Elasticsearch进阶(一)写入性能基准测试写入性能优化(56小时到5小时),chunk_size探讨
进入正题之前,解决之前的一个疑问:Elasticsearch集群是否已经正确工作?
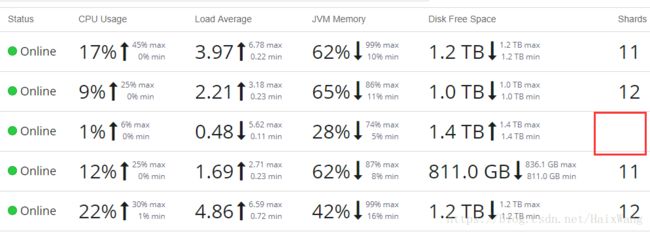
截图时,只上传过一次小测试数据(143万条),设置为:
"number_of_shards": 5,
"number_of_replicas": 2
- 从图中可以看出,ip10节点上设置的数据目录:data1和data2目录工作正常,但是数据相同
- ip12中数据与ip10中数据不同,但是data1与data2数据相同
- ip13数据与ip12相同
- ip11既不是master候选者,也不是data节点,验证发现确实无数据
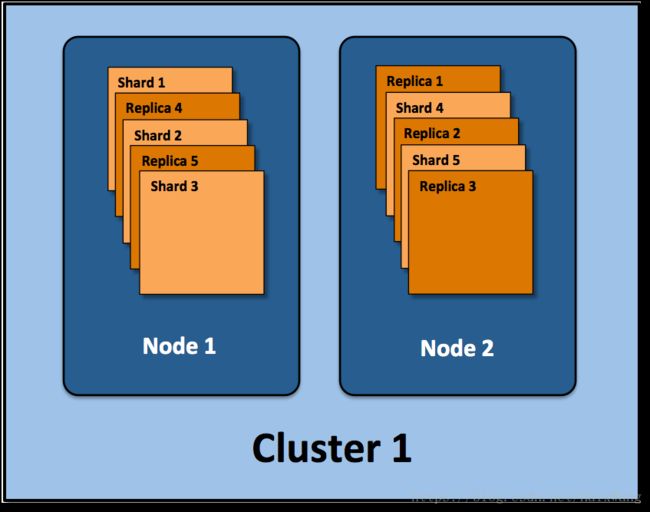
分配多个分片和副本是分布式搜索功能设计的精髓
测试环境
系统:macOS 10.13.4
处理器:2.3Ghz Inter Core i5
内存:8 GB 2133 MHz LPDDR3
SSDs
注:jamesjxin在博客中说到:
确保性能测试持续30分钟以上以确认长时间的性能;短时间的测试可能不会碰到segment合并和GC,无法确认这些因素的影响
因时间有限,我就不那样测了。
PS:但是我的测试集确实太小了些,象征性的思路、过程走一波吧。
优化缘由
近1T(约5亿)数据需上传elasticsearch集群,但是第一次的测序跑了会后,预估大概需要跑56小时
[
单机器上传:
centos 6.9
Intel(R) Xeon(R) CPU E5-2620 v2 @ 2.10GHz
48G内存
]
用十万条数据做基准测试
1.索引 diglab_1:
"number_of_shards": 5,
"number_of_replicas": 2用时33秒

副本103.5mb, 存储共用2*副本+103.5mb
2.索引 diglab_2:
采用默认设置,也就是
"number_of_shards": 5,
"number_of_replicas": 1用时29秒, 没什么显著变化,较上提升12%
3.索引 diglab_3:
【副本数进一步设置为1】
"number_of_shards": 5,
"number_of_replicas": 0用时23秒,较上提升20%
【猜测:传输速度远小于复制速度】
4.查看分片数过大会不会影响上传速度 diglab_4
"number_of_shards": 15,
"number_of_replicas": 0用时29秒
设置为8时,用时22秒
【会变慢一些,但是考虑到分片数对检索有一定影响,所以暂时决定以后的测试基于分片数设置为默认值5,副本数0】
分片数设置为默认值5的理由
5.增大bulk一次提交的量
chunk_size由 2000 => 8000
速度有提升,19秒
再次增大,到50000
19秒
由于差异确实细微,故以下测试数据集改为之前5次测试的三倍,并从第4次测试接着测试
测试集有两个文件,一个10万条数据,一个20万条数据
tail命令比head命令慢挺多
【关于chunk_size设置多大比较合适】
max_chunk_bytes – the maximum size of the request in bytes (default: 100MB)
max_chunk_bytes默认值为100mb,根据咱们自己的数据每条的大小,自己可以计算出范围。
比如我这里,10万条数据63mb,所以理论上我这chunk_size设置可以接近16万
但是当我设置为10万时:
elasticsearch.exceptions.ConnectionTimeout
原因未知
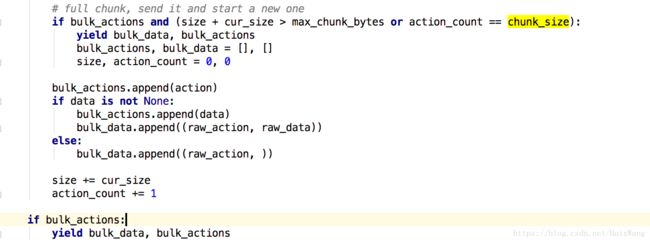
【chunk_size定义后,并不代表可以省略下方if】
if len(actions) == 90000:
suc, err = helpers.bulk(es, actions, chunk_size=90000, raise_on_error=False, stats_only=True)省略之后会是一条一条的提交到ES

