chapter-15-深度学习的硬件与方法
目前CNN、RNN等神经网络已经有了长足的发展,但它由于结构太过复杂,导致体积、对算力的要求以及能耗都大幅提高。
为了解决这一问题,视频从以下四个方面讲解:
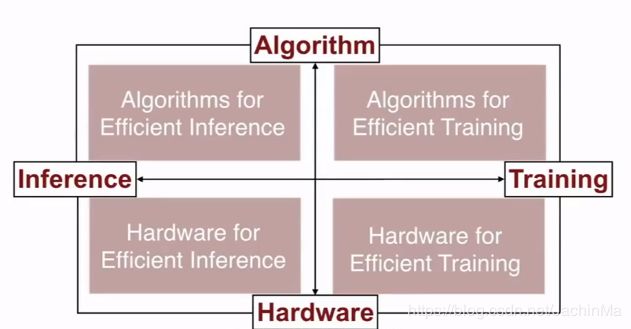
硬件基础
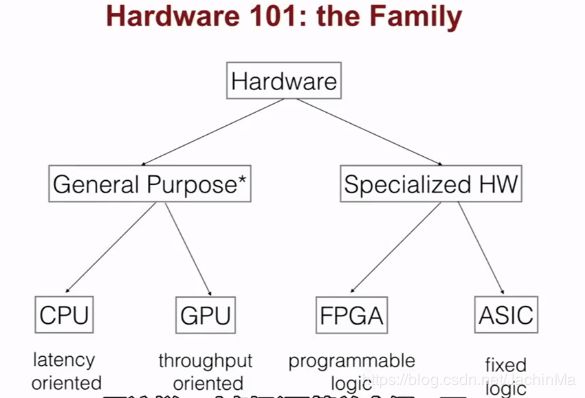
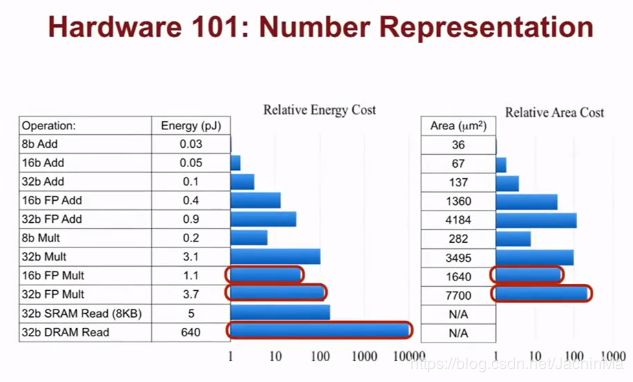
在开始之前,先简单了解下硬件的基础知识:

高效推断算法(Algorithms for Efficient Inference)
(关于推断的介绍,可见:https://www.zhihu.com/question/40090379/answer/571024848。
我的理解是,推断可以理解为应用。在训练好神经网络后,部署到设备上后,设备运行的过程,称为推断。)
一、剪枝(Pruning)
去除掉权重较小的权重,然后重新训练。如此循环直到准确率接近设定的红线。实验表明,这能够有效地减少计算量。
有趣的是,Nature的研究表明,人类也会经历类似的过程:婴儿的神经元数量大概是成年人的两倍,要多出约500亿个。
二、权值共享(Weight Sharing)
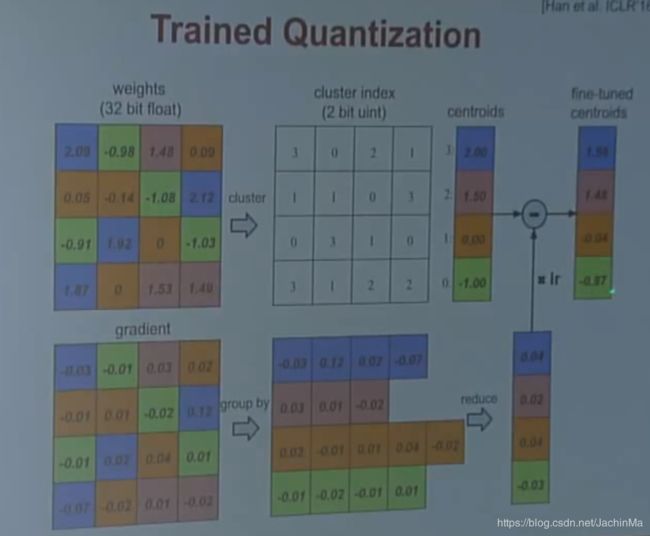
首先对原来的权重进行聚类,然后根据结果制定一个聚类矩阵以及各个聚类的聚类中心向量,其值为各聚类权重和。这样做的好处是,矩阵的单元数据就从32位变成了2位,节省了约16倍的存储空间。
然后在得到梯度矩阵后,根据权重矩阵的分类结果对其进行分类并类内加和得到梯度向量,然后将其乘以学习率,并用权重矩阵减去它,得到新的权重中心向量。
如果我们将这两种方法结合到一起,我们会发现,在不影响准确率的要求下,单个方法可以将模型压缩到10%,而两个方法同时用可以压缩到3%。
使用哈夫曼编码来用更短的数位表示更常出现的权重,用更长的数位来表示较少出现的权重。
在不影响准确率的要求下,这三种方法联合使用可以降低10到49倍的模型复杂度。
先前的思想都是优化现有神经网络,那为什么不在一开始就设计一个精简的神经网络呢?
