Kylin三大引擎和Cube构建源码解析
最近在工作中用到了kylin,相关资料还不是很多,关于源码的更是少之又少,于是结合《kylin权威指南》、《基于Apache Kylin构建大数据分析平台》、相关技术博客和自己对部分源码的理解进行了整理。
一、工作原理
每一个Cube都可以设定自己的数据源、计算引擎和存储引擎,这些设定信息均保存在Cube的元数据中。在构建Cube时,首先由工厂类创建数据源、计算引擎和存储引擎对象。这三个对象独立创建,相互之间没有关联。
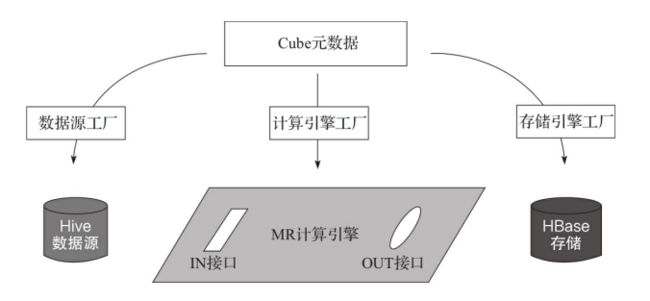
要把它们串联起来,使用的是适配器模式。计算引擎好比是一块主板,主控整个Cube的构建过程。它以数据源为输入,以存储为Cube的输出,因此也定义了IN和OUT两个接口。数据源和存储引擎则需要适配IN和OUT,提供相应的接口实现,把自己接入计算引擎,适配过程见下图。适配完成之后,数据源和存储引擎即可被计算引擎调用。三大引擎连通,就能协同完成Cube构建。
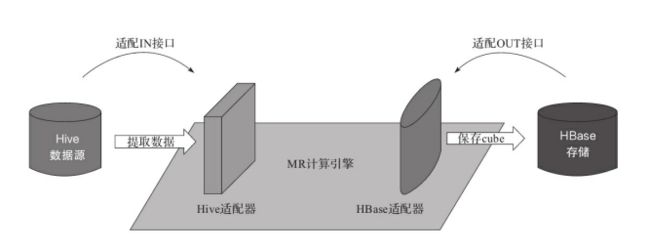
计算引擎只提出接口需求,每个接口都可以有多种实现,也就是能接入多种不同的数据源和存储。类似的,每个数据源和存储也可以实现多个接口,适配到多种不同的计算引擎上。三者之间是多对多的关系,可以任意组合,十分灵活。
二、三大主要接口
(一)数据源接口
ISource
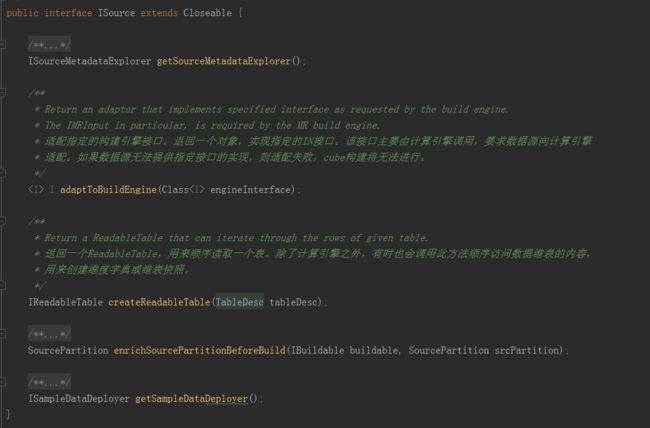
·
adaptToBuildEngine
:适配指定的构建引擎接口。返回一个对象,实现指定的IN接口。该接口主要由计算引擎调用,要求数据源向计算引擎适配。如果数据源无法提供指定接口的实现,则适配失败,Cube构建将无法进行。
·
createReadableTable
:返回一个ReadableTable,用来顺序读取一个表。除了计算引擎之外,有时也会调用此方法顺序访问数据维表的内容,用来创建维度字典或维表快照。
(二)存储引擎接口
IStorage
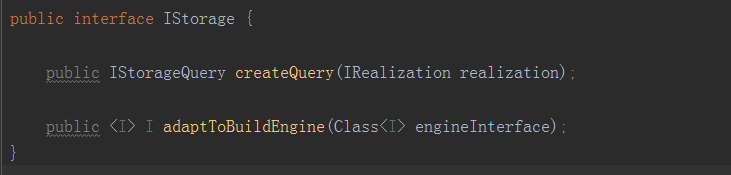
·
adaptToBuildEngine
:适配指定的构建引擎接口。返回一个对象,实现指定的OUT接口。该接口主要由计算引擎调用,要求存储引擎向计算引擎适配。如果存储引擎无法提供指定接口的实现,则适配失败,Cube构建无法进行。
·
createQuery
:创建一个查询对象IStorageQuery,用来查询给定的IRealization。简单来说,就是返回一个能够查询指定Cube的对象。IRealization是在Cube之上的一个抽象。其主要的实现就是Cube,此外还有被称为Hybrid的联合Cube。
(三)计算引擎接口
IBatchCubingEngine
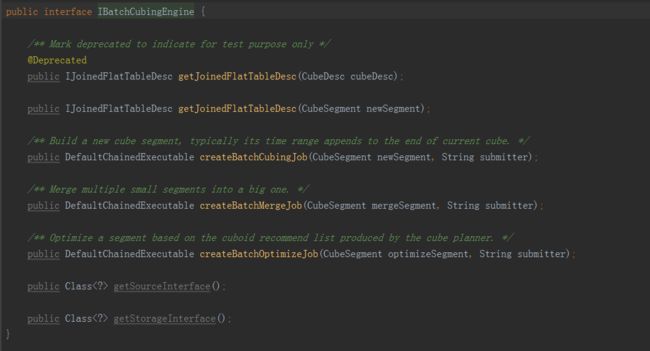
·
createBatchCubingJob
:返回一个工作流计划,用以构建指定的CubeSegment。这里的CubeSegment是一个刚完成初始化,但还不包含数据的CubeSegment。返回的DefaultChainedExecutable是一个工作流的描述对象。它将被保存并由工作流引擎在稍后调度执行,从而完成Cube的构建。
·
createBatchMergeJob
:返回一个工作流计划,用以合并指定的CubeSegment。这里的CubeSegment是一个待合并的CubeSegment,它的区间横跨了多个现有的CubeSegment。返回的工作流计划一样会在稍后被调度执行,执行的过程会将多个现有的CubeSegment合并为一个,从而降低Cube的碎片化成都。
·
getSourceInterface
:指明该计算引擎的IN接口。
·
getStorageInterface
:指明该计算引擎的OUT接口。
三、三大引擎互动过程
1.Rest API接收到构建(合并)CubeSegment的请求。
2.EngineFactory根据Cube元数据的定义,创建IBatchCubingEngine对象,并调用其上的createBatchCubingJob(或者createBatchMergeJob)方法。
3.IBatchCubingEngine根据Cube元数据的定义,通过SourceFactory和StorageFactory创建出相应的数据源ISource和存储IStorage对象。
4.IBatchCubingEngine调用ISource上的adaptToBuildEngine方法传入IN接口,要求数据源向自己适配。
5.IBatchCubingEngine调用IStorage上的adaptToBuildEngine方法,传入OUT接口,要求存储引擎向自己适配。
6.适配成功后,计算引擎协同数据源和存储引擎计划Cube构建的具体步骤,将结果以工作流的形式返回。
7.执行引擎将在稍后执行工作流,完成Cube构建。
四、Kylin默认三大引擎Hive+MapReduce+HBase的介绍和代码实现
(一)构建引擎MapReduce
每一个构建引擎必须实现接口
IBatchCubingEngine
,并在EngineFactory中注册实现类。只有这样才能在Cube元数据中引用该引擎,否则会在构建Cube时出现“找不到实现”的错误。
注册的方法是通过kylin.properties来完成的。在其中添加一行构建引擎的声明。比如:
![]()
EngineFactory在启动时会读取kylin.properties,默认引擎即为标号2的MRBatchCubingEngine2这个引擎。
1.
MRBatchCubingEngine2
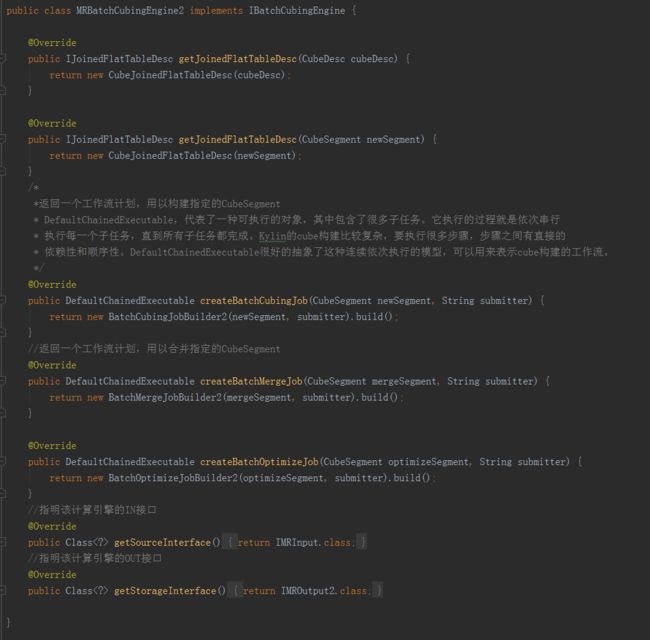
这是一个入口类,构建Cube的主要逻辑都封装在BatchCubingJobBuilder2和BatchMergeJobBuilder2中。其中的DefaultChainedExecutable,代表了一种可执行的对象,其中包含了很多子任务。它执行的过程就是一次串行执行每一个子任务,直到所有子任务都完成。kylin的构建比较复杂,要执行很多步骤,步骤之间有直接的依赖性和顺序性。DefaultChainedExecutable很好地抽象了这种连续依次执行的模型,可以用来表示Cube的构建的工作流。
另外,重要的输入输出接口也在这里进行声明。IMRInput是IN接口,由数据源适配实现;IMROutput2是OUT接口,由存储引擎适配实现。
2.
BatchCubingJobBuilder2
BatchCubingJobBuilder2和BatchMergeJobBuilder2大同小异,这里以BatchCubingJobBuilder2为例。

