VGG_face Caffe 微调(finetuing)详细教程(二)
引言
接着上篇文章,我们了解了如何在vgg_face模型的基础上进行微调。接下来我将介绍如何使用微调好的模型识别人脸。
一.deploy配置文件
在使用模型之前还需要一个deploy.prototxt,该文件保存的是神经网络的结构,和train_test.prototxt有什么不同?train_test.prototxt是训练时用的网络结构,deploy.prototxt是生产环境所用的网络结构,两个网络的头和尾有些不同,中间结构是相同的。
创建一个deploy.prototxt文件,可直接copy下面代码:
name: "VGG_FACE_16_Net"
input: "data"
input_dim: 1
input_dim: 3
input_dim: 224
input_dim: 224
force_backward: true
layer {
name: "conv1_1"
type: "Convolution"
bottom: "data"
top: "conv1_1"
convolution_param {
num_output: 64
kernel_size: 3
pad: 1
}
}
layer {
name: "relu1_1"
type: "ReLU"
bottom: "conv1_1"
top: "conv1_1"
}
layer {
name: "conv1_2"
type: "Convolution"
bottom: "conv1_1"
top: "conv1_2"
convolution_param {
num_output: 64
kernel_size: 3
pad: 1
}
}
layer {
name: "relu1_2"
type: "ReLU"
bottom: "conv1_2"
top: "conv1_2"
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1_2"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2_1"
type: "Convolution"
bottom: "pool1"
top: "conv2_1"
convolution_param {
num_output: 128
kernel_size: 3
pad: 1
}
}
layer {
name: "relu2_1"
type: "ReLU"
bottom: "conv2_1"
top: "conv2_1"
}
layer {
name: "conv2_2"
type: "Convolution"
bottom: "conv2_1"
top: "conv2_2"
convolution_param {
num_output: 128
kernel_size: 3
pad: 1
}
}
layer {
name: "relu2_2"
type: "ReLU"
bottom: "conv2_2"
top: "conv2_2"
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2_2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv3_1"
type: "Convolution"
bottom: "pool2"
top: "conv3_1"
convolution_param {
num_output: 256
kernel_size: 3
pad: 1
}
}
layer {
name: "relu3_1"
type: "ReLU"
bottom: "conv3_1"
top: "conv3_1"
}
layer {
name: "conv3_2"
type: "Convolution"
bottom: "conv3_1"
top: "conv3_2"
convolution_param {
num_output: 256
kernel_size: 3
pad: 1
}
}
layer {
name: "relu3_2"
type: "ReLU"
bottom: "conv3_2"
top: "conv3_2"
}
layer {
name: "conv3_3"
type: "Convolution"
bottom: "conv3_2"
top: "conv3_3"
convolution_param {
num_output: 256
kernel_size: 3
pad: 1
}
}
layer {
name: "relu3_3"
type: "ReLU"
bottom: "conv3_3"
top: "conv3_3"
}
layer {
name: "pool3"
type: "Pooling"
bottom: "conv3_3"
top: "pool3"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv4_1"
type: "Convolution"
bottom: "pool3"
top: "conv4_1"
convolution_param {
num_output: 512
kernel_size: 3
pad: 1
}
}
layer {
name: "relu4_1"
type: "ReLU"
bottom: "conv4_1"
top: "conv4_1"
}
layer {
name: "conv4_2"
type: "Convolution"
bottom: "conv4_1"
top: "conv4_2"
convolution_param {
num_output: 512
kernel_size: 3
pad: 1
}
}
layer {
name: "relu4_2"
type: "ReLU"
bottom: "conv4_2"
top: "conv4_2"
}
layer {
name: "conv4_3"
type: "Convolution"
bottom: "conv4_2"
top: "conv4_3"
convolution_param {
num_output: 512
kernel_size: 3
pad: 1
}
}
layer {
name: "relu4_3"
type: "ReLU"
bottom: "conv4_3"
top: "conv4_3"
}
layer {
name: "pool4"
type: "Pooling"
bottom: "conv4_3"
top: "pool4"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv5_1"
type: "Convolution"
bottom: "pool4"
top: "conv5_1"
convolution_param {
num_output: 512
kernel_size: 3
pad: 1
}
}
layer {
name: "relu5_1"
type: "ReLU"
bottom: "conv5_1"
top: "conv5_1"
