机器学习笔记(十七):TensorFlow实战九(经典卷积神经网络:ResNet)
1 - 引言
我们可以看到CNN经典模型的发展从
LeNet -5、AlexNet、VGG、再到Inception,模型的层数和复杂程度都有着明显的提高,有些网络层数更是达到100多层。但是当神经网络的层数过高时,这些神经网络会变得更加难以训练。
一个特别大的麻烦就在于训练的时候会产生梯度消失,非常深的网络通常会有一个梯度信号,该信号会迅速的消退,从而使得梯度下降变得非常缓慢。更具体的说,在梯度下降的过程中,当你从最后一层回到第一层的时候,你在每个步骤上乘以权重矩阵,因此梯度值可以迅速的指数式地减少到0(在极少数的情况下会迅速增长,造成梯度爆炸)。
在训练的过程中,你可能会看到开始几层的梯度的大小(或范数)迅速下降到0,如下图:
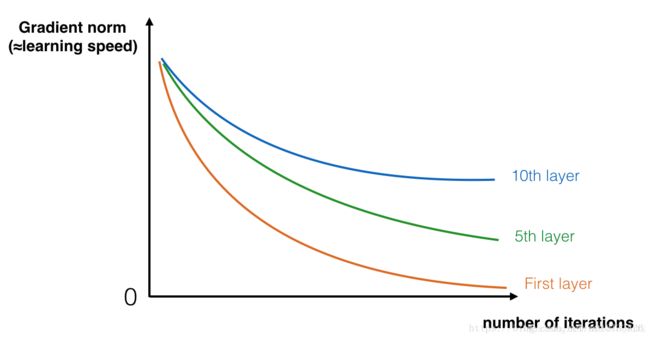
甚至训练误差比那些层数少的模型更大。
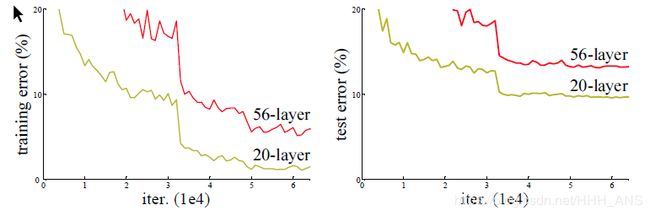
因此,所以为了解决这个问题,ResNet脱颖而出。
ResNet(Residual Neural Network)由微软研究院的Kaiming He等四名华人提出,通过使用ResNet Unit成功训练出了152层的神经网络,并在ILSVRC2015比赛中取得冠军,在top5上的错误率为3.57%,同时参数量比VGGNet低,效果非常突出。ResNet的结构可以极快的加速神经网络的训练,模型的准确率也有比较大的提升。同时ResNet的推广性非常好,甚至可以直接用到InceptionNet网络中。
下面我们就来详细的介绍一下ResNet网络
2 - ResNet网络结构
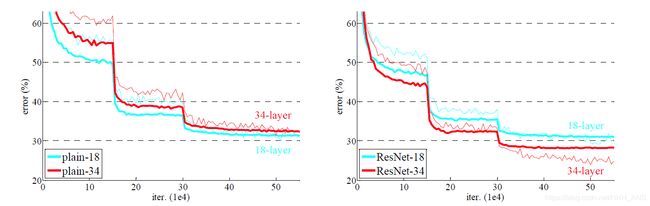
在残差网络中,一个“捷径(shortcut)”或者说“跳跃连接(skip connection)”允许梯度直接反向传播到更浅的层,如下图:

图像左边是神经网络的主路,图像右边是添加了一条捷径的主路,通过这些残差块堆叠在一起,可以形成一个非常深的网络。
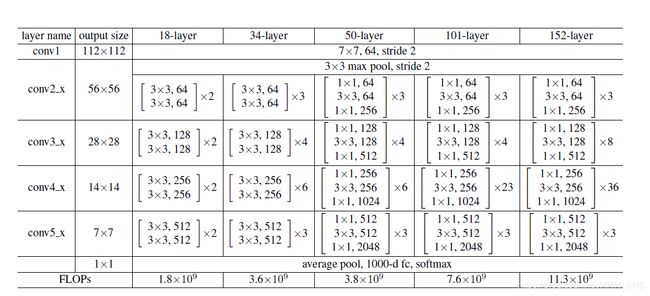
残差网络的结构非常简单,就是不断的通过一组一组的残差组链接,这是一个Resnet50的结构图,不同的网络结构在不同的组之间会有不同数目的残差模块,如下图:
2.1 - 恒等块
恒等块是残差网络使用的的标准块,对应于输入的激活值(比如 a [ l ] a^{[l]} a[l])与输出激活值(比如 a [ l + 1 ] a^{[l+1]} a[l+1])具有相同的维度。为了具象化残差块的不同步骤,我们来看看下面的图吧~
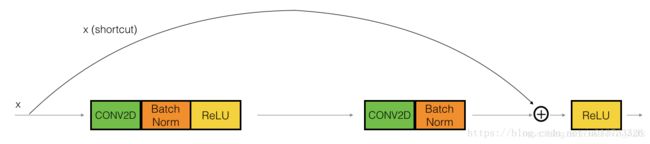
