刷新:
ssh Slaver1
source /etc/profile
exit
ssh Slaver2
source /etc/profile
exit
- 在Master节点启动Hadoop,启动之前格式化一下namenode:
hadoop namenode -format
启动:
/usr/hadoop-2.6.5/sbin/start-all.sh
-
查看Hadoop是否启动成功,输入命令:jps
Master显示:SecondaryNameNode,ResourceManager,NameNode。
Slaver显示:NodeManager,DataNode。 -
在Master节点启动Spark:/usr/spark-2.4.0-bin-hadoop2.6/sbin/start-all.sh
-
查看Spark是否启动成功,输入命令:jps
Master在Hadoop的基础上新增了:Master。
Slaver在Hadoop的基础上新增了:Worker。 -
集群测试。在spark启动成功后,执行以下代码(spark自带的一个例子),出现结果即为成功:$SPARK_HOME/bin/spark-submit --class org.apache.spark.examples.SparkPi --master local /usr/spark-2.2.3-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.2.3.jar(./bin/run-example org.apache.spark.examples.SparkPi)
-
错误及解决方案1:hadoop在子节点上没有datanode进程。1)先停止Hadoop,bin/stop-all.sh
2)三台机器都把hadoop1.2.1/tmp下所有文件删除,rm -rf tmp/* 3)重新格式化hadoop namenode -format 4)再重启bin/start-all.sh 5)查看各节点jps,就有DataNode了。在这之前最好查看下每个节点的/etc/hosts文件是否正确。 -
错误及解决方案2:hadoop集群启动之后,datanode进程未启动解决办法。一般是开启一次hadoop集群,重新 hadoop namenode -format就会出现问题。可以参考hadoop集群启动之后,datanode进程未启动解决办法。
4 实验代码运行
4.1 第一个项目配置
4.1.1 项目指定Spark运行说明


4.1.2 maven环境配置
Spark源码使用maven构建的,所以在编译之前我们需要下载一个maven。
- 将安装包解压到指定目录:tar -zxvf apache-maven-3.3.9-bin.tar.gz
- 配置maven环境变量:
sudo gedit /etc/profile
添加如下内容:
#maven
export MAVEN_HOME=/usr/apache-maven-3.3.9
export PATH=\$PATH:\$MAVEN_HOME/bin
export MAVEN_OPTS="-Xmx2048m -XX:MetaspaceSize=1024m -XX:MaxMetaspaceSize=1524m -Xss2m"
export PATH=\$PATH:\$MAVEN_HOME/bin
虚拟机推荐设置内存4G,一定要大于MAVEN_OPTS中设置的最大内存。
- 刷新环境配置:source /etc/profile
- 测试maven是否安装成功: mvn -version
- 建议修改maven的安装目录下的conf/settings.xml文件中添加如下配置,以达到jar下载加速的效果。
alimaven
aliyun maven
http://maven.aliyun.com/nexus/content/groups/public/
central
4.1.3 编译项目给的Spark
- 如果scala 版本为2.10 ,需要进行 ./dev/change-scala-version.sh 2.10。我的版本为2.11.8,所以执行了这个命令 ./dev/change-scala-version.sh 2.11
- 使用命令进行编译。
./build/mvn -Pyarn -Phadoop-provided -Phive -Phive-thriftserver -Pnetlib-lgpl -DskipTests clean package
- 编译了好几次,总是出错(后来修改了命令),等就完事了,大概50分钟,编译成功。
- 按照该项目所说,进行相应的设置后,该Spark就可以使用了。注意给该spark文件夹赋予相应的权限:sudo chmod -R 777 *。其他节点Spark配置参照前面的操作。
4.1.4 运行实验代码
可以参考idea打spark jar包并提交到spark集群运行
- 上传相关需读取的文件到hdfs(略)。可以参考HDFS基本命令行操作及上传文件的简单API,Linux上传本地文件到Hadoop的HDFS文件系统。
- 修改代码。主要是关于集群的端口设置和读取文件位置。
- 打包文件:File–>>ProjectStructure -->点击Artificats–>>点击绿色加号 --> 点击JAR–>>选择 From module with dependices。点击Output Layout 看看是否没有第三方jar包,因为使用spark集群环境,所以不需要第三方jar包,将他们去掉。这一步中要注意类名是否和之后提交的一致。
- 重新build:Build–>>Build Artifcat …—>>build 或者rebuild
- 在命令行中提交运行:$SPARK_HOME/bin/spark-submit --class xxxxxxx.xxxx.ExampleApp --master spark://192.168.153.100:7077 /usr/xxxx/xxxx-standalone/xxxx/out/artifacts/xxxx_jar/xxxx.jar
- 本地IDEA运行错误问题:IDEA运行scala程序报错:Error:scalac: bad option: ‘-make:transitive’
解决方案:1)找到该项目的所在目录,进入这个项目根目录下;2)执行命令:cd .idea;
3)打开scala_compiler.xml文件,将下面行注释掉;4)重启IDEA即可。
4.2 第二个项目配置
可以参考在Linux系统中安装sbt
- sbt-launch.jar的下载地址
- 安装在 /usr/local/sbt 中:
sudo mkdir /usr/local/sbt
sudo chown -R hadoop /usr/local/sbt # 此处的 hadoop 为你的用户名
cd /usr/local/sbt
- 下载后,执行如下命令拷贝至 /usr/local/sbt 中:
cp ~/下载/sbt-launch.jar .
- 接着在 /usr/local/sbt 中创建 sbt 脚本(vim ./sbt),添加如下内容:
#!/bin/bash
SBT_OPTS="-Xms512M -Xmx1536M -Xss1M -XX:+CMSClassUnloadingEnabled -XX:MaxPermSize=256M"
java $SBT_OPTS -jar `dirname $0`/sbt-launch.jar "$@"
- 保存后,为 ./sbt 脚本增加可执行权限:
chmod u+x ./sbt
- 最后运行如下命令,检验 sbt 是否可用(时间较长),最后出现版本信息。
./sbt sbt-version
- 一些注意事项可以参考解决sbt无法下载依赖包的问题
- 用assembly打包, 由于在项目文件中已经对相关sbt进行了设置,所以在主目录直接输入sbt asembly即可进行打包。相关配置可以参考sbt插件安装及使用。最后生成./target/scala_x.x.x/projectname-assembly-x.x.x.jar
- 实验代码运行:$SPARK_HOME/bin/spark-submit --class xxx.xxxx.xx.xxxxxxx.BaseLine --master spark://192.168.153.100:7077 /usr/xx-xxx-xxx/target/scala-2.11/traj-sim_2.11-1.0.jar