}
layer {
name: "conv5_2"
type: "Convolution"
bottom: "conv5_1"
top: "conv5_2"
convolution_param {
num_output: 512
kernel_size: 3
pad: 1
}
}
layer {
name: "relu5_2"
type: "ReLU"
bottom: "conv5_2"
top: "conv5_2"
}
layer {
name: "conv5_3"
type: "Convolution"
bottom: "conv5_2"
top: "conv5_3"
convolution_param {
num_output: 512
kernel_size: 3
pad: 1
}
}
layer {
name: "relu5_3"
type: "ReLU"
bottom: "conv5_3"
top: "conv5_3"
}
layer {
name: "pool5"
type: "Pooling"
bottom: "conv5_3"
top: "pool5"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "fc6"
type: "InnerProduct"
bottom: "pool5"
top: "fc6"
inner_product_param {
num_output: 4096
}
}
layer {
name: "relu6"
type: "ReLU"
bottom: "fc6"
top: "fc6"
}
layer {
name: "drop6"
type: "Dropout"
bottom: "fc6"
top: "fc6"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc7"
type: "InnerProduct"
bottom: "fc6"
top: "fc7"
# Note that lr_mult can be set to 0 to disable any fine-tuning of this, and any other, layer
inner_product_param {
num_output: 4096
}
}
layer {
name: "relu7"
type: "ReLU"
bottom: "fc7"
top: "fc7"
}
layer {
name: "drop7"
type: "Dropout"
bottom: "fc7"
top: "fc7"
dropout_param {
dropout_ratio: 0.5
}
}
layer {
name: "fc8_flickr"
type: "InnerProduct"
bottom: "fc7"
top: "fc8_flickr"
# lr_mult is set to higher than for other layers, because this layer is starting from random while the others are already trained
propagate_down: false
inner_product_param {
num_output: 200 # 改,有多少类别就改为多少,根据上篇文章,这里改为40
}
}
layer {
name: "prob"
type: "Softmax"
bottom: "fc8_flickr"
top: "prob"
}
二.python脚本使用模型
不多说,直接上代码:
import caffe
deployFile = '/home/pzs/husin/caffePython/husin_download/VGG_face/deploy.prototxt'
modelFile = '/home/pzs/husin/caffePython/husin_download/VGG_face/snapshot/solver_iter_1000.caffemodel'
imgPath = '/home/pzs/husin/caffePython/husin_download/VGG_face/val/40-5m.jpg' # 这里我选择的人脸是40-5m.jpg,读者可以任意选择
def predictImg(net,imgPath):
# 得到data的形状,这里的图片是默认matplotlib底层加载的
# matplotlib加载的image是像素[0-1],图片的数据格式[weight,high,channels],RGB
# caffe加载的图片需要的是[0-255]像素,数据格式[channels,weight,high],BGR,那么就需要转换
transformer = caffe.io.Transformer({'data':net.blobs['data'].data.shape})
transformer.set_transpose('data',(2,0,1)) # 改成[channels,weight,high]
transformer.set_raw_scale('data',255) # 像素区间扩展为[0,255]
transformer.set_channel_swap('data',(2,1,0)) # RGB
im = caffe.io.load_image(imgPath) # 加载图片
net.blobs['data'].data[...] = transformer.preprocess('data',im) # 用上面的transformer.preprocess来处理刚刚加载图片
output = net.forward() # 进行前向传播
output_prob = output['prob'][0] # 最终的结果: 当前这个图片的属于哪个物体的概率(列表表示)
print '---------------------------------------------------------------------------------------------------------------------'
print str(output_prob.argmax()) # 输出概率最大的标签
if __name__=='__main__':
net = caffe.Net(deployFile,modelFile,caffe.TEST)
predictImg(net,imgPath)
三 . 运行结果
这里我检测的是val/40-5m.jpg, 所属类应该是39(因为从0开始), 下面是输出结果:
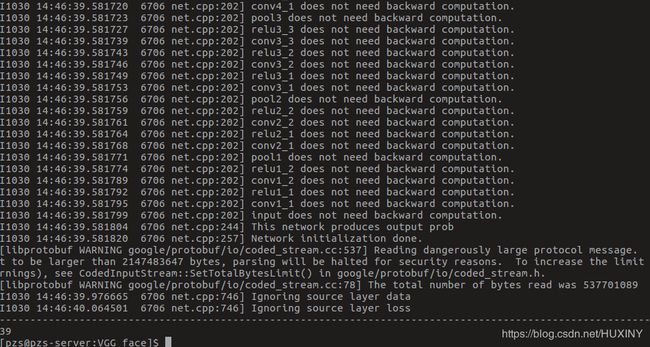
可以看到,检测很准确,读者可以试试其他的人脸,我这里试过,都是准确的。
结束语
该文章是本人对caffe学习的阶段总结,有错误之处还请大家指出,以共同学习。
And let us not be weary in well-doing, for in due season, we shall reap, if we faint not