BatchCubingJobBuilder2中的成员变量IMRBatchCubingInputSide inputSide和IMRBatchCubingOutputSide2 outputSide分别来自数据源接口IMRInput和存储接口IMROutput2,分别代表着输入和输出两端参与创建工作流。
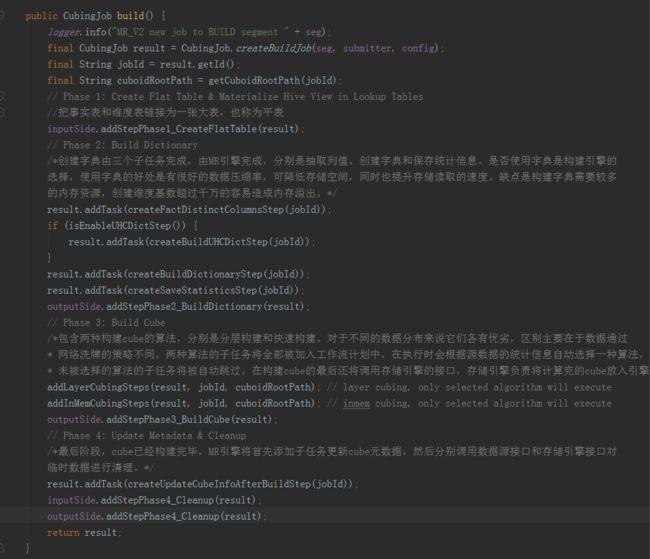
BatchCubingJobBuilder2的主体函数build()中,整个Cube构建过程是一个子任务一次串行执行的过程,这些子任务又被分为四个阶段。
第一阶段:创建平表。
这一阶段的主要任务是预计算连接运算符,把事实表和维表连接为一张大表,也称为平表。这部分工作可通过调用数据源接口来完成,因为数据源一般有现成的计算表连接方法,高效且方便,没有必要在计算引擎中重复实现。
第二阶段:创建字典。
创建字典由三个子任务完成,由MR引擎完成,分别是抽取列值、创建字典和保存统计信息。是否使用字典是构建引擎的选择,使用字典的好处是有很好的数据压缩率,可降低存储空间,同时也提升存储读取的速度。缺点是构建字典需要较多的内存资源,创建维度基数超过千万的容易造成内存溢出。
第三阶段:构建Cube。
其中包含两种构建cube的算法,分别是分层构建和快速构建。对于不同的数据分布来说它们各有优劣,区别主要在于数据通过网络洗牌的策略不同。两种算法的子任务将全部被加入工作流计划中,在执行时会根据源数据的统计信息自动选择一种算法,未被选择的算法的子任务将被自动跳过。在构建cube的最后还将调用存储引擎的接口,存储引擎负责将计算完的cube放入引擎。
第四阶段:更新元数据和清理。
最后阶段,cube已经构建完毕,MR引擎将首先添加子任务更新cube元数据,然后分别调用数据源接口和存储引擎接口对临时数据进行清理。
3.
IMRInput
这是BatchCubingJobBuilder2对数据源的要求,所有希望接入MRBatchCubingEngine2的数据源都必须实现该接口。
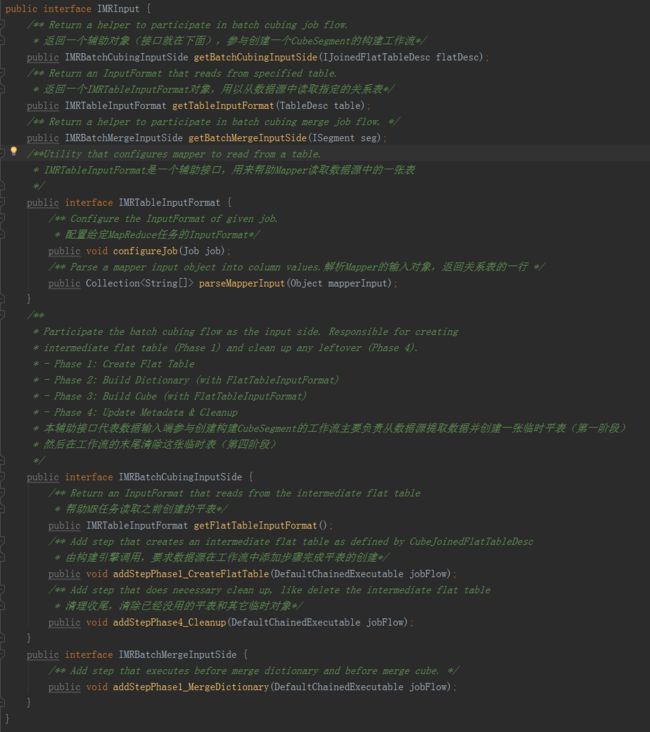
·
getTableInputFormat
方法返回一个IMRTableInputFormat对象,用以帮助MR任务从数据源中读取指定的关系表,为了适应MR编程接口,其中又有两个方法,configureJob在启动MR任务前被调用,负责配置所需的InputFormat,连接数据源中的关系表。由于不同的InputFormat所读入的对象类型各不相同,为了使得构建引擎能够统一处理,因此又引入了parseMapperInput方法,对Mapper的每一行输入都会调用该方法一次,该方法的输入是Mapper的输入,具体类型取决于InputFormat,输出为统一的字符串数组,每列为一个元素。整体表示关系表中的一行。这样Mapper救能遍历数据源中的表了。
·
getBatchCubingInputSide
方法返回一个IMRBatchCubingInputSide对象,参与创建一个CubeSegment的构建工作流,它内部包含三个方法,addStepPhase1_CreateFlatTable()方法由构建引擎调用,要求数据源在工作流中添加步骤完成平表的创建;getFlatTableInputFormat()方法帮助MR任务读取之前创建的平表;addStepPhase4_Cleanup()是进行清理收尾,清除已经没用的平表和其它临时对象,这三个方法将由构建引擎依次调用。
4.
IMROutput2
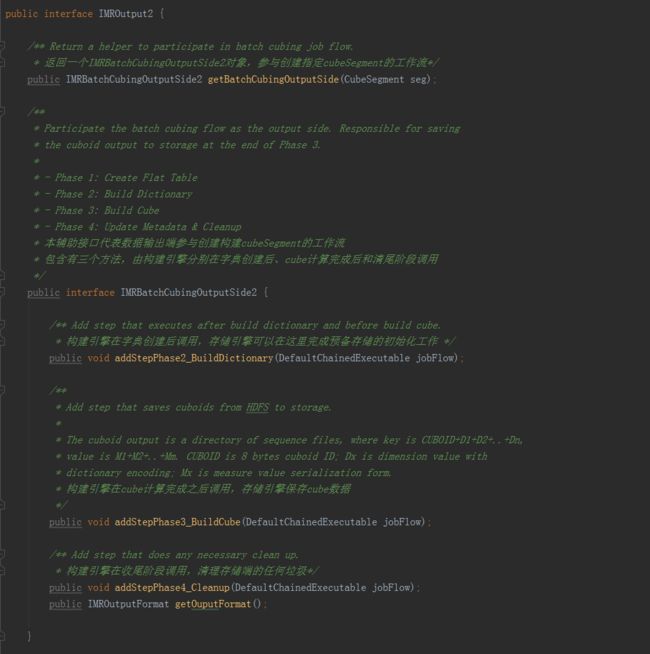
这是BatchCubingJobBuilder2对存储引擎的要求,所有希望接入BatchCubingJobBuilder2的存储都必须实现该接口。
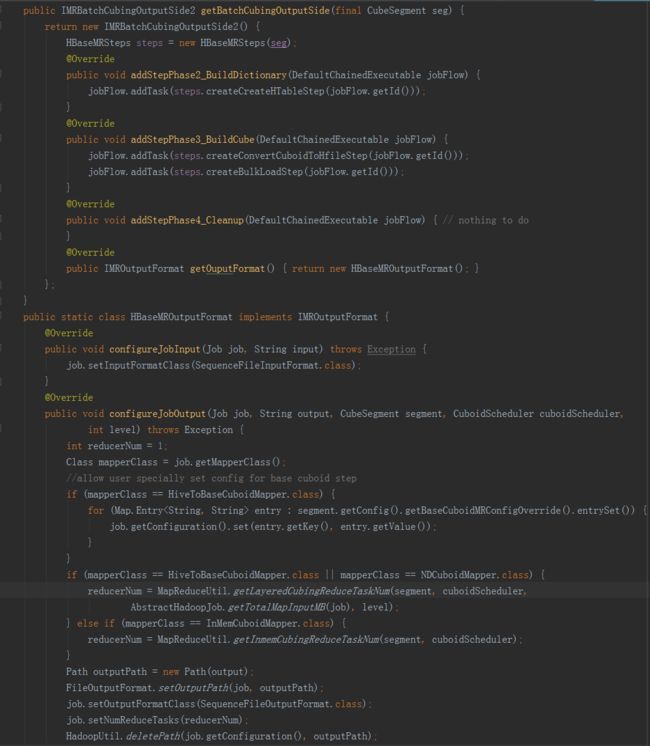
IMRBatchCubingOutputSide2代表存储引擎配合构建引擎创建工作流计划,该接口的内容如下:
·
addStepPhase2_BuildDictionary
:由构建引擎在字典创建后调用。存储引擎可以借此机会在工作流中添加步骤完成存储端的初始化或准备工作。
·
addStepPhase3_BuildCube
:由构建引擎在Cube计算完毕之后调用,通知存储引擎保存CubeSegment的内容。每个构建引擎计算Cube的方法和结果的存储格式可能都会有所不同。存储引擎必须依照数据接口的协议读取CubeSegment的内容,并加以保存。
·
addStepPhase4_Cleanup
:由构建引擎在最后清理阶段调用,给存储引擎清理临时垃圾和回收资源的机会。
(二)数据源Hive
Hive是kylin的默认数据源,由于数据源的实现依赖构建引擎对输入接口的定义,因此本节的具体内容只适用于MR引擎。
数据源
HiveSource
首先要实现
ISource
接口。
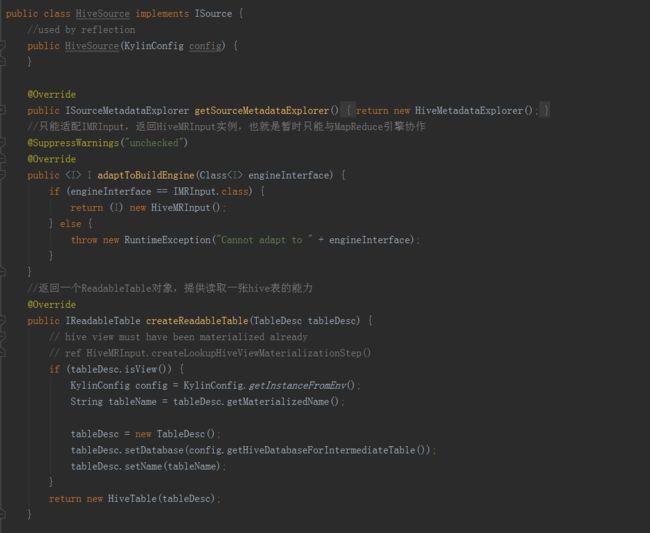
HiveSource实现了ISource接口中的方法。adaptToBuildEngine()只能适配IMRInput,返回HiveMRInput实例。另一个方法createReadableTable()返回一个ReadableTable对象,提供读取一张hive表的能力。
HiveMRInput


