CVPR2018 | R(2+1)D结构:视频动作识别中的时空卷积深度探究
本文 是C3D作者Du Tran+IDT作者Heng Wang发表在CVPR2018的新作。来自Facebook Resaerch &Dartmouth Colledge。文章主要对是动作识别中的各种卷积块进行了深度探究,然后提出了用于视频动作识别的新型网络结构:R(2+1)D。
阅读这篇文章之前,可以看一下对比文章《Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks》。关于3维卷积,可以看一下文章《Learning Spatiotemporal Features with 3D Convolutional Networks》
摘要
本文讨论了针对视频分析的不同形式的时空卷积,并研究了其在动作识别方面的效果。本文的灵感来源是,对单帧视频进行2D 卷积仍然可以获得接近3D 时空卷积方法中state-of-the-art的结果本文首先经验性展示3D CNN 比2DCNN 在残差学习框架中的精确度优势,然后展示了将3维时空卷积分解成单独的时间和空间卷积可以在精确度上涨点许多。并通过实验和经验,设计了一种新的时空卷积块“R(2+1)D”。这种新卷积块在数据集如Sports-1M,Kinetics,UCF101,HMDB51上可以取得甚至超过state-of-the-art。
引言
深度学习对静态图像领域产生了深远影响,但在视频领域,深度学习方法并没有吊打最好的传统手提特征工程(iDT)。另外,2D卷积(ResNet-152)在视频单帧上的表现十分接近3D卷积的最佳表现。这一结果就让视频界哭笑不得了。之前的观点是,2D卷积不能对视频分析中的时间信息和动作模式建模。但基于2D卷积的实验,说明temporal reasoning未必就是精确动作识别的必要条件,因为重要的动作类别信息已经包含在了视频的一个个静态视频帧中。
但是话说回来,之前很多3D CNN模型实验结果同样表明其在相同网络深度下在大规模数据集下效果还是优于2D CNN模型的。
基于这些结果,本文打了个太极,安利了介于2D,3D之间的两款时空卷积新品。
要安利的第一款是一种混合型卷积(MixedConvolution)——在浅层使用3维卷积,在深层接上2维卷积。这种设计是有道理的,因为我们一直认为,动作(motion)建模是一种中低层的操作(low、mid-level operation),故在对应的网络浅层只使用3维卷积来操作一波,剩下的空间推断使用2维卷积在这些mid-level动作特征基础上在深层搞一搞就OK了。实验表明这一款混合香型卷积是比2维卷积操作的精确度涨点了大约3-4个百分点的。
第二款要安利的是2+1维卷积块,思路很明确,就是把3维卷积操作分解成两个接连进行的子卷积块—2维空间卷积和1维时间卷积。
相关工作
文章中提及许多视频理解相关工作,并且向手提特征工程IDT致敬,CVPR2017的I3D是当前的state-of-the-art。这里主要介绍之前两种深度学习视频理解方法的基本款,为主体工作做铺垫。
先是Du Tran 的C3D(Learning Spatiotemporal Features with 3D Convolutional Networks)
首先介绍一下3D convolution:

(a)是2维卷积,(b)是3维卷积。3维卷积是通过堆叠多个连续的帧组成一个立方体,然后在立方体中运用3D卷积核。在这个结构中,卷积层中每一个特征map都会与上一层中多个邻近的连续帧相连,因此捕捉运动信息。一个卷积map的某一位置的值是通过卷积上一层的三个连续的帧的同一个位置的局部感受野得到的。假设输入的是RGB视频片段,(b)中时间维度上卷积核大小为3,并且在同一个颜色通道上共享权值。以下是C3D模型的网络结构。

接着说一下和本文提出的R(2+1)D十分相似的网络P3D(Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks),这个网络安利了3种3维残差卷积块,如下图,
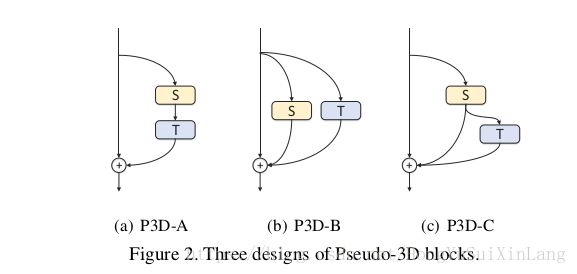
分别是空间卷积串联时间卷积,时间和空间卷积平行,已经空间卷积后接时间卷积同事和残差块输出有skip connection。P3D网络随网络加深交错使用这三种块。
与P3D相比,本文安利的R(2+1)D有以下不同:整个网络只使用一种残差块;并且没有bottleneck;R(2+1)D进行了超参数设计,使得3维卷积分解前后参数量一致。
视频理解中的各种卷积残差块
本小节讨论时空卷积残差块各变种。本文所用残差块均为vanilla类型(没有bottleneck结构),每个残差块内有两个卷积层。输入视频片段尺寸是3×L×H×W,L是输入视频帧数,H,W是各帧高和款,视频片段是RGB,3指的是RGB3通道。第i个卷积块输出表示为

本文的网络结构是从浅层到深层残差块一把梭,然后接一个全局池化层和全连接层来分类。
R2D:2维卷积在视频中一把梭
2维卷积残差块处理视频,就忽略了视频的时间顺序,把L当作通道处理。所以2维模型就是把输入的4维张两reshape为3维张量:3L×H×W.
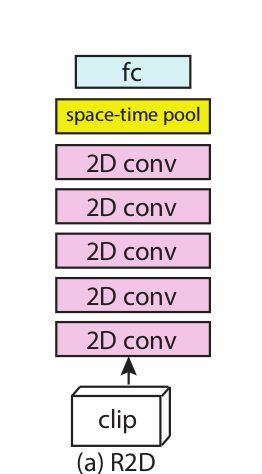
f-R2D:基于帧的2维卷积
另一种2维卷积方法用一系列的2维卷积残差块来处理独立的各帧,同一个卷积核作用到所有L个帧上。用时空GAP层融合来自各帧的信息,我们称这种2维卷积维framed-based R2D。
R3D:3维卷积
3维卷积保留了时间信息,并可以在层与层之间传播。3维卷积残差块的输出则是4维张量,大小是N×L×H×W,每一个卷积核也是4维的,尺寸是N‘×t×d×d,t是时间维度上的跨度,帧数。N’是上一层输出的3维卷积核个数。网络结构如下图

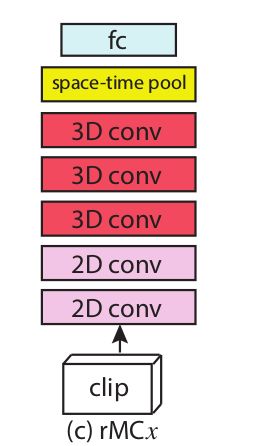
MCx&rMCx:2维,3维混合卷积
先跑出一个猜想:动作建模在浅层是有用的,但在高级语义抽象层(深层),动作建模是不必要的。所以就有了混合型结构如下图

当然作为对比,还是有一种可能的情况就是时间信息在深层仍然很重要,所以就在浅层空间建模,深层时空建模加入时间信息。这种结构称为rMCx,结构如下图
R(2+1)D
把3维时空卷积分解成2维空间卷积和1维时间卷积,那么卷积核大小变成了N’×1×d×d+M×t×1*1。超参数M决定了信号在时、空卷积之间投影的子空间个数。为了让(2+1)维卷积块参数和3维卷积块参数量一致,

将3维时空卷积分解成(2+1)维卷积的图示如下(这里输入为单通道)
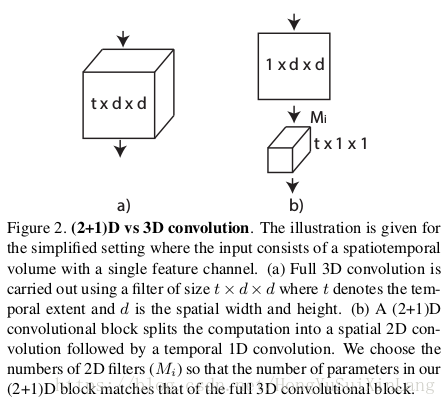
这个分解的好处,第一就是两个子卷积之间多出来一个非线性操作,和原来同样参数量的3维卷积相比double了非线性操作,给网络扩容。第二个好处就是时空分解让优化的过程也分解开来,事实上之前发现,3维时空卷积把空间信息和动态信息拧巴在一起,不容易优化。2+1维卷积更容易优化,loss更低。

结构如下图

实验
基准数据集是Kinetics和Sports-1M,它们足够从头训练深度网络。当然一个好的视频模型还要支持迁移学习,所以本文在一说两个数据集上pretrain,在UCF01和HMDB51数据集上finetune.
####网络框架
我们实验所用网络全部是残差卷积块。下表给出了3D ResNet网络明细
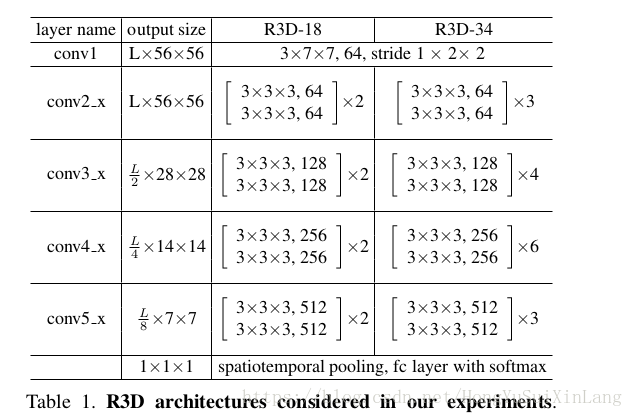
两组网路是3D ResNet-18,3D ResNet-24.网络输入统一为3×L×112×112。在conv1,stride=(1,2,2),在conv3_1,conv4_1,conv5_1,stride=(2, 2, 2).
我们以R3D模型维baseline,通过将3维卷积替换维2维卷积,先时空再空间和先空间再时空混合卷积,以及分解的(2+1)维卷积,获得R2D,MCx,rMCx,和R(2+1)D网络结构。这里有一个小问题,替换3维为2维过程中,时间维度上的跨步就无法实现,因为没有了时间卷积。这种差别体现在最后一层卷积层的输出Tensor和原3维卷积模型最后一层卷积层输出的Tensor时间尺寸不一致。不过,我们的网络在卷积层之后接global spatiotemporal average pooling,然后传入全连接层。卷积层输出的时间、空间尺寸没有影响。
训练和测试
数据预处理
首先在数据集Kinetics上,划分出训练集和测试集,公平起见所有模型都统一成18层,在相同输入上从头开始训练。视频帧scale到128×171,然后每个视频片段都是用一个112×112的窗口随机crop产生。对视频进行时间抖动(temporal jittering),然后随机选取连续L帧。时间抖动的方法是把epoch size设为1M,而数据集只有0.24M个视频,故没一epoch就有了时长增广。
训练
初始学习率设为0.01,没10epoch 除以10,前10 epoch 使用了warm-up方法,一种分布式同步 SGD ,分布式同步 SGD 通过将小批量 SGD(SGD minibatches)分发到一组平行工作站而提供了一种很具潜力的解决方案。然而要使这个解决方案变得高效,每一个工作站的工作负载必须足够大,这意味着 SGD 批量大小会有很大的增长(nontrivial growth)。训练了45epoch。每一卷积层都使用了BN。使用caffe2框架。
实验对比

从这些结果中我们可以推断出一下几点:
- F-R2D,R2D 这些2维卷积和R3D或者MCx,rMCx之间是有显著差距的(2维较差),这个差距会在输入帧数为16时变大。说明动作建模对动作识别来说是十分重要的。(所以本文并没有挑战这一观点)
- 分解的时空卷积效果要比3维卷积和混合卷积好,更比2维卷积模型效果好。
- 在较长输入片段进行时间建模更加有效,但不能过长。
- 随着网络深度正增加,R(2+1)D比R3D更容易训练。
水平有限,欢迎大家斧正
HongYuSuiXinLang
Zhejiang University
Email: [email protected]