《ElasticStack从入门到实践》学习笔记1
一、ElasticSearch入门介绍
1、常见术语:
A、Document 文档
用户存储在ES中的数据文档。
B、Index 索引
由具有相同字段的文档列表组成。在当前版本,不在推荐下设Type,在后续版本,不再设立Type。
C、field 字段
包含具体数据。
D、Node 节点
一个ES的实例,构成clister的单元
E、Cluster 集群
对外服务的一个/多个节点
2、Document介绍:
A、常用数据类型:字符串、数值型、布尔型、日期型、二进制、范围类型
B、每个文档都有一个唯一ID标识。(可以自行指定,也可由ES自动生成)
C、元数据,用于标注文档的相关信息:
a、_index: 文档所在的索引名
b、_type: 文档所在的类型名
c、_id: 文档唯一标识
d、_uid: 组合id、由_type和_id组成,后续版本中_type不再有用,同_id
e、_source: 文档的原始JSON数据,可从这获取每个字段的内容
f、_all: 整合所有字段内容到该字段。(默认禁用)
g、_version: 文档字段版本号,标识被操作了几次
3、Index介绍:
A、索引中存储相同结构的文档,且每个index都有自己的Mapping定义,用于定义字段名和类型;
B、一个集群中可以有多个inex,类似于可以有多个table。
4、RESTful API:
A、有两种交互方式:
a、CURL命令行——————curl -XPUT xxx
b、Kibana DevTools————PUT xxx{ }
B、本次学习使用DevTools方式进行开发。
5、Index API:
用户创建、删除、获取索引配置等。
A、创建索引:
PUT /test_index #创建一个名为test_index的索引B、查看索引:
GET _cat/indices #查看所有的索引C、删除索引:
DELETE /test_index #删除名为test_index的索引6、Document API:
A、创建文档:
a、指定ID创建Document
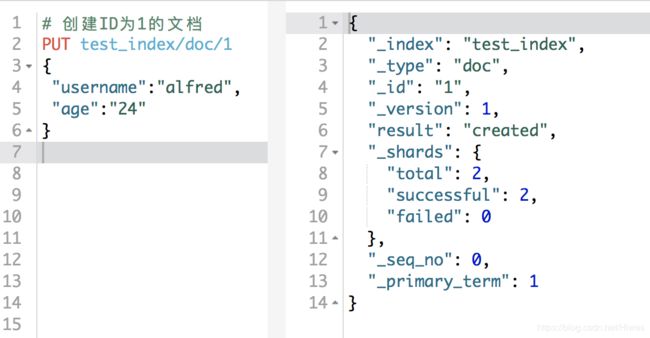
#创建ID为1的文档
PUT /test_index/doc/1
{
"username":"alfred",
"age":"24"
}
返回结果:
b、不指定ID创建Document
POST /test_index/doc
{
"username":"buzhiding",
"age":"1"
}返回结果:
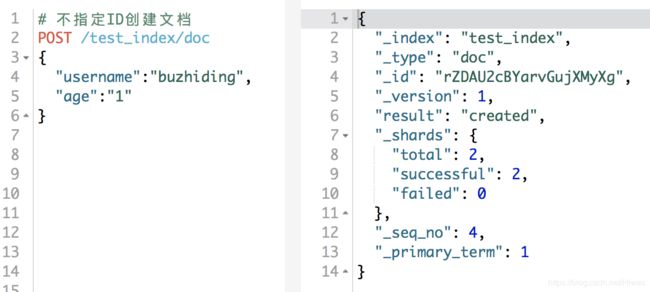
可以看到,ES自动指定了id,为rZDAU2cBYarvGujXMyXg。
B、查询文档:
#查看名为test_index的索引中id为1的文档
GET /test_index/doc/1C、查询所有文档:
#查询名为test_index的索引中所有文档,用到endpoint:_search,默认返回符合的前10条
GET /test_index/doc/_search
{
"query":{
"term":{
"_id":"1"
}
}
}
#term和match的区别:term完全匹配,不进行分词器分析;match模糊匹配,进行分词器分析,包含即返回D、批量创建文档:
ES运行一次创建多个文档,从而减少网络传输开销,提升写入速率。
#批量创建文档,用到endpoint:_bulk
POST _bulk
{"index":{"_index":"test_index","_type":"doc","_id":"3"}}
{"username":"alfred","age":"20"}
{"delete":{"_index":"test_index","_type":"doc","_id":"1"}}
{"update":{"_id":"2","_index":"test_index","_type":"doc"}}
{"doc":{"age":"30"}}
#index和create的区别,如果文档存在时,使用create会报错,而index会覆盖E、批量查询文档:
#批量查询文档,使用endpoint:_mget
GET _mget
{
"doc":[
{
"_index":"test_index",
"_type":"doc",
"_id":"1"
},
{
"_index":"test_index",
"_type":"doc",
"_id":"2"
}
]
}F、根据搜索内容删除文档:
#根据搜索内容删除文档,使用endpoint:_delete_by_query
POST /test_index/doc/_delete_by_query
{
"query":{
"match":{
"username":"buzhiding"
}
}
}
#删除名为test_index的索引中的username为不指定的文档G、删除整个Type:
#直接删除整个type,依然使用endpoint:_delete_by_query
POST /test_index/doc/_delete_by_query
{
"query":{
"match_all":{}
}
}
#会直接删除名为test_index的索引下的所有type