Mean Shift 算法原理及 Python 实现
一、 Mean Shift 算法
K-Means 算法最终的聚类效果受初始的聚类中心的影响,K-Means++ 算法未选择较好的初始聚类中心提供了依据,但在 K-Means 算法中,聚类的类别个数 k 仍需要事先指定。对于类别个数未知的, K-Means 算法和 K-Means++ 算法很难将其进行精确求解。 Mean Shift 算法被提出用于解决聚类个数未知的情况。
Mean Shift 算法又称均值漂移算法,是基于聚类中心的聚类算法。实现不需要指定类别个数k,聚类中心是通过在给定区域中的均值来确定的,通过不断更新聚类中心,直到最终的聚类中心不再改变。 Mean Shift 算法在聚类、图像平滑、分割和视频跟踪等方面有广泛的应用。
二、 Mean Shift 算法的原理
1.核函数
Mean Shift算法中引入核函数的目的是使得随着样本与被偏移点的距离不同,其偏移量对均值偏移向量的贡献也不同
核函数的定义
X表示一个d维的欧式空间,x是该空间中的一个点x={x1,x2,x3⋯,xd},其中,x的模![]() ,R表示实数域,如果一个函数K:X→R存在一个剖面函数
,R表示实数域,如果一个函数K:X→R存在一个剖面函数![]() ,即
,即
![]()
并且满足:
- k是非负的
- k是非增的
- k是分段连续的
那么,函数K(x)就称为核函数。
常用的核函数
线性核:![]()
多项式核:![]() ,
,![]() 为多项式次数
为多项式次数
高斯核:![]() ,
,![]() 为高斯核的带宽
为高斯核的带宽
拉普拉斯核:![]()
Sigmoid核:![]() ,tanh为双曲正切函数,
,tanh为双曲正切函数,![]()
在这里我们使用高斯核函数,将他写成下面的形式:
![]()
h为带宽,不同带宽的核函数如下所示:
import matplotlib.pyplot as plt
import math
def cal_Gaussian(x, h=1):
molecule = x * x
denominator = 2 * h * h
left = 1 / (math.sqrt(2 * math.pi) * h)
return left * math.exp(-molecule / denominator)
x = []
for i in range(-20,20):
x.append(i * 0.5);
score_1 = []
score_2 = []
score_3 = []
for i in x:
score_1.append(cal_Gaussian(i,1))
score_2.append(cal_Gaussian(i,2))
score_3.append(cal_Gaussian(i,3))
plt.figure(figsize=(10,8), dpi=80)
plt.plot(x, score_1, 'r--', label="h=1")
plt.plot(x, score_2, 'b--', label="h=2")
plt.plot(x, score_3, 'g--', label="h=3")
#显示中文标题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.legend(loc="upper right")
plt.title("高斯核函数")
plt.xlabel("x")
plt.ylabel("K")
plt.show()
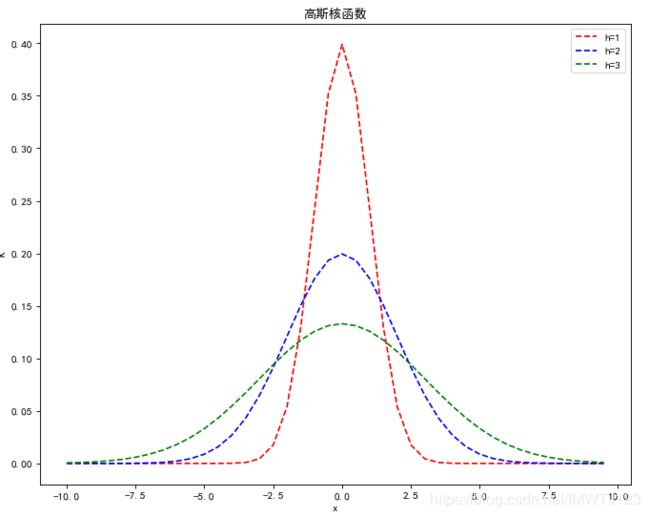
从图中可以看出,当 h 一定是,样本点之间的距离越近,其核函数的值越大;当样本点之间的距离相等时,随着高斯核函数的带宽 h 的增大,核函数的值在减少。
2.基本原理
基本的Mean Shift向量
对于给定的d维空间Rd中的n个样本点xi,i=1,⋯,n,其Mean Shift向量的基本形式为:
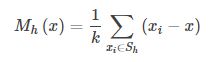
其中,Sh指的是一个半径为h的高维球区域,Sh的定义为:
![]()
这样的Mean Shift形式存在一个问题:在Sh的区域内,每一个点对x的贡献是一样的。而实际上,每一个样本点对x的贡献是不一样的。
