蒙特卡洛方法(Monte-Carlo Simulation)
目录
布封投针问题(Buffon's needle problem)
蒙特卡洛方法(Monte-Carlo Simulation)
估算PI
估计不规则图形的面积
随机抛点
采样估计
样本采集
拒绝采样(reject sample)
封投针问题(Buffon's needle problem)
问题:
1、取一张白纸,画出间隔为![]() 的等距平行线。
的等距平行线。
2、取一根长度为![]() 的针,随机地向画有等距平行线的纸上掷
的针,随机地向画有等距平行线的纸上掷![]() 次,观察针与直线相交的次数,记为
次,观察针与直线相交的次数,记为![]() 。
。
3、计算针与直线相交的概率。
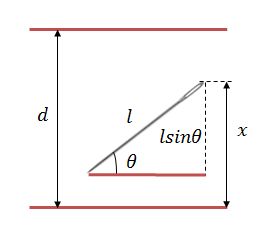
这个概率值是![]() ,其中
,其中![]() 是圆周率。
是圆周率。
证明:
上图中,
表示针的尾部与平行线的距离,
,
表示针与平行线的夹角,
。由于针是随机落到平行线内的,所以概率是均等的,即
。要使得针与边界相交,那么就要满足
。那么要求针与边界相交的概率,就是在可行域内解进行积分,即:
Buffon投针问题,反映出了,相交次数与
的关系,从而可以估算出
蒙特卡洛方法(Monte-Carlo Simulation)
蒙特卡洛方法是一种以概率统计理论为指导的一类非常重要的数值计算方法。蒙特卡罗是摩纳哥公国的一座城市(赌城)。Buffon投针就是蒙特卡洛方法的思想,但是Buffon是蒙特卡洛方法的起源。蒙特卡洛方法同样可以通过随机通过产生随机数的方式来解决计算问题。比如估算![]() 和计算不规则图形的面积。如果你觉得Buffon投针方法来估算
和计算不规则图形的面积。如果你觉得Buffon投针方法来估算![]() 比较复杂,那么来看用另一种简单的Monte-Carlo方法估算
比较复杂,那么来看用另一种简单的Monte-Carlo方法估算![]() 。
。
估算PI
给定一个边长为![]() 的正方形,里是一个内切的
的正方形,里是一个内切的![]() 圆,我们知道正方形的面积是
圆,我们知道正方形的面积是![]() ,而
,而![]() 的面积
的面积![]() 。怎么估算
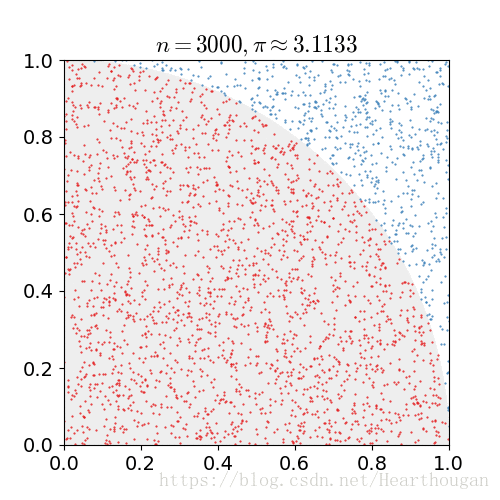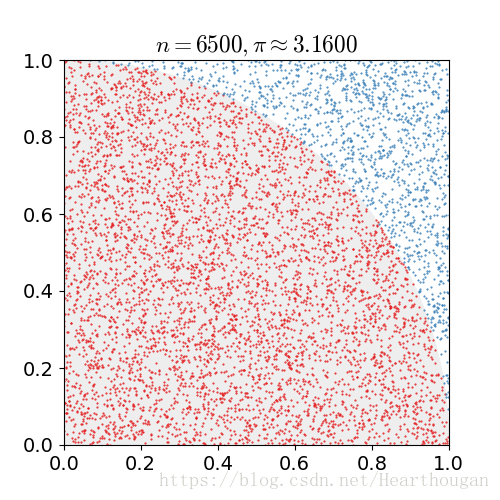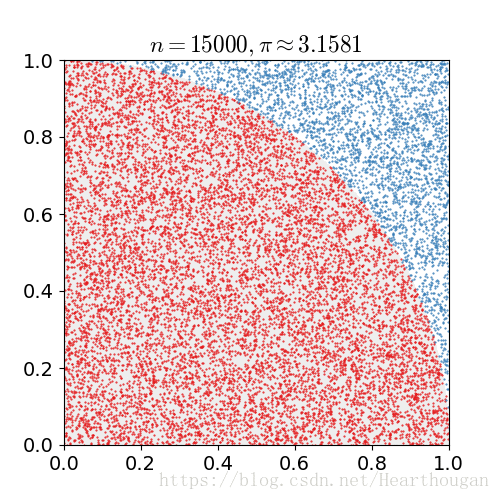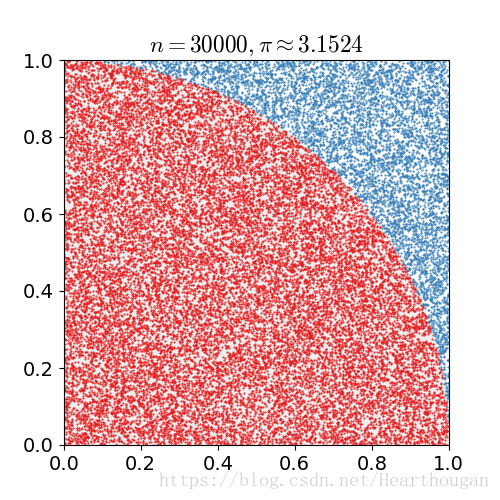