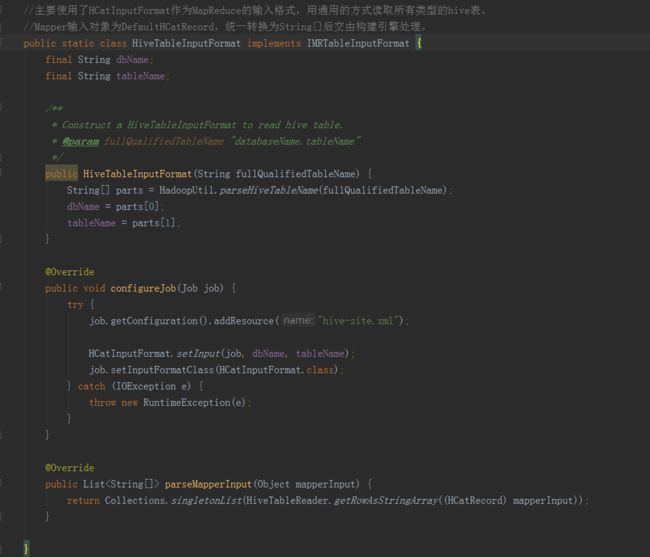
HiveMRInput实现了IMRInput接口,实现了它的两个方法。
一是HiveTableInputFormat实现了IMRTableInputFormat接口,它主要使用了HCatInputFormat作为MapReduce的输入格式,用通用的方式读取所有类型的Hive表。Mapper输入对象为DefaultHCatRecord,统一转换为String[]后交由构建引擎处理。
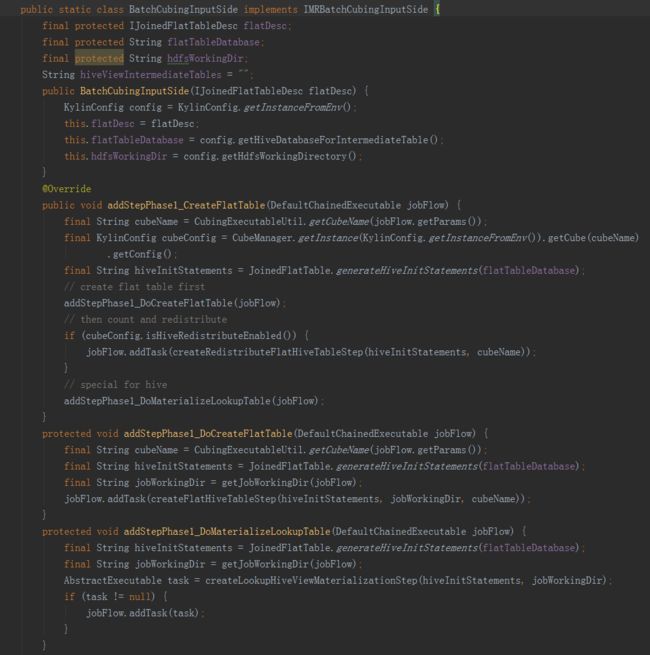
二是BatchCubingInputSide实现了IMRBatchCubingInputSide接口。主要实现了在构建的第一阶段创建平表的步骤。首先用count(*)查询获取Hive平表的总行数,然后用第二句HQL创建Hive平表,同时添加参数根据总行数分配Reducer数目。
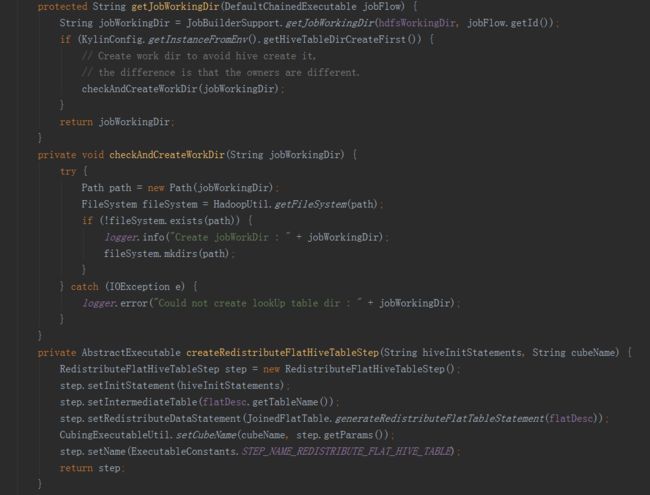