改进的Mean Shift向量
为使每一个样本点对x的贡献不一样,基本的Mean Shift向量形式中增加核函数,得如下改进的Mean Shift向量形式:
![M_{h}(X)=\frac{\sum_{X^{i}\in S_{h}}[K(\frac{X^{i}-X}{h})\cdot (X^{i}-X)]}{\sum_{X^{i}\in S_{h}}[K(\frac{X^{i}-X}{h})]}](http://img.e-com-net.com/image/info8/494f65a5247c4d85b3b5b537287e74d8.gif)
其中![]() 为高斯核函数,可以取Sh为整个数据集范围,Mean Shift向量Mh(x)是归一化的概率密度梯度。
为高斯核函数,可以取Sh为整个数据集范围,Mean Shift向量Mh(x)是归一化的概率密度梯度。
Mean Shift 算法的基本过程
聚类中心是通过在给定区域中的均值来确定的,通过不断更新聚类中心,直到最终的聚类中心不再改变退出。
1.在指定的区域内计算偏移均值(如下图的黄色的圈),并移动该点到偏移均值点处
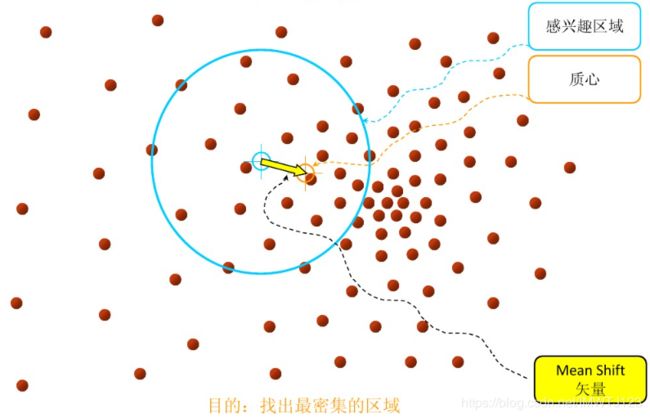
2.重复上述的过程计算新的偏移均值,并移动到偏移均值点处
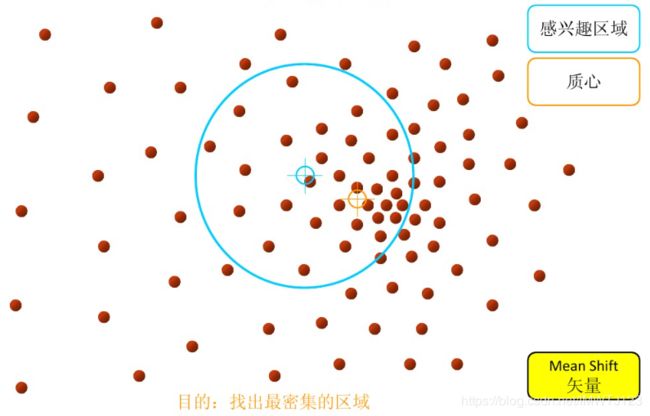
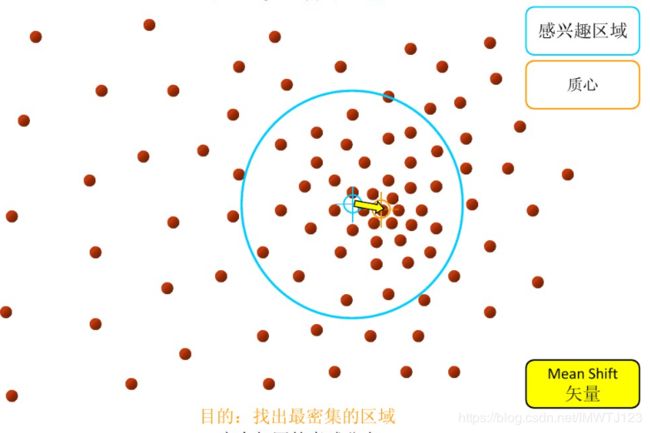
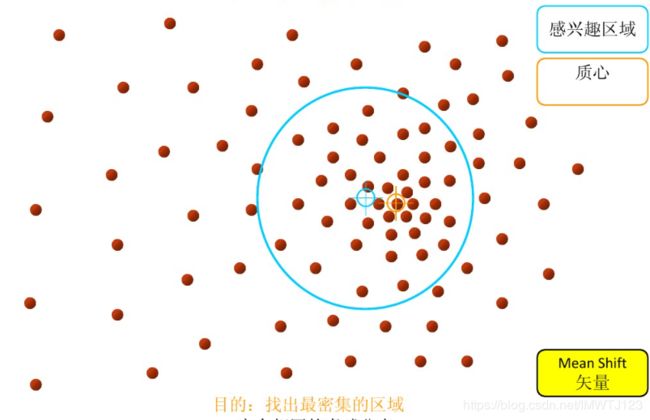
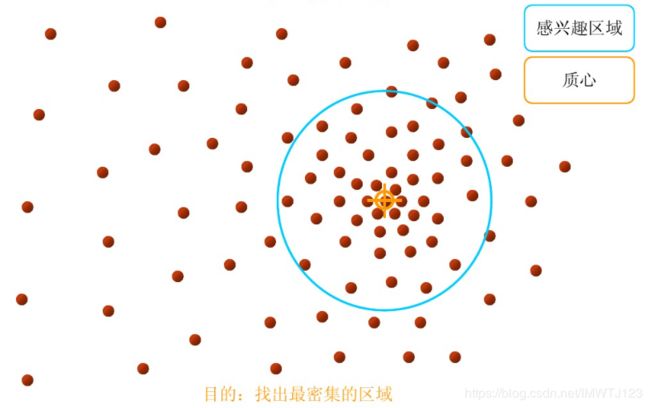
3.直到最终的聚类中心不再改变退出
Mean Shift算法的解释
在Mean Shift算法中,实际上是利用了概率密度,求得概率密度的局部最优解。
对一个概率密度函数f(x),已知d维空间中n个采样点xi,i=1,⋯,n,f(x)的核函数估计(也称为Parzen窗估计)为:

Mean Shift向量的修正:
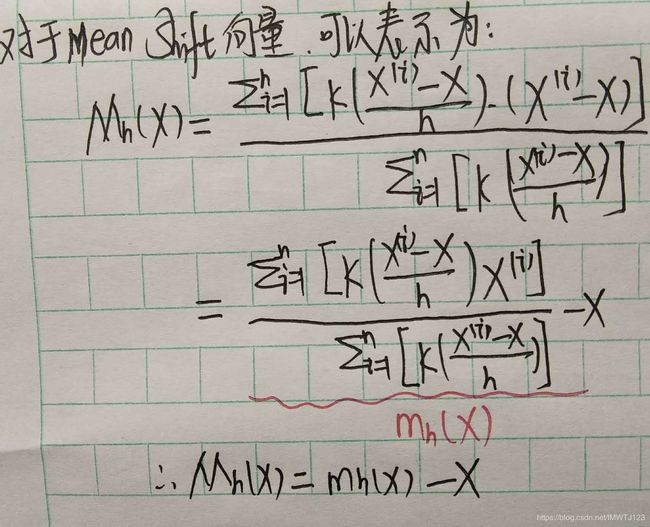
3.算法流程
- 计算
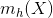
- 令
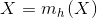
- 如果
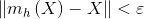 ,结束循环,否则,重复上述步骤。
,结束循环,否则,重复上述步骤。
三、Mean Shift 算法实践
# -*- coding: utf-8 -*-
"""
Created on Tue Apr 2 17:16:08 2019
@author: 2018061801
"""
import matplotlib.pyplot as plt
import math
import numpy as np
MIN_DISTANCE = 0.000001 # mini error
def load_data(path, feature_num=2):
'''导入数据
input: path(string)文件的存储位置
feature_num(int)特征的个数
output: data(array)特征
'''
f = open(path) # 打开文件
data = []
for line in f.readlines():
lines = line.strip().split("\t")
data_tmp = []
if len(lines) != feature_num: # 判断特征的个数是否正确
continue
for i in range(feature_num):
data_tmp.append(float(lines[i]))
data.append(data_tmp)
f.close() # 关闭文件
return data
def gaussian_kernel(distance, bandwidth):
'''高斯核函数
input: distance(mat):欧式距离
