python网络爬虫批量爬取图片
注:1.由于python3把urllib和urllib2合并,这里把urllib2的功能用urllib.request代替。
2.爬取网站:http://www.win4000.com/meitu.html
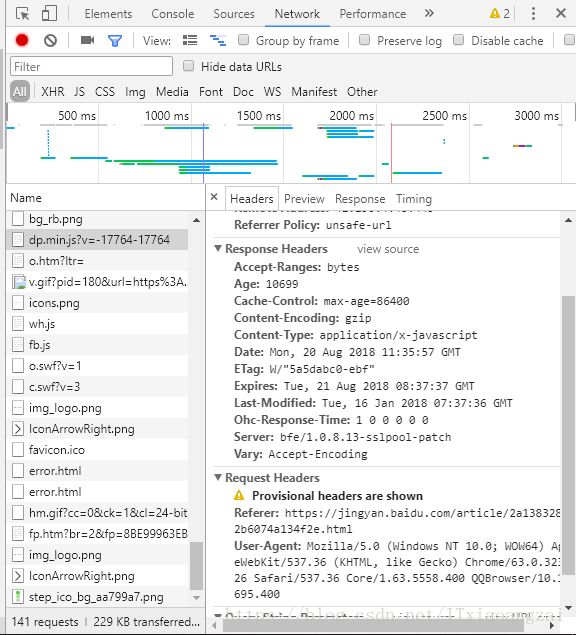
一:我们先要把网站上面的html请求数据拉取下来,看看请求返回的内容是什么。我们就需要用到网络请求,这里使用简单的urllib.request来实现,由于有的网站请求,可能设置了验证,我们需要模拟请求头,打开浏览器,f12查看network,可以看到我们网络请求的请求头,主要是User-Agent:
二:
找到User-Agent,将值,添加到我们的addheader,
并用get_html获取到网页的基础html,然后就是解析html:
def get_html(url):
request = urllib.request.Request(url)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5558.400 QQBrowser/10.1.1695.400')
html_content = urllib.request.urlopen(request).read()
return html_content
我们可以观察到,具体图片在img标签下面的src,

然后我们就是获取标签img,获取标签页面元素可以通过正则表达式和BeautifulSoup方便的类库来实现:
soup = BeautifulSoup(html,'html.parser')
x =1
for img in soup.find_all('img'):我们需要做下基本的判断,判断img是否包含src这个key,否则可能引起异常,可以截取相同的开头的判断字符:
if img.has_attr('src') and img['src'].startswith('http://'):
image_url = img['src']
print (image_url)使用简单的urllib.urlretrieve,实现保存到本地:
urllib.request.urlretrieve(image_url.strip(),'E:\\tupian\%s.jpg' % x)
x = x+1
三:全部代码如下:
import urllib
import urllib.request
from bs4 import BeautifulSoup
def get_html(url):
request = urllib.request.Request(url)
request.add_header('User-Agent','Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5558.400 QQBrowser/10.1.1695.400')
html_content = urllib.request.urlopen(request).read()
return html_content
if __name__ == '__main__':
html = get_html('http://www.win4000.com/meitu.html')
soup = BeautifulSoup(html,'html.parser')
x =1
for img in soup.find_all('img'):
if img.has_attr('src') and img['src'].startswith('http://'):
image_url = img['src']
print (image_url)
urllib.request.urlretrieve(image_url.strip(),'E:\\tupian\%s.jpg' % x)
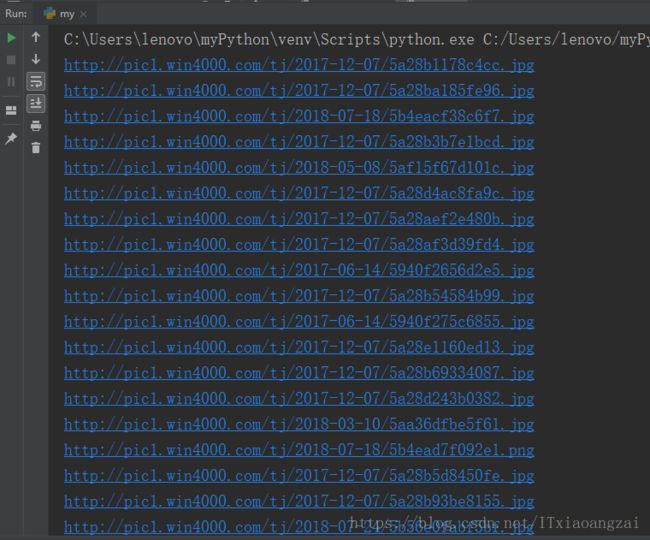
x = x+1结果如下:

大家可以参考一下,自己爬取一些喜欢的东西,这样学习才会由意思。