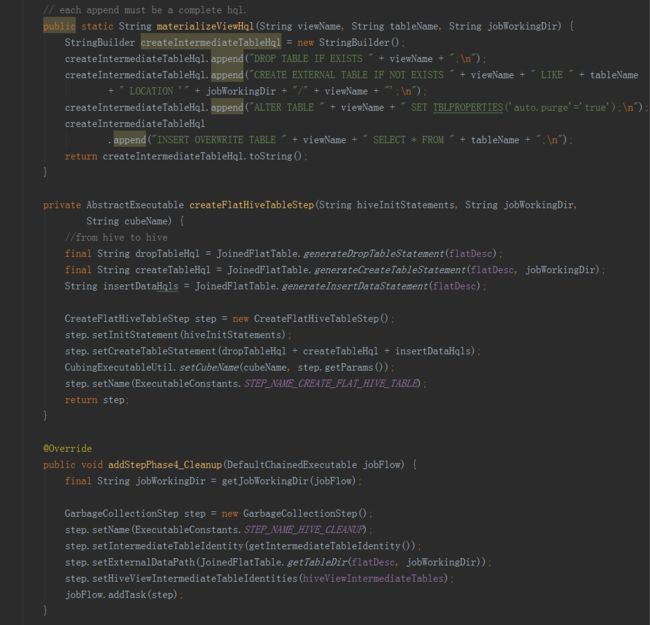
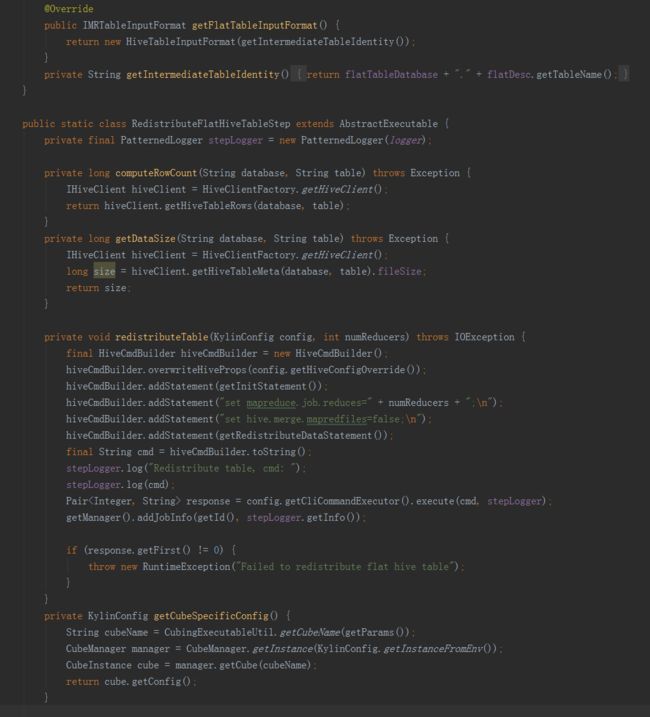

(三)存储引擎HBase
存储引擎
HBaseStorage
实现了
IStorage
接口。
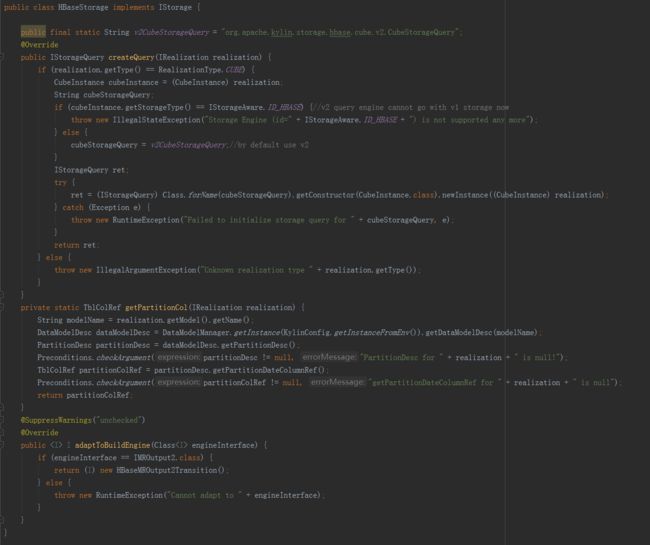
·
createQuery
方法,返回指定IRealization(数据索引实现)的一个查询对象。因为HBase存储是为Cube定制的,所以只支持Cube类型的数据索引。具体的IStorageQuery实现应根据存储引擎的版本而有所不同。
·
adaptToBuildEngine
方法,适配IMROutput2的输出接口。
HBaseMROutput2
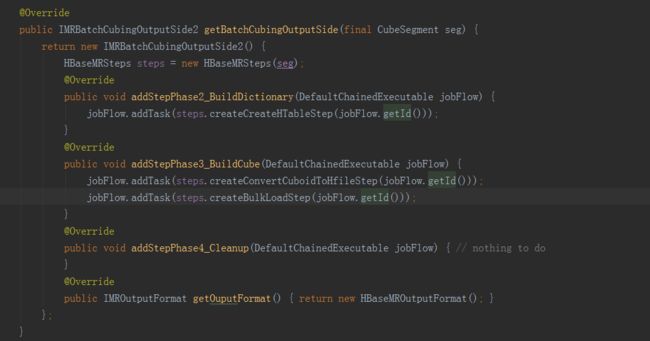
观察IMRBatchCubingOutputSide2的实现。它在两个时间点参与Cube构建的工作流。一是在字典创建之后(Cube构造之前),在addStepPhase2_BuildDictionary()中添加了“创建HTable”这一步,估算最终CubeSegment的大小,并以此来切分HTable Regions,创建HTable。
第二个插入点是在Cube计算完毕之后,由构建引擎调用addStepPhase3_BuildCube()。这里要将Cube保存为HTable,实现分为“转换HFile”和“批量导入到HTable”两步。因为直接插入HTable比较缓慢,为了最快速地将数据导入到HTable,采取了Bulk Load的方法。先用一轮MapReduce将Cube数据转换为HBase的存储文件格式HFile,然后就可以直接将HFile导入空的HTable中,完成数据导入。
最后一个插入点是addStepPhase4_Cleanup()是空实现,对于HBase存储来说没有需要清理的资源。
五、CubingJob的构建过程
在Kylin构建CubeSegment的过程中,计算引擎居于主导地位,通过它来协调数据源和存储引擎。
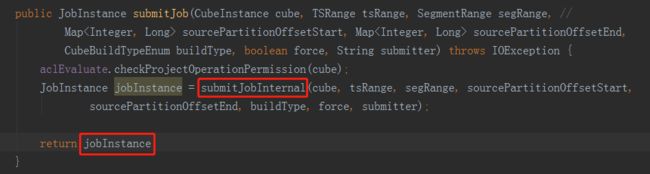
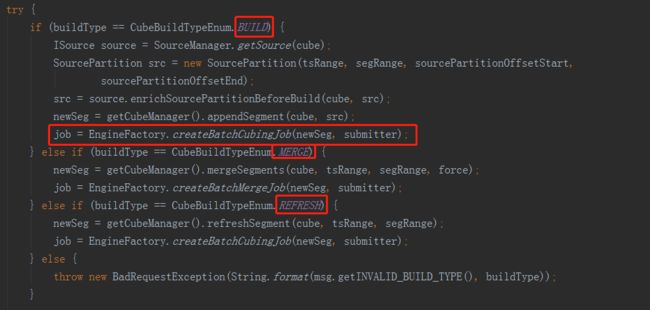
在网页上向Kylin服务端发送构建新的CubeSegment的请求后,通过controller层来到service层,进入JobService类中的submitJob方法,方法内部再调用submitJobInternal方法,在build、merge和refresh的时候,通过
EngineFactory.
createBatchCubingJob
(newSeg
,
submitter)
返回一个job实例,从这里可以看出,CubingJob的构建入口是由计算引擎提供的,即默认的计算引擎MRBatchCubingEngine2。