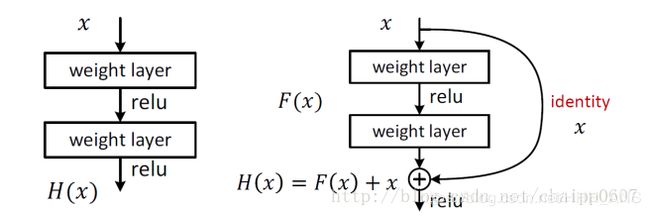
左侧为正常了两个卷积层,而右侧在两个卷积层前后做了直连,这个直连解释残差,左侧的输出为H(x)=F(x),而加入直连后的H(x)=F(x)+x,一个很简单的改进,但是取得了非常优异的效果。
至于为什么直连要跨越两个卷积层,而不是一个?这个是实验验证的结果,在一个卷积层上加直连性能并没有太大提升。
恒等快代码实现:
def _building_block_v1(inputs, filters, training, projection_shortcut, strides,
data_format):
"""A single block for ResNet v1, without a bottleneck.
Convolution then batch normalization then ReLU as described by:
Deep Residual Learning for Image Recognition
https://arxiv.org/pdf/1512.03385.pdf
by Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, Dec 2015.
Args:
inputs: A tensor of size [batch, channels, height_in, width_in] or
[batch, height_in, width_in, channels] depending on data_format.
filters: The number of filters for the convolutions.
training: A Boolean for whether the model is in training or inference
mode. Needed for batch normalization.
projection_shortcut: The function to use for projection shortcuts
(typically a 1x1 convolution when downsampling the input).
strides: The block's stride. If greater than 1, this block will ultimately
downsample the input.
data_format: The input format ('channels_last' or 'channels_first').
Returns:
The output tensor of the block; shape should match inputs.
"""
shortcut = inputs
if projection_shortcut is not None:
shortcut = projection_shortcut(inputs)
shortcut = batch_norm(inputs=shortcut, training=training,
data_format=data_format)
inputs = conv2d_fixed_padding(
inputs=inputs, filters=filters, kernel_size=3, strides=strides,
data_format=data_format)
inputs = batch_norm(inputs, training, data_format)
inputs = tf.nn.relu(inputs)
inputs = conv2d_fixed_padding(
inputs=inputs, filters=filters, kernel_size=3, strides=1,
data_format=data_format)
inputs = batch_norm(inputs, training, data_format)
inputs += shortcut
inputs = tf.nn.relu(inputs)
return inputs
2.1 - 卷积块
现在,残差网络的卷积块是另一种类型的残差块,它适用于输入输出的维度不一致的情况,它不同于上面的恒等块,与之区别在于,捷径中有一个CONV2D层,如下图:
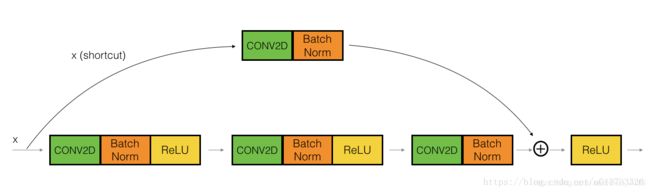
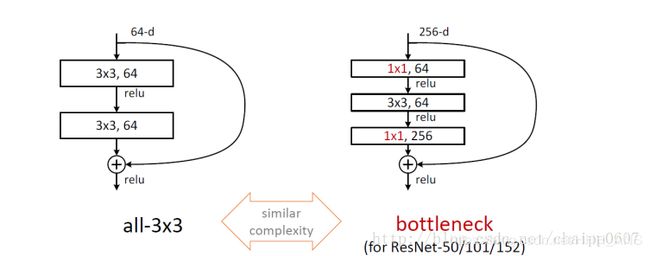
上面这样图能够说明二者的区别,左侧的通道数是64(它常出现在50层内的残差结构中),右侧的通道数是256(常出现在50层以上的残差结构中),从右面的图可以看到,bottleneck残差模块将两个33换成了11,33,11的形式,第一个11用来降通道,33用来在降通道的特征上卷积,第二个11用于升通道。而参数的减少就是因为在第一个11将通道数降了下来。我们可以举一个例子验证一下:
假设朴素残差模块与bottleneck残差模块通道数都是256,那么:
朴素残差模块的参数个数:
3 ∗ 3 ∗ 256 ∗ 256 + 3 ∗ 3 ∗ 256 ∗ 256 = 10616832 3*3*256*256+3*3*256*256 = 10616832 3∗3∗256∗256+3∗3∗256∗256=10616832
bottleneck残差模块的参数个数:
1 ∗ 1 ∗ 256 ∗ 64 + 3 ∗ 3 ∗ 64 ∗ 64 + 1 ∗ 1 ∗ 64 ∗ 256 = 69632 1*1*256*64+3*3*64*64+1*1*64*256 = 69632 1∗1∗256∗64+3∗3∗64∗64+1∗1∗64∗256=69632
def _bottleneck_block_v1(inputs, filters, training, projection_shortcut,
strides, data_format):
"""A single block for ResNet v1, with a bottleneck.
Similar to _building_block_v1(), except using the "bottleneck" blocks
described in:
Convolution then batch normalization then ReLU as described by:
Deep Residual Learning for Image Recognition
https://arxiv.org/pdf/1512.03385.pdf
by Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, Dec 2015.
Args:
inputs: A tensor of size [batch, channels, height_in, width_in] or
[batch, height_in, width_in, channels] depending on data_format.
filters: The number of filters for the convolutions.
training: A Boolean for whether the model is in training or inference
mode. Needed for batch normalization.
projection_shortcut: The function to use for projection shortcuts
(typically a 1x1 convolution when downsampling the input).
strides: The block's stride. If greater than 1, this block will ultimately
downsample the input.
data_format: The input format ('channels_last' or 'channels_first').
Returns:
The output tensor of the block; shape should match inputs.
"""
shortcut = inputs
if projection_shortcut is not None:
shortcut = projection_shortcut(inputs)
shortcut = batch_norm(inputs=shortcut, training=training,
data_format=data_format)
inputs = conv2d_fixed_padding(
inputs=inputs, filters=filters, kernel_size=1, strides=1,
data_format=data_format)
inputs = batch_norm(inputs, training, data_format)
inputs = tf.nn.relu(inputs)
inputs = conv2d_fixed_padding(
inputs=inputs, filters=filters, kernel_size=3, strides=strides,
data_format=data_format)
inputs = batch_norm(inputs, training, data_format)
inputs = tf.nn.relu(inputs)
inputs = conv2d_fixed_padding(
inputs=inputs, filters=4 * filters, kernel_size=1, strides=1,
data_format=data_format)
inputs = batch_norm(inputs, training, data_format)
inputs += shortcut
inputs = tf.nn.relu(inputs)
return inputs