bandwidth(int):核函数的带宽
output: gaussian_val(mat):高斯函数值
'''
m = np.shape(distance)[0] # 样本个数
right = np.mat(np.zeros((m, 1))) # mX1的矩阵
for i in range(m):
right[i, 0] = (-0.5 * distance[i] * distance[i].T) / (bandwidth * bandwidth)
right[i, 0] = np.exp(right[i, 0])
left = 1 / (bandwidth * math.sqrt(2 * math.pi))
gaussian_val = left * right
return gaussian_val
def shift_point(point, points, kernel_bandwidth):
'''计算均值漂移点
input: point(mat)需要计算的点
points(array)所有的样本点
kernel_bandwidth(int)核函数的带宽
output: point_shifted(mat)漂移后的点
'''
points = np.mat(points)
m = np.shape(points)[0] # 样本的个数
# 计算距离
point_distances = np.mat(np.zeros((m, 1)))
for i in range(m):
point_distances[i, 0] = euclidean_dist(point, points[i])
# 计算高斯核
point_weights = gaussian_kernel(point_distances, kernel_bandwidth) # mX1的矩阵
# 计算分母
all_sum = 0.0
for i in range(m):
all_sum += point_weights[i, 0]
# 均值偏移
point_shifted = point_weights.T * points / all_sum
return point_shifted
def euclidean_dist(pointA, pointB):
'''计算欧式距离
input: pointA(mat):A点的坐标
pointB(mat):B点的坐标
output: math.sqrt(total):两点之间的欧式距离
'''
# 计算pointA和pointB之间的欧式距离
total = (pointA - pointB) * (pointA - pointB).T
return math.sqrt(total) # 欧式距离
def group_points(mean_shift_points):
'''计算所属的类别
input: mean_shift_points(mat):漂移向量
output: group_assignment(array):所属类别
'''
group_assignment = []
m, n = np.shape(mean_shift_points)
index = 0
index_dict = {}
for i in range(m):
item = []
for j in range(n):
item.append(str(("%5.2f" % mean_shift_points[i, j])))
item_1 = "_".join(item)
if item_1 not in index_dict:
index_dict[item_1] = index
index += 1
for i in range(m):
item = []
for j in range(n):
item.append(str(("%5.2f" % mean_shift_points[i, j])))
item_1 = "_".join(item)
group_assignment.append(index_dict[item_1])
return group_assignment
def train_mean_shift(points, kenel_bandwidth=2):
'''训练Mean shift模型
