什么是统计套利
统计套利主要是在对历史数据进行统计分析的基础上,估计相关变量的概率分布,并结合基本面数据进行分析以指导套利交易,其主要分为配对/一揽子交易、多因素模型、均值回归策略、协整以及针对波动率与相关性的建模,与传统单边投资方式相比,统计套利多空双向持仓在处理大资金方面可以有效规避一部分风险,股指期货中常用的期现套利和跨期套利以及商品期货中跨品种套利都是常用的统计套利的例子,其中期限套利是强收敛既到期时期货和现货的价差必收敛,而其它策略则存在一些价差维持的风险。这里主要介绍一种最基本也是最常用的一种策略-配对交易。
与针对收益率建模的β中性策略不同,基于协整关系的配对交易直接针对股票价格序列建模,若两只或多只股票的股价存在长期稳定的线性关系,认为它们之间存在协整关系:
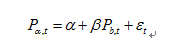
两只股票的价格序列存在协整关系一般包含两个条件,一是历史股价序列都是一阶单整向量,二是序列的某种线性组合是平稳的,故构建的线性方程的残差是平稳的。当某一对股票的价差既协整方程的残差偏离到一定程度时开仓,价差回归均衡时则获利了结,股价序列存在协整关系保证了长期价差将大概率回复至均值附近,协整策略的主要思路如下:
Ø 找出相关性好的若干对股票
Ø 对残差进行相应检验,首先要检验平稳性,其次检验残差的自相关性和异方差性,若存在,考虑采用ARMA或GARCH模型进行滤波,之后进行正态检验,若不满足正态性假定,可以考虑采用非参数方法来捕捉交易信号
Ø 找出每对股票的长期均衡关系(协整关系)
Ø 将残差分为可预测和不可预测的部分:![]() ,通常假定可预测部分为0,针对不可预测的部分进行建模,当
,通常假定可预测部分为0,针对不可预测的部分进行建模,当 ![]() 时表明A相对高估,卖空A,买入 倍的B,当残差回归正常或是反向时,
时表明A相对高估,卖空A,买入 倍的B,当残差回归正常或是反向时,![]() 时平仓,若残差继续扩大,
时平仓,若残差继续扩大, ![]() 使止损出局买进相对低估的股票,卖空相对高估的,等待价差回归均衡并获利了结。
使止损出局买进相对低估的股票,卖空相对高估的,等待价差回归均衡并获利了结。
Ø 根据策略的执行结果进行参数调优
统计套利策略在拥有低波动率、低风险、涨跌停保护以及对于价差(相对概念)而非价格的预测等优点的同时,也存在一些显著的缺点,其主要不足在于收益有限、存在套利机会较少(尤其是市场效率很高时),合约间“前者恒强,弱者恒弱的关系”会维持一定时间也带来了投资风险,除此之外,交割风险,极端行情风险也应该考虑在内。
关于统计套利,更多的可以参考浙商证券融资融券与统计套利系列研究报告,知乎上Lightwing的回答也为我们提供了一种新的思路,既利用统计模型来测算实价,而根据实价来判断交易的方向,长期的盈利空间则是一定的,为了便于大家更好地理解统计套利,我们在这里提供了一个基础的策略以供参考:
import pandas as pd
import numpy as np
# init方法是您的初始化逻辑。context对象可以在任何方法之间传递。
def init(context):
context.SWlist=['000806.SH','000807.SH','000808.SH']
context.industry_code=[]
context.moneyfund = 0
context.stock = ['000156.SZ','601928.SH']
#context.industry_code=pic_industry(context.SWlist,'close',10)
#print(context.industry_code)
task.monthly(rebalance,tradingday=1,time_rule=market_open(hour=0,minute=0))
task.daily(takeorder,time_rule=market_open(minute=0))
context.backdays = 20
# 日或分钟或实时数据更新,将会调用这个方法
def handle_data(context, data_dict):
pass
def takeorder(context,data_dict):
clear_stocklst(context.stock,data_dict)
'''
是否持有货币基金
if context.moneyfund == 0:
order_target_percent('511880.SH',0.4)
context.moneyfund = 1
'''
if not len(context.stock) == 2:
return
close_prices1 =get_history(context.backdays,'1d','close')[context.stock[0]].values
close_prices2 =get_history(context.backdays,'1d','close')[context.stock[1]].values
price_ratio = close_prices1/close_prices2
interval_high = np.mean(price_ratio) + np.std(price_ratio)
interval_mid = np.mean(price_ratio)
interval_low = np.mean(price_ratio) - np.std(price_ratio)
curr_priceratio = close_prices1[-1]/close_prices2[-1]
if not len(context.portfolio.positions.keys()) == 0: # 进入平仓流程
if (context.stock[0] in context.portfolio.positions) and(curr_priceratio>interval_mid-0.1*np.std(price_ratio)):
order_target_percent(context.stock[0],0)
#print (context.now,"卖掉了",context.stock[0])
if (context.stock[1] in context.portfolio.positions) and(curr_priceratio order_target_percent(context.stock[1],0) #print (context.now,"卖掉了",context.stock[1]) elif len(context.portfolio.positions.keys()) == 0: if curr_priceratio order_target_percent(context.stock[0],1) #print (context.now,"开始持仓",context.stock[0]) elif curr_priceratio > interval_high: order_target_percent(context.stock[1],1) #print (context.now,"开始持仓",context.stock[1]) return def get_history_panel(stock,days): panel = pd.DataFrame() field = ['close'] for char in field: stkinfo = get_history(days,'1d',char)[stock] df = pd.DataFrame({char:stkinfo.values},index=stkinfo.index) panel = panel.join(df,how='right') return panel def clear_stocklst(stocklist,data_dict): stkls=[] for stkdm in stocklist: if (not is_st(stkdm)) and (not data_dict[stkdm].sf==1) and (notis_delisting(stkdm)): #security=get_securities(stkdm) stkls.append(stkdm) #print (stkdm + " " +security.symbol ) return stkls def rebalance(context,data_dict): industry_list=[] for stock in context.portfolio.positions.keys(): #if not stock=='511880.SH': order_target_percent(stock, 0) context.industry_code=pic_industry(context.SWlist,'close',10) industry_list = get_index_constituents(context.industry_code) panel = pd.DataFrame() for stk in industry_list: stkprice = get_history(270,'1d','close')[stk].values df = pd.DataFrame({stk:stkprice}) panel = pd.concat([panel,df],axis=1) panelcorr = panel.corr().replace(1, 0) pair = panelcorr[panelcorr == panelcorr.max().max()].count() pair = pair[pair == 1].index.tolist() context.stock = pair print("您即将交易的两只股票为 %s 和 %s" %(pair[0],pair[1])) defpic_industry(constituents_list,field,days): multiseries = pd.DataFrame() for stk in constituents_list: stkinfo = get_history(days,'1d',field)[stk] df = pd.DataFrame({stk:stkinfo.values},index=stkinfo.index) multiseries = multiseries.join(df,how='right') multiseries.loc['Return'] = multiseries.apply(lambda x:(x[-1]-x[0])/x[0]) multiseriesT=multiseries.T multiseriesTsort=multiseriesT.sort(columns='Return',ascending=False) industry_code=multiseriesTsort.index[0] return industry_code 阅读更多: