【小白学AI】图像标注Image Caption - tensorflow_models/im2txt
Image Caption - im2txt 踩过的坑
- Image Caption - im2txt 踩过的坑
- 模型简介
- 工程实践
- MSCOCO数据准备
- Inception-v3模型下载
- 训练与监控
学习Image Caption的同学在开始实践项目时,可以在github上找到一大堆不同的Image Caption Project,有很多项目也都对应的有其实现版本的论文,都很好。但是有一点不太好,大家貌似都不太愿意上传自己的参数文件,可能因为训练时间长,过程艰辛,且文件较大。本文从Google-Tensorflow/models/im2txt开始简要总结一下在实现期间的各种坑。
模型简介
Google在im2txt项目中实现自家的论文《Show and Tell: A Neural Image Caption Generator》,采用经典CNN+RNN框架。其中CNN为Inception-v3结构,RNN为LSTM结构。具体结构如下
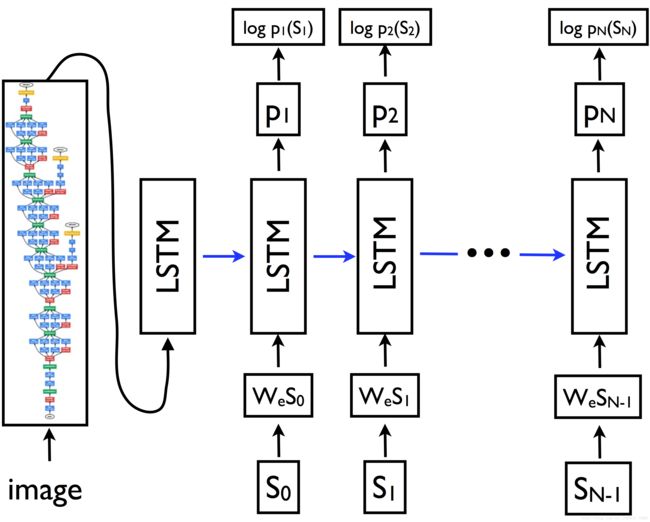
关于该框架的细节在这里不多说,可以去看论文,本文主要说一下在工程实践时应该注意的问题,毕竟纸上得来终觉浅,绝知此事要恭行。
工程实践
在实践Image Caption中,因为大多数工程都不会给出训练好的参数文件,Google在tensorflow/im2txt中也一样,所以需要我们自己进行训练。在训练过程中,重点其实在数据准备工作中,这一步完成了后面都会比较顺利。
实践过程中,可以结合本文和im2txt官方文档一起进行。整个训练在一块NVIDIA Tesla K20m上需要花费1-2周时间,其中1周可以达到效果,2周达到峰值效果。所以这个工程对硬件和时间的要求还是比较高的。
注意一下,以下所有工程必须建立在Python2.7,否则会发生编码错误。下面详细介绍实践过程。
MSCOCO数据准备
数据下载是一个漫长的任务,在工程的第一步我们应该先让数据下载起来,再去处理其他任务,达到效率最大化。
Image Caption一般都在MSCOCO数据集进行训练,所以首要任务是下载MSCOCO数据,一共大概20G。
MSCOCO对Image Caption任务来说包含三部分数据:
1)训练图像:train2014.zip
2)验证图像:val2014.zip
3)训练与验证图像对应的标注caption:captions_train-val2014.zip
这里有两种方法下载。
1. 无脑按照Google给出流程(适用于数据和预处理一起的情况)
# Location to save the MSCOCO data.
MSCOCO_DIR="${HOME}/im2txt/data/mscoco"