。怎么估算![]() 呢?向正方形内随机抛点,最后计算落在圆弧内的点,计算概率然后再乘以
呢?向正方形内随机抛点,最后计算落在圆弧内的点,计算概率然后再乘以![]() ,就是
,就是![]() 的估算值。如下图所示。随着抛出的点数增加,
的估算值。如下图所示。随着抛出的点数增加,![]() 的估计值越准确。
的估计值越准确。
# -*- coding: utf-8 -*-
"""
Created on Sat Sep 1 11:07:51 2018
@author: abner_hg
"""
import random
import math
icount = 0
iter_num = 10000
x_axis = []
y_axis = []
for i in xrange(iter_num):
x = random.random()
y = random.random()
if math.sqrt(x**2 + y**2) <= 1:
icount += 1
print('Pi = ', float(4*icount)/float(iter_num))
估计不规则图形的面积
随机抛点估计
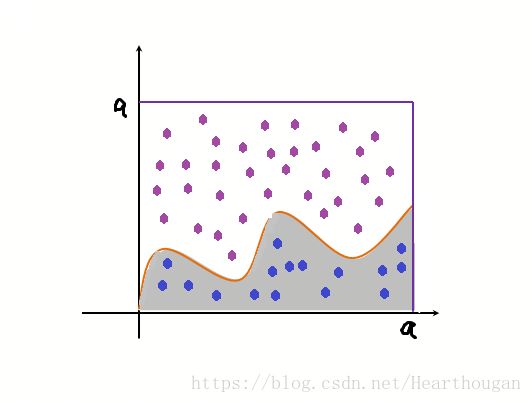
假设我们需要计算一个不规则图形的面积,那么图形的不规则程度和分析性计算(比如积分)的复杂程度是成正比的。而采用蒙特卡罗方法是怎么计算的呢?如下图,假设我们不知道曲线的具体函数表达式或者难以求出具体的函数表达式,那么我们该怎么估算阴影部分的面积?首先可以取一个边长为![]() 的正方形,然后你可以随机地向正方形内,随机抛一些点,计算落在阴影部分的个数,最后除以抛出的总个数,得出的值再乘以
的正方形,然后你可以随机地向正方形内,随机抛一些点,计算落在阴影部分的个数,最后除以抛出的总个数,得出的值再乘以![]() ,就是阴影部分的面积一个估算。抛出的点数越多,估算越准确,这个就是蒙特卡洛思想。
,就是阴影部分的面积一个估算。抛出的点数越多,估算越准确,这个就是蒙特卡洛思想。
采样估计
假设我们知道函数表达式![]() ,我们知道求解阴影部分的面积,可以对函数直接进行积分
,我们知道求解阴影部分的面积,可以对函数直接进行积分![]() 。那么如果,我们难以计算积分,该怎么办?随机抛点的方法是可以的,但是有没有其他的方法?如下图,我们可以随机地在
。那么如果,我们难以计算积分,该怎么办?随机抛点的方法是可以的,但是有没有其他的方法?如下图,我们可以随机地在![]() 上取一个点
上取一个点![]() ,用
,用![]() 来代表所有的函数值,那么积分值就可以认为是
来代表所有的函数值,那么积分值就可以认为是![]() 。
。