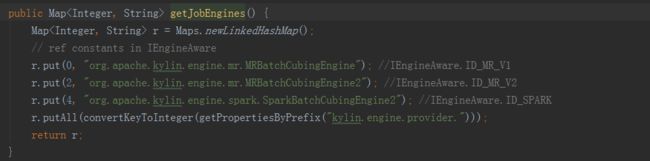
Kylin所支持的所有计算引擎,都会在EngineFactory中注册,并保存在batchEngine中,可以通过配置文件kylin.properties选择计算引擎,目前Kylin支持的计算引擎有:
MRBatchCubingEngine2实现了createBatchCubingJob方法,方法内调用了BatchCubingJobBuild2的build方法。

在new的初始化过程中,super(newSegment,submitter)就是执行父类的构造方法,进行了一些属性的初始化赋值,其中的inputSide和outputSide就上上文提到的数据源和存储引擎实例,通过计算引擎的协调来进行CubingJob的构建。

数据源inputSide实例获取:



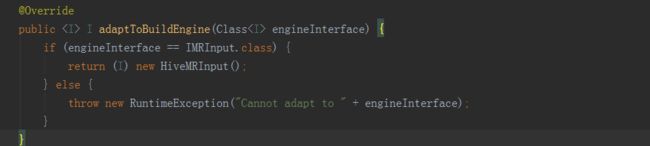
以上即为数据源实例获取过程的代码展现,BatchCubingJobBuilder2初始化的时候,调用MRUtil的getBatchCubingInputSide方法,它最终调用的其实还是MRBatchCubingEngine2这个计算引擎的getJoinedFlatTableDesc方法,它返回了一个IJoinedFlatTableDesc实例,这个对象就是对数据源表信息的封装。获得了这个flatDesc实例之后,就要来获取inputSide实例,与获取计算引擎代码类似,目前kylin中支持的数据源有:

Kylin默认的数据源是序号为0的HiveSource,所以最后调用的是HiveSource的adaptToBuildEngine,根据传入的IMRInput.class接口,最终返回得到HiveMRInput的实例,最后再通过它的getBatchCubingInputSide的方法获取inputSide的实例。
存储引擎outputSide实例获取:

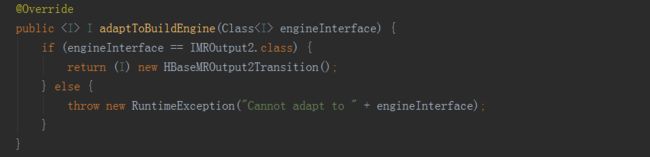

以上即为存储引擎实例获取的代码展现,BatchCubingJobBuilder2初始化的时候,调用MRUtil的getBatchCubingOutputSide方法,方法内先调用了StorageFactory类的createEngineAdapter方法,方法内又调用实现了Storage接口的HBaseStorage类的adaptToBuildEngine方法,最后返回了HBaseMROutput2Transition实例,然后在通过它的getBatchCubingOutputSide方法就可以获取到outputSide的实例。目前kylin中支持的数据源有:
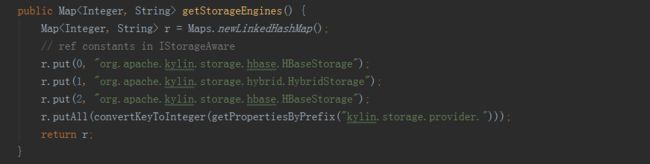
kylin默认的存储引擎是HBase。
——————————————————————————————————
通过构造函数,数据源、计算引擎和数据存储三个模块已经关联到一起了,上文介绍到的MRBatchCubingEngine2的方法中,在new出了一个BatchCubingJobBuild2实例后,接着就调用了build方法,最后返回了一个CubingJob实例。build方法逻辑如下:
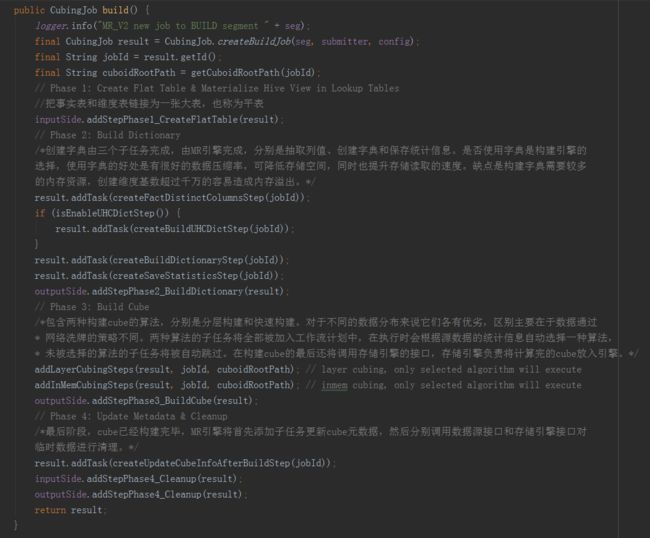
方法的内容就是构建一个CubeSegment的步骤,依次顺序的加入到CubingJob的任务list中。
从第一行开始,调用了CubingJob的createBuildJob方法,里面又调用了initCubingJob方法。

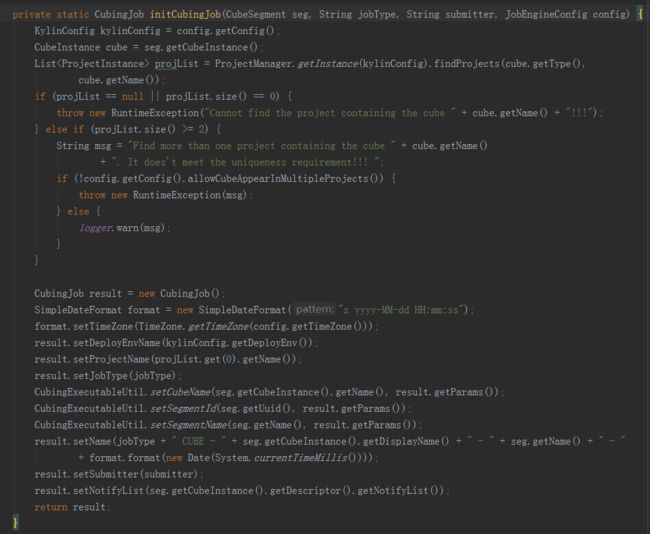
initCubingJob方法就是获取到cube相关的一些配置信息进行初始化,它是根据cube的名字去查询所在的project,如果不同的project下创建了相同名字的cube,那返回的就会是一个List,然后看配置文件中是否开启了允许cube重名,如不允许则直接抛出异常,如果允许就在设置projectName时取返回List中的第一个元素,那么这里就可能导致projectName设置错误,所以最好保证cube的name是全局唯一的。
在CubingJob初始化之后,会获取cuboidRootPath,获取逻辑如下:





经过一连串的调用拼装,最终获取的路径格式如下:
hdfs:///kylin/kylin_metadata/kylin-jobId/cubeName/cuboid
接下来就是三大引擎相互协作,构建CubeSegment的过程,整个过程大致分为创建hive平表、创建字典、构建Cube和更新元数据和清理这四个步骤。
第一步和第四步是由数据源来实现的,具体是在HiveMRInput类实现了IMRInput接口的getBatchCubingInputSide方法中,它返回了一个BatchCubingInputSide实例,在这个类中完成了具体工作;第二步是由计算引擎实现的,依靠JobBuilderSupport类中的方法完成;第三步是由计算引擎和存储引擎共同完成的,包括构建cube和存储到HBase;第四步是由数据源和存储引擎分别完成的;我们按步骤对代码进行分析。
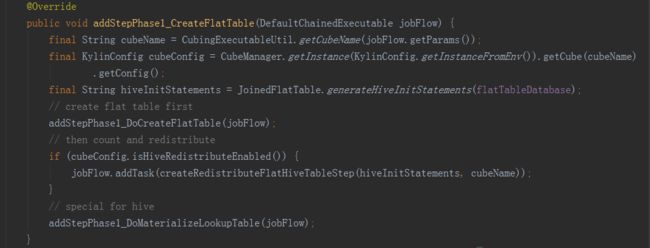
首先是第一步创建hive平表调用了HiveMRInput类中的静态内部类BatchCubingInputSide中的addStepPhase1_CreateFlatTable方法。