# Build the preprocessing script.
cd tensorflow-models/im2txt
bazel build //im2txt:download_and_preprocess_mscoco
# Run the preprocessing script.
bazel-bin/im2txt/download_and_preprocess_mscoco "${MSCOCO_DIR}"但是注意,如果出现编译不成功,并显示类似错误
ERROR: ...download_and_preprocess.sh is not executive...是因为被编译的文件属性为不可执行,所以我们需要将im2txt/im2txt/data/download_and_preproces_mscoco.sh文件属于设置为可执行:右键-properties-Permissions-Allow executing file as program。
2. 手动下载到电脑,再解压,再转换TFRecord格式(适用于数据和预处理分开的情况)
先下载:
Training Image URL: http://msvocds.blob.core.windows.net/coco2014/train2014.zip
Validation Image URL:
http://msvocds.blob.core.windows.net/coco2014/val2014.zip
Captions URL:
http://msvocds.blob.core.windows.net/annotations-1-0-3/captions_train-val2014.zip
可以用浏览器或者迅雷下载,不怕中间断网。
下载完成后,需要手动解压缩。同时考虑到Google工程中的路径问题,我们需要提前建立正确的文件路径,并解压缩到其中。
解压后数据集路径:
1)训练图像:Home/im2txt/data/mscoco/raw-data/train2014/COCO_train2014_000000000009.jpg……
2)验证图像:Home/im2txt/data/mscoco/raw-data/val2014/COCO_val2014_000000000042.jpg……
3)标注:Home/im2txt/data/mscoco/raw-data/annotations/captions_train2014.json + captions_val2014.json
解压好数据,并存放于正确路径后,要进行数据的转换,将其转换为TFRecord格式,并存放于Home/im2txt/data/mscoco中。这一步需要我们调用tensorflow-models/im2txt/im2txt/data工程中文件download_and_preprocess_mscoco.sh。
注意,这个im2txt文件夹和刚才数据解压的im2txt文件夹不是同一个文件夹。一个是数据文件夹(必须存放在Home/im2txt目录),一个是工程文件夹(可以存放在任何地方,比如Home/tensorflow-models/im2txt)。
继续TFRecord格式转换,这里有3中方法。
1 . 根据官方文档进行,利用bazel编译,再运行。(推荐)
# Location to save the MSCOCO data.
MSCOCO_DIR="${HOME}/im2txt/data/mscoco"
# Build the preprocessing script.
cd tensorflow-models/im2txt
bazel build //im2txt:download_and_preprocess_mscoco
# Run the preprocessing script.
bazel-bin/im2txt/download_and_preprocess_mscoco "${MSCOCO_DIR}"注意,如果出现编译不成功,并和上述1中出现的同样错误
ERROR: ...download_and_preprocess.sh is not executive...同样是因为被编译的文件属性为不可执行,所以我们需要将im2txt/im2txt/data/download_and_preproces_mscoco.sh文件属于设置为可执行:右键-properties-Permissions-Allow executing file as program。
2 . 其实也可以直接在terminal中运行download_and_preprocess_mscoco.sh文件。
cd tensorflow-models/im2txt/im2txt/data
>>> bash download_and_preprocess_mscoco.sh ${HOME}/im2txt/data/mscoco3 . 手动运行build_mscoco_data.py文件。
不过要更改其中的数据目录,具体为:将文件中102-112行替换为:
tf.flags.DEFINE_string("train_image_dir", "/home/server109/im2txt/data/mscoco/raw-data/train2014",
"Training image directory.")
tf.flags.DEFINE_string("val_image_dir", "/home/server109/im2txt/data/mscoco/raw-data/val2014",
"Validation image directory.")
tf.flags.DEFINE_string("train_captions_file", "/home/server109/im2txt/data/mscoco/raw-data/annotations/captions_train2014.json",
"Training captions JSON file.")
tf.flags.DEFINE_string("val_captions_file", "/home/server109/im2txt/data/mscoco/raw-data/annotations/captions_val2014.json",
"Validation captions JSON file.")
tf.flags.DEFINE_string("output_dir", "/home/server109/im2txt/data/mscoco", "Output data directory.")然后在终端进行运行。
注意,以上所有操作均需要在Python2.7中进行,Python3会出现编码问题,一定要注意,吃了大亏了,就算2to3.py也不行。
当TFRecord格式转换好了时,终端会打印如下信息:
2016-09-01 16:47:47.296630: Finished processing all 20267 image-caption pairs in data set 'test'.到这里,已经成功了一大半了。
Inception-v3模型下载
现在需要下载CNN框架,即Google自家的Inception-v3参数。
在终端输入如下即可。
# Location to save the Inception v3 checkpoint.
INCEPTION_DIR="${HOME}/im2txt/data"
mkdir -p ${INCEPTION_DIR}
wget "http://download.tensorflow.org/models/inception_v3_2016_08_28.tar.gz"
tar -xvf "inception_v3_2016_08_28.tar.gz" -C ${INCEPTION_DIR}
rm "inception_v3_2016_08_28.tar.gz"下载完后,在Home/im2txt/data中应该出现inception_v3.ckpt文件。
训练与监控
到这里基本上没什么坑了,按部就班的参照im2txt文档进行就好了,不多说了。
最后给一个开始训练模型的图,训练愉快,1-2周,醉了。