input: points(array):特征数据
kenel_bandwidth(int):核函数的带宽
output: points(mat):特征点
mean_shift_points(mat):均值漂移点
group(array):类别
'''
mean_shift_points = np.mat(points)
max_min_dist = 1
iteration = 0 # 训练的代数
m = np.shape(mean_shift_points)[0] # 样本的个数
need_shift = [True] * m # 标记是否需要漂移
# 计算均值漂移向量
while max_min_dist > MIN_DISTANCE:
max_min_dist = 0
iteration += 1
print ("\titeration : " + str(iteration))
for i in range(0, m):
# 判断每一个样本点是否需要计算偏移均值
if not need_shift[i]:
continue
p_new = mean_shift_points[i]
p_new_start = p_new
p_new = shift_point(p_new, points, kenel_bandwidth) # 对样本点进行漂移
dist = euclidean_dist(p_new, p_new_start) # 计算该点与漂移后的点之间的距离
if dist > max_min_dist:
max_min_dist = dist
if dist < MIN_DISTANCE: # 不需要移动
need_shift[i] = False
mean_shift_points[i] = p_new
# 计算最终的group
group = group_points(mean_shift_points) # 计算所属的类别
return np.mat(points), mean_shift_points, group
def save_result(file_name, data):
'''保存最终的计算结果
input: file_name(string):存储的文件名
data(mat):需要保存的文件
'''
f = open(file_name, "w")
m, n = np.shape(data)
for i in range(m):
tmp = []
for j in range(n):
tmp.append(str(data[i, j]))
f.write("\t".join(tmp) + "\n")
f.close()
if __name__ == "__main__":
# 导入数据集
print ("----------1.load data ------------")
data = load_data("D:/anaconda4.3/spyder_work/data5.txt", 2)
# 训练,h=2
print ("----------2.training ------------")
points, shift_points, cluster = train_mean_shift(data, 2)
# 保存所属的类别文件
print ("----------3.1.save sub ------------")
save_result("sub_1", np.mat(cluster))
print ("----------3.2.save center ------------")
# 保存聚类中心
save_result("center", shift_points)
f = open("D:/anaconda4.3/spyder_work/data5.txt")
x = []
y = []
for line in f.readlines():
lines = line.strip().split("\t")
if len(lines) == 2:
x.append(float(lines[0]))
y.append(float(lines[1]))
f.close()