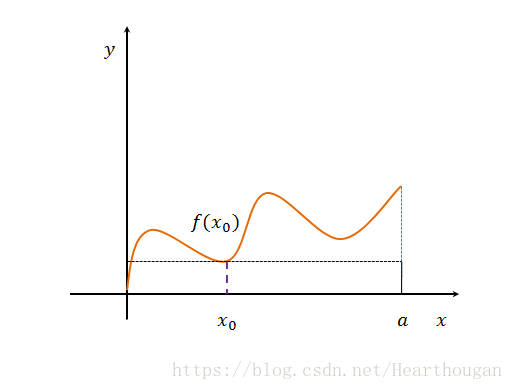
上图的估算结果肯定是不准确的,因为从图中来看,有很多函数值是大于![]() 的,那么为了使得估算更精确,我们需要采集更多的点,如下图,
的,那么为了使得估算更精确,我们需要采集更多的点,如下图,
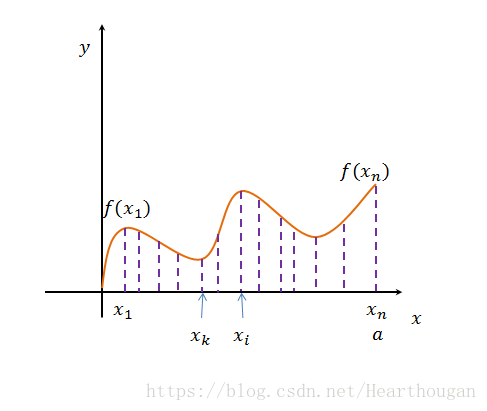
以这些函数值的均值![]() 来表示所有的函数值,那么对积分的估算,就变成了
来表示所有的函数值,那么对积分的估算,就变成了![]() 。这种方式估算貌似比上一种更靠谱些。但是存在一个问题,我们取函数值都是随机取的,也就是在哪个地方采集样本点的概率都是一样的。假如我们的函数
。这种方式估算貌似比上一种更靠谱些。但是存在一个问题,我们取函数值都是随机取的,也就是在哪个地方采集样本点的概率都是一样的。假如我们的函数![]() 表示概率密度函数(probability density function,pdf),积分就变成了求其累积分布函数(Cumulative Distribution Function,CDF)。那么在上图中
表示概率密度函数(probability density function,pdf),积分就变成了求其累积分布函数(Cumulative Distribution Function,CDF)。那么在上图中![]() 附近的点,应该比
附近的点,应该比![]() 附近的点更加密集,因为
附近的点更加密集,因为![]() 附近处的概率值比较大,而
附近处的概率值比较大,而![]() 附近处的概率值比较小,因此我们不能简单地随机采集样本。那么求解上述积分的关键,就是如何采集样本点。
附近处的概率值比较小,因此我们不能简单地随机采集样本。那么求解上述积分的关键,就是如何采集样本点。
样本采集
如何采集样本是蒙特卡洛方法的关键一步,在《LDA数学八卦》中,有这么一段话:
统计模拟中有一个重要的问题就是给定一个概率分布
,我们如何在计算机中生成它的样本。一般而言均匀分布
的样本是相对容易生成的。通过线性同余发生器可以生成伪随机数,我们用确定性算法生成[0,1]之间的伪随机数后,这些序列的各种统计指标和均匀分布
我们常见的概率分布,连续或者离散的情况,都可以基于![]() 的样本生成。例如正态分布,可以由Box-Muller变换得到。
的样本生成。例如正态分布,可以由Box-Muller变换得到。
定理:(Box-Muller变换)如果随机变量
,
独立且
,则:
则
独立且服从标准正态分布。
写这么多的目的就是想表达,很多常见的分布,是可以基于均匀分布来实现采样。回到刚才的问题,我们的![]() 比较复杂,难以采样,那么该如何实现采样?