先获取cubeName、cubeConfig、hive命令(USE faltTableDatabase)三个变量。

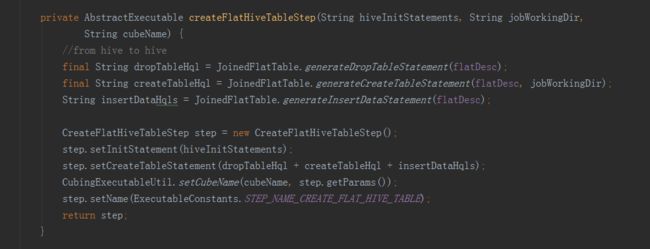

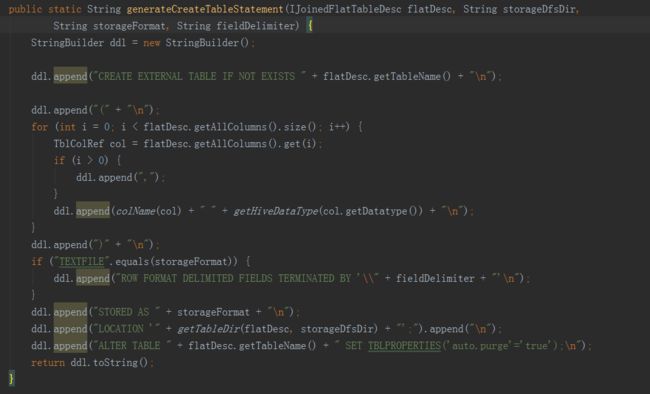
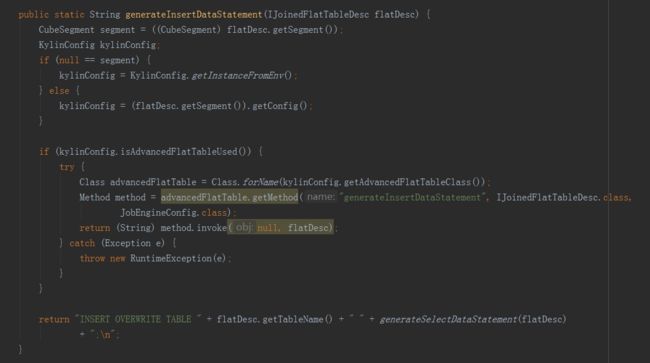
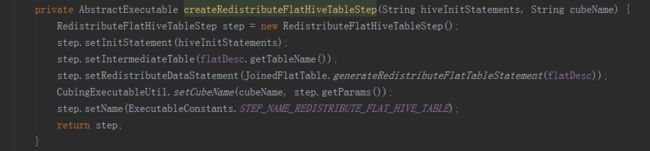
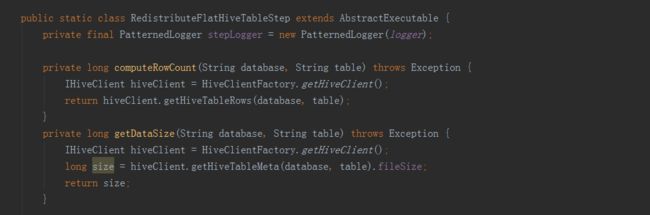
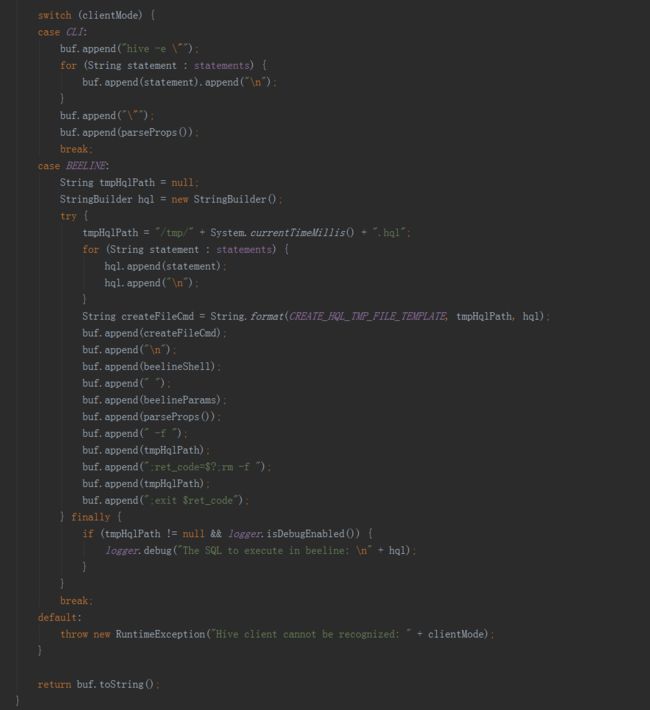
接下来的方法就是抽取变量,进行hive命令的拼接,完成以下步骤:
一是从hive表中,将所需字段从事实表和维表中提取出来,构建一个宽表;
二是将上一步得到的宽表,按照某个字段进行重新分配,如果没有指定字段,则随机,目的是产生多个差不多大小的文件,作为后续构建任务的输入,防止数据倾斜。
三是将hive中的视图物化。
——————————————————————————————————
创建平表命令例子:
hive -e "USE default;
DROP TABLE IF EXISTS kylin_intermediate_taconfirm_kylin_15all_ddacfb18_3d2e_4e1b_8975_f0871183418d;
CREATE EXTERNAL TABLE IF NOT EXISTS kylin_intermediate_taconfirm_kylin_15all_ddacfb18_3d2e_4e1b_8975_f0871183418d
(
TACONFIRM_BUSINESSCODE string
,TACONFIRM_FUNDCODE string
,TACONFIRM_SHARETYPE string
,TACONFIRM_NETCODE string
,TACONFIRM_CURRENCYTYPE string
,TACONFIRM_CODEOFTARGETFUND string
,TACONFIRM_TARGETSHARETYPE string
,TACONFIRM_TARGETBRANCHCODE string
,TACONFIRM_RETURNCODE string
,TACONFIRM_DEFDIVIDENDMETHOD string
,TACONFIRM_FROZENCAUSE string
,TACONFIRM_TAINTERNALCODE string
,TACONFIRM_C_PROVICE string
,TAPROVINCE_PROVINCENAME string
,TASHARETYPE_SHARETYPENAME string
)
STORED AS SEQUENCEFILE
LOCATION 'hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-4c5d4bb4-791f-4ec3-b3d7-89780adc3f58/kylin_intermediate_taconfirm_kylin_15all_ddacfb18_3d2e_4e1b_8975_f0871183418d';
ALTER TABLE kylin_intermediate_taconfirm_kylin_15all_ddacfb18_3d2e_4e1b_8975_f0871183418d SET TBLPROPERTIES('auto.purge'='true');
INSERT OVERWRITE TABLE kylin_intermediate_taconfirm_kylin_15all_ddacfb18_3d2e_4e1b_8975_f0871183418d SELECT
TACONFIRM.BUSINESSCODE as TACONFIRM_BUSINESSCODE
,TACONFIRM.FUNDCODE as TACONFIRM_FUNDCODE
,TACONFIRM.SHARETYPE as TACONFIRM_SHARETYPE
,TACONFIRM.NETCODE as TACONFIRM_NETCODE
,TACONFIRM.CURRENCYTYPE as TACONFIRM_CURRENCYTYPE
,TACONFIRM.CODEOFTARGETFUND as TACONFIRM_CODEOFTARGETFUND
,TACONFIRM.TARGETSHARETYPE as TACONFIRM_TARGETSHARETYPE
,TACONFIRM.TARGETBRANCHCODE as TACONFIRM_TARGETBRANCHCODE
,TACONFIRM.RETURNCODE as TACONFIRM_RETURNCODE
,TACONFIRM.DEFDIVIDENDMETHOD as TACONFIRM_DEFDIVIDENDMETHOD
,TACONFIRM.FROZENCAUSE as TACONFIRM_FROZENCAUSE
,TACONFIRM.TAINTERNALCODE as TACONFIRM_TAINTERNALCODE
,TACONFIRM.C_PROVICE as TACONFIRM_C_PROVICE
,TAPROVINCE.PROVINCENAME as TAPROVINCE_PROVINCENAME
,TASHARETYPE.SHARETYPENAME as TASHARETYPE_SHARETYPENAME
FROM DEFAULT.TACONFIRM as TACONFIRM
INNER JOIN DEFAULT.TAPROVINCE as TAPROVINCE
ON TACONFIRM.C_PROVICE = TAPROVINCE.C_PROVICE
INNER JOIN DEFAULT.TASHARETYPE as TASHARETYPE
ON TACONFIRM.SHARETYPE = TASHARETYPE.SHARETYPE
WHERE 1=1;
" --hiveconf hive.merge.mapredfiles=false --hiveconf hive.auto.convert.join=true --hiveconf dfs.replication=2 --hiveconf hive.exec.compress.output=true --hiveconf hive.auto.convert.join.noconditionaltask=true --hiveconf mapreduce.job.split.metainfo.maxsize=-1 --hiveconf hive.merge.mapfiles=false --hiveconf hive.auto.convert.join.noconditionaltask.size=100000000 --hiveconf hive.stats.autogather=true
——————————————————————————————————
文件再分配和视图物化命令例子:
hive -e "USE default;
set mapreduce.job.reduces=3;
set hive.merge.mapredfiles=false;
INSERT OVERWRITE TABLE kylin_intermediate_taconfirm_kylin_15all_ddacfb18_3d2e_4e1b_8975_f0871183418d SELECT * FROM kylin_intermediate_taconfirm_kylin_15all_ddacfb18_3d2e_4e1b_8975_f0871183418d DISTRIBUTE BY RAND();
" --hiveconf hive.merge.mapredfiles=false --hiveconf hive.auto.convert.join=true --hiveconf dfs.replication=2 --hiveconf hive.exec.compress.output=true --hiveconf hive.auto.convert.join.noconditionaltask=true --hiveconf mapreduce.job.split.metainfo.maxsize=-1 --hiveconf hive.merge.mapfiles=false --hiveconf hive.auto.convert.join.noconditionaltask.size=100000000 --hiveconf hive.stats.autogather=true
——————————————————————————————————
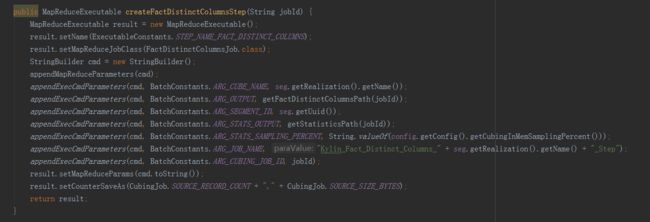
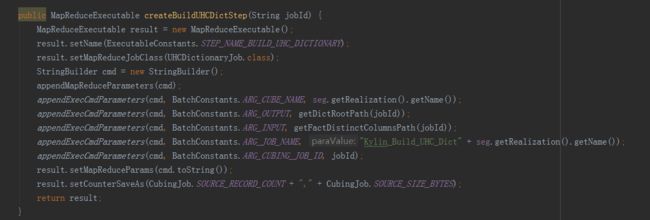

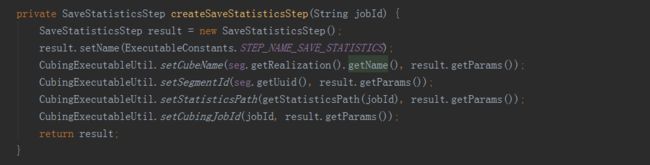
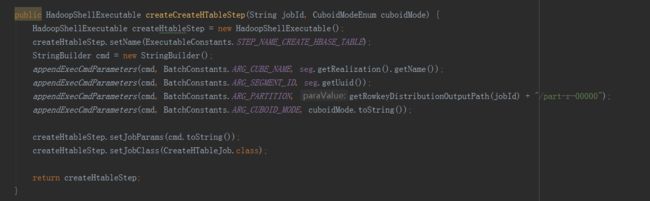
创建字典由三个子任务完成,分别是抽取列值、创建字典和保存统计信息,由MR引擎完成,所以直接在build方法中add到任务list中。是否使用字典是构建引擎的选择,使用字典的好处是有很好的数据压缩率,可降低存储空间,同时也提升存储读取的速度。缺点是构建字典需要较多的内存资源,创建维度基数超过千万的容易造成内存溢出。在这个过程最后,还要创建HTable,这属于存储引擎的任务,所以是在HBaseMROutput2Transition实例中完成的。
——————————————————————————————————
抽取列值步骤参数例子:
-conf /usr/local/apps/apache-kylin-2.3.1-bin/conf/kylin_job_conf.xml -cubename Taconfirm_kylin_15all -output hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-4c5d4bb4-791f-4ec3-b3d7-89780adc3f58/Taconfirm_kylin_15all/fact_distinct_columns -segmentid ddacfb18-3d2e-4e1b-8975-f0871183418d -statisticsoutput hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-4c5d4bb4-791f-4ec3-b3d7-89780adc3f58/Taconfirm_kylin_15all/fact_distinct_columns/statistics -statisticssamplingpercent 100 -jobname Kylin_Fact_Distinct_Columns_Taconfirm_kylin_15all_Step -cubingJobId 4c5d4bb4-791f-4ec3-b3d7-89780adc3f58
——————————————————————————————————
构建维度字典步骤参数例子 :
-cubename Taconfirm_kylin_15all -segmentid ddacfb18-3d2e-4e1b-8975-f0871183418d -input hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-4c5d4bb4-791f-4ec3-b3d7-89780adc3f58/Taconfirm_kylin_15all/fact_distinct_columns -dictPath hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-4c5d4bb4-791f-4ec3-b3d7-89780adc3f58/Taconfirm_kylin_15all/dict
——————————————————————————————————
创建HTable步骤参数例子:
-cubename Taconfirm_kylin_15all -segmentid ddacfb18-3d2e-4e1b-8975-f0871183418d -partitions hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-4c5d4bb4-791f-4ec3-b3d7-89780adc3f58/Taconfirm_kylin_15all/rowkey_stats/part-r-00000 -cuboidMode CURRENT
——————————————————————————————————