#显示中文标题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(10,8), dpi=80)
plt.plot(x, y, 'b.', label="原始数据")
plt.title('未使用聚类算法')
plt.legend(loc="upper right")
plt.show()
cluster_x_0 = []
cluster_x_1 = []
cluster_x_2 = []
cluster_y_0 = []
cluster_y_1 = []
cluster_y_2 = []
N = len(data)
data = np.array(data)
f = open("D:/anaconda4.3/spyder_work/center.txt")
center_x = []
center_y = []
for line in f.readlines():
lines = line.strip().split("\t")
if len(lines) == 2:
center_x.append(lines[0])
center_y.append(lines[1])
f.close()
for i in range(N):
if cluster[i]==0:
cluster_x_0.append(data[i, 0])
cluster_y_0.append(data[i, 1])
elif cluster[i]==1:
cluster_x_1.append(data[i, 0])
cluster_y_1.append(data[i, 1])
elif cluster[i]==2:
cluster_x_2.append(data[i, 0])
cluster_y_2.append(data[i, 1])
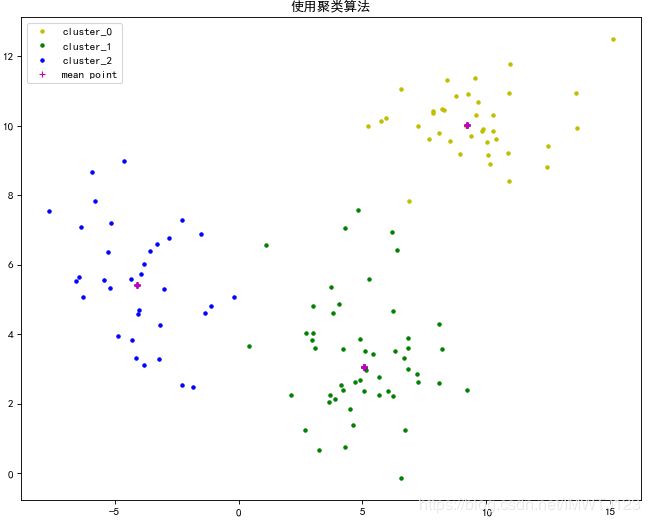
plt.figure(figsize=(10,8), dpi=80)
plt.plot(cluster_x_0, cluster_y_0,'y.',label="cluster_0")
plt.plot(cluster_x_1, cluster_y_1,'g.',label="cluster_1")
plt.plot(cluster_x_2, cluster_y_2,'b.',label="cluster_2")
plt.plot(center_x, center_y, '+m', label="mean point")
plt.title('使用聚类算法')
plt.legend(loc="best")
plt.show()
结果:
----------1.load data ------------
----------2.training ------------
iteration : 1
iteration : 2
iteration : 3
iteration : 4
iteration : 5
iteration : 6
iteration : 7
iteration : 8
iteration : 9
iteration : 10
iteration : 11
iteration : 12
iteration : 13
iteration : 14
iteration : 15
iteration : 16
iteration : 17
iteration : 18
iteration : 19
iteration : 20
iteration : 21
iteration : 22
iteration : 23
iteration : 24
iteration : 25
iteration : 26
iteration : 27
iteration : 28
----------3.1.save sub ------------
----------3.2.save center ------------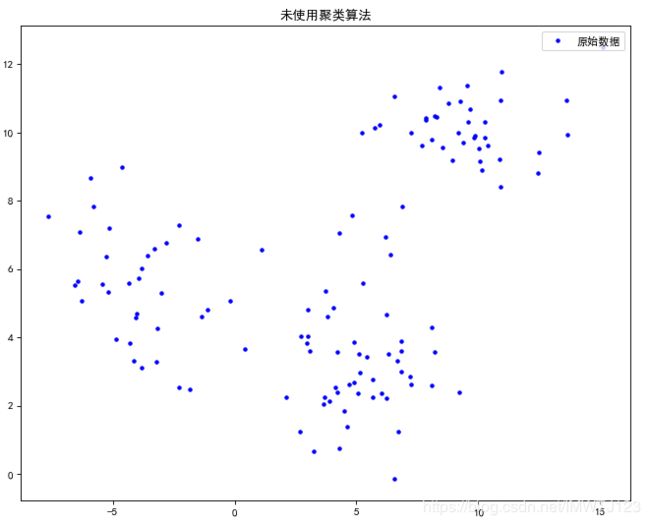
参考文献:
1.简单易学的机器学习算法——Mean Shift聚类算法
2.meanshift算法简介
3.周志华——机器学习
4.赵志勇——Python 机器学习算法