【一个文件读取结束时,不==chunk_size时,一并提交】
源码截图如下:
6.chunk_size=16000
63秒
6.chunk_size=90000
77秒
看来trunk_size并不是越大越好
7.【我暂时按网速算吧(无理论 支撑),我这大概15mb/s】
chunk_size=24000
63秒
【我还测试了20000,10000,都差不多,还真应验了“参考2“所说的5-10mb】
到此,大致提升了33%
8.【增加刷新间隔】
默认值index.refresh_interval是1s,这会迫使Elasticsearch每隔一秒就创建一个新的分段。增加这个值(比如说30s)可以减少未来的合并压力。
设置为-1使用最大限度的刷新间隔
但是我这设置为-1
或者30s,都没有提升,也许是测试集小的原因?

注意:时间间隔调整后,使用“_count“也许不能及时获取到信息,即使你已经写入完毕
9.【禁止SWAP】
(注意,以下仅对Linux/Unix系统起作用)
【但我认为,在系统内存足够大的情况下,是没有什么帮助的】
- 在Linux系统上,可以运行以下命令临时禁用交换
swapoff -a

- elasticsearch.yml中
bootstrap.memory_lock: true
,
10.【使用自动生成的id】
索引具有显式ID的文档时,Elasticsearch需要检查具有相同ID的文档是否已经存在于相同的分片中,这是一项代价高昂的操作,并且随着索引增长而变得更加昂贵。通过使用自动生成的ID,Elasticsearch可以跳过此检查,这会使索引更快。

11.修改JVM参数
在JVM中,初始内存分配,是min(1/64系统内存,1G);最大值是min(1G,1/4系统内存)。
Elasticsearch默认安装后设置的内存是1GB最小堆大小(Xms)和最大堆大小(Xmx)都是1G。
在能预估程序使用的内存大小的情况下,建议Xmx和Xms的大小设置为该值(不需要频繁的垃圾回收),并且相同,设置为相同是JVM不需要进行内存扩展。
可以在jvm.options文件中修改
至此,实验了下,性能提升了1倍
12.多线程
TODO
13.多机器同时写入
将数据分发到各台机器,像集群写入数据(所以需要使用自动生成的ID)
至此,实验了下,性能提升了11倍。
因为数据量太大,中途报错:
elasticsearch.exceptions.ConnectionTimeout: ConnectionTimeout caused by - ReadTimeoutError
修改request_timeout参数:
helpers.bulk(es, actions, chunk_size=15000, request_timeout=60, raise_on_error=False, stats_only=True)elasticsearch 删除数据倒是真的快。
6.0之后配置的变化
- 6.0版本之后,只能使用elasticsearch.yml文件进行配置
- 布尔值只认可true和false
- 存储限制已被删除。indices.store.throttle.type和indices.store.throttle.max_bytes_per_sec不再使用。
network.tcp.blocking_server,network.tcp.blocking_client, network.tcp.blocking,transport.tcp.blocking_client,transport.tcp.blocking_server,和http.tcp.blocking_server设置不再使用。
网络方面
transport.netty.max_cumulation_buffer_capacity,
transport.netty.max_composite_buffer_components,
http.netty.max_cumulation_buffer_capacity已被删除。所有脚本安全被替换为使用script.allowed_types和script.allowed_contexts进行配置。
不再支持使用discovery.type设置值gce,aws和ec2。改为使用discovery.zen.hosts_provider设置。
参考
[1]Blog Optimizing Elasticsearch: How Many Shards per Index
[2]Elasticsearch写入性能优化