比较复杂,难以采样,那么该如何实现采样?
拒绝采样(reject sample)
接下来我们以概率分布函数来讲解,假如给定的函数的值域大于1,我们可以归一化到![]() 之间,从而可以看成概率密度函数。假如
之间,从而可以看成概率密度函数。假如![]() 是我们常见的可采集的概率密度函数,那么是否存在一个
是我们常见的可采集的概率密度函数,那么是否存在一个![]() 永远大于
永远大于![]() 呢?答案是否定的,因为所有的概率之和要满足1,故任意两个概率密度函数一定有交点。如下图,就是我们找到的一个概率密度函数。
呢?答案是否定的,因为所有的概率之和要满足1,故任意两个概率密度函数一定有交点。如下图,就是我们找到的一个概率密度函数。
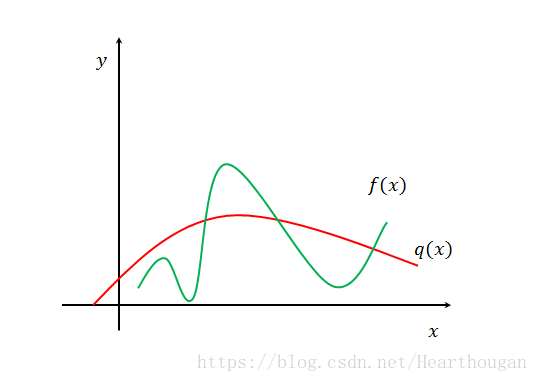
拒绝采样的步骤:
1、在
上采集一个样本点
2、计算接受率
。
3、在均匀分布
上,随机选择一个
。
4、如果
那么接受
。
5、重复步骤
。

解释两个问题,1、什么是接受率。2、为什么要在均匀分布上选取一个![]() 来决定是否接受
来决定是否接受![]() 。
。
问题1:
如上图所示,表示落在绿线以下的部分是可接受的,落在绿线和红线之间的,是被拒绝的。那么那个判断的临界点就是接受率,在数学上的表示就是![]() 。
。
问题2:
我们在![]() 上随机采集了一个点
上随机采集了一个点![]() ,我们不知道它是在那个区域,我们凭直觉可以知道,如果两个函数,越接近,那么被接受的区域就越大(上图紫线越长),也就是
,我们不知道它是在那个区域,我们凭直觉可以知道,如果两个函数,越接近,那么被接受的区域就越大(上图紫线越长),也就是![]() 越大,如果两个函数相聚越远,那么被拒绝的区域也就越大(上图红线越长),也就是
越大,如果两个函数相聚越远,那么被拒绝的区域也就越大(上图红线越长),也就是![]() 越小。此时怎么办,不能而用抛硬币的方法来决断,太过草率,由于
越小。此时怎么办,不能而用抛硬币的方法来决断,太过草率,由于![]() 是一个属于
是一个属于![]() 之间的一个值,我们可以用在均匀分布上进行随机生成一个数,如果大于
之间的一个值,我们可以用在均匀分布上进行随机生成一个数,如果大于![]() 就拒绝,如果小于就接受。当然,这种方式也存在误判情况。但是如果你的
就拒绝,如果小于就接受。当然,这种方式也存在误判情况。但是如果你的![]() 与
与![]() 比较接近的话,被误判的可能性就越小,但是随着采集的样本点的增加,被接受的样本点的函数值,大体上会与
比较接近的话,被误判的可能性就越小,但是随着采集的样本点的增加,被接受的样本点的函数值,大体上会与![]() 保持一致。
保持一致。
拒绝采样的缺点:
1、如果
与
相距比较远,那么被被拒绝的样本点会很多,采集10000个有可能被拒绝掉8000个,即使相距较劲,也可能被拒绝掉,费了很大劲,才计算出来的结果,被拒绝了,费时费力!
2、如果我们的分布是在高维上,
是很难确定的。
采样的方法有很多,以后有时间会在这一块写个总结。
我们知道了如何采样,就知道了样本集,那么我们就可以对计算问题利用随机模拟的方式进行估算,这就是蒙特卡洛方法的思想。
参考:《LDA数学八卦》