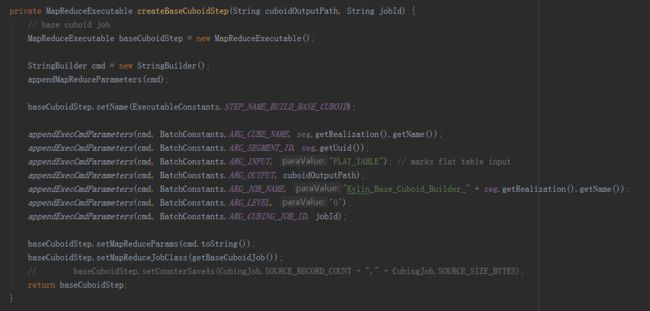
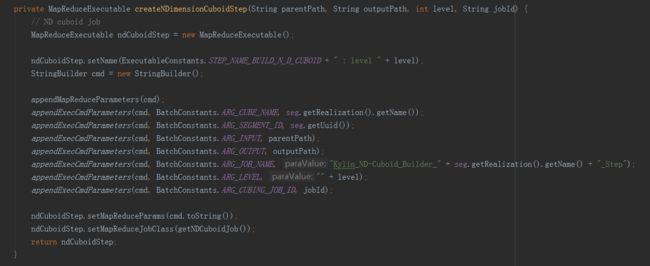


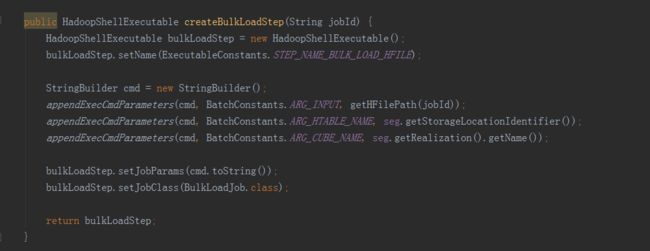
构建Cube属于计算引擎的任务,就是根据准备好的数据,依次产生cuboid的数据,在这里调用了两种构建方法,分别是分层构建和快速构建,但最终只会选择一种构建方法,分层构建首先调用createBaseCuboidStep方法,生成Base Cuboid数据文件,然后进入for循环,调用createNDimensionCuboidStep方法,根据Base Cuboid计算N层Cuboid数据。
在Cuboid的数据都产生好之后,还需要放到存储层中,所以接下来调用outputSide实例的addStepPhase3_BuildCube方法,HBaseMROutput2Transition类中的addStepPhase3_BuildCube方法主要有两步,一是createConvertCuboidToHfileStep方法,将计算引擎产生的cuboid数据转换成HBase要求的HFile格式,二是createBulkLoadStep方法,即把HFIle数据加载到HBase中。
——————————————————————————————————
构建Base Cuboid步骤参数例子:
-conf /usr/local/apps/kylin/conf/kylin_job_conf.xml -cubename kylin_sales_cube -segmentid 392634bd-4964-428c-a905-9bbf28884452 -input FLAT_TABLE -output hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-6f3c2a9e-7283-4d87-9487-a5ebaffef811/kylin_sales_cube/cuboid/level_base_cuboid -jobname Kylin_Base_Cuboid_Builder_kylin_sales_cube -level 0 -cubingJobId 6f3c2a9e-7283-4d87-9487-a5ebaffef811
——————————————————————————————————
构建N层Cuboid步骤参数例子:
-conf /usr/local/apps/kylin/conf/kylin_job_conf.xml -cubename kylin_sales_cube -segmentid 392634bd-4964-428c-a905-9bbf28884452 -input hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-6f3c2a9e-7283-4d87-9487-a5ebaffef811/kylin_sales_cube/cuboid/level_1_cuboid -output hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-6f3c2a9e-7283-4d87-9487-a5ebaffef811/kylin_sales_cube/cuboid/level_2_cuboid -jobname Kylin_ND-Cuboid_Builder_kylin_sales_cube_Step -level 2 -cubingJobId 6f3c2a9e-7283-4d87-9487-a5ebaffef811
——————————————————————————————————
转换HFile格式步骤参数例子:
-conf /usr/local/apps/kylin/conf/kylin_job_conf.xml -cubename kylin_sales_cube -partitions hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-6f3c2a9e-7283-4d87-9487-a5ebaffef811/kylin_sales_cube/rowkey_stats/part-r-00000_hfile -input hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-6f3c2a9e-7283-4d87-9487-a5ebaffef811/kylin_sales_cube/cuboid/* -output hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-6f3c2a9e-7283-4d87-9487-a5ebaffef811/kylin_sales_cube/hfile -htablename KYLIN_O2SYZPV449 -jobname Kylin_HFile_Generator_kylin_sales_cube_Step
——————————————————————————————————
加载HFile到HBase步骤参数例子:
-input hdfs://qtbj-sj-cdh-name:8020/kylin/kylin_metadata/kylin-6f3c2a9e-7283-4d87-9487-a5ebaffef811/kylin_sales_cube/hfile -htablename KYLIN_O2SYZPV449 -cubename kylin_sales_cube
——————————————————————————————————
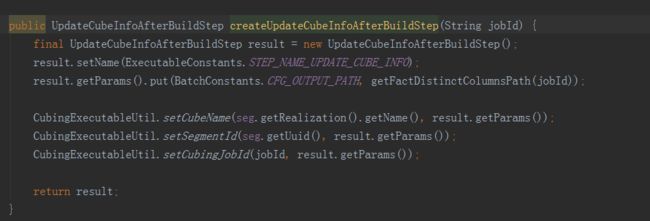
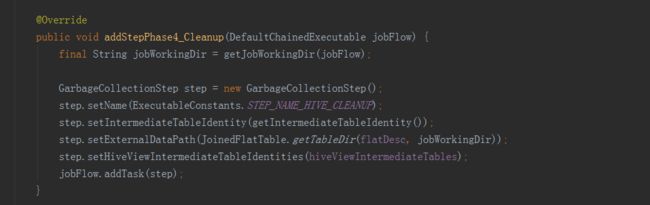

最后一步就是一些收尾工作,包括更新Cube元数据信息,调用inputSide和outputSide实例进行中间临时数据的清理工作。
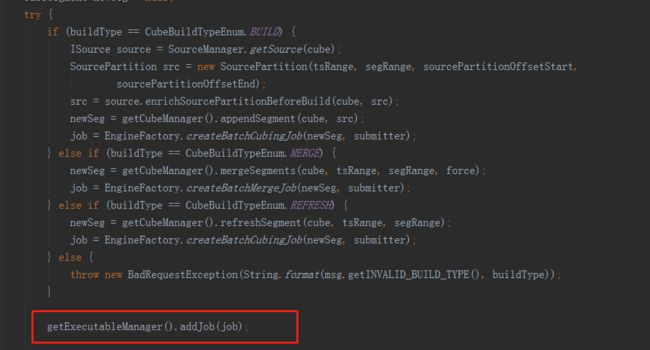
完成所有步骤之后,就回到了JobService的submitJob方法中,在得到CubingJob的实例后,会执行以上代码。这里做的是将CubingJob的信息物化到HBase的kylin_metadata表中,并没有真正的提交执行。
真正执行CubingJob的地方是在DefaultScheduler,它里面有一个线程会每隔一分钟,就去HBase的kylin_metadata表中扫一遍所有的CubingJob,然后将需要执行的job,提交到线程池执行。
kylin中任务的构建和执行是异步的。单个kylin节点有query、job和all三种角色,query只提供查询服务,job只提供真正的构建服务,all则兼具前两者功能。实际操作中kylin的三种角色节点都可以进行CubingJob的构建,但只有all和job模式的节点可以通过DefaultScheduler进行调度执行。
相关博客:https://blog.csdn.net/qq_21653785/article/details/73611423