基于这种思想,SqueezeNet诞生了:
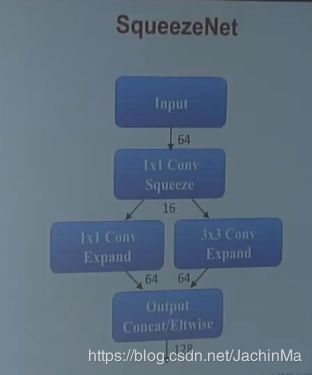
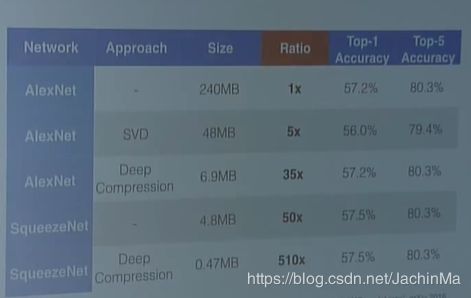
如果对其进行之前提到的压缩的话,效果会非常好:
三、量化(Quantization)
看视频的时候觉得讲得不清楚,就去查了一下,发现量化的思路还是挺多的(可能毕竟是17年的课程了),下面是我找到的比较全面的文章了。其实还是希望能找到篇这方面的综述看一看。
https://hey-yahei.cn/2019/01/23/MXNet-RT_Quantization/index.html
四、低轶近似(Low Rank Approximation)
实验证明,可以将一个卷积转换为两个卷积。前面一个卷积,后面一个1*1卷积。视频没有详说,我的理解是如果原来是3×3×3的卷积,现在就是一个3×3和一个1×1的卷积。
五、二/三元权重神经网络(Binary/ternary Net)
在训练时使用精确的权重,在推断时将权重更换为±1和0。
六、winograd变换(Winograd Transformation)
它的思路很简单:因为乘法是昂贵运算,加法是廉价运算,它的目标就是尽可能地使用加法来代替乘法运算。具体的做法可以看这篇文章:
https://blog.csdn.net/mydear_11000/article/details/83141688
*EIE(Efficient Inference Engine)
简单来说,它的思想是跳过稀疏数据的权重和激活值,以及使用近似的值来代替精确值。根据前面的研究,这对精确度几乎没有影响。
高效训练算法(Algorithms for Efficient Training)
一、并行化(Parallelization)
①数据并行:同时将两张图片读入模型。
②模型并行:将模型切割,分给不同的线程或处理器处理,但是要注意切割部分。
③超参数并行:在不同的机器上调整学习效率和权值衰减,以达到粗略的并行。
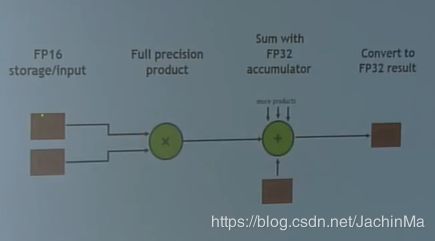
二、FP16和FP32的混合精度训练(Mixed Precision with FP16 and FP32)
三、模型精馏(Model Distillation)
使用一些不同的大型神经网络来教会小的神经网络学习,这有点像集成学习:


四、DSD :密-疏-密训练(Dense-Sparse-Dense Training)
DSD简单来说,就是在做了剪枝等简化处理后,再次添加神经元间的连线并训练。实验表明这能提升1%到4%的精确度。
高效训练硬件(Hardware for Efficient Training)
一、GPU
普通的GPU的优势就不提了,17年的时候英伟达发行了一款新的GPU称为Volta GPU,对深度学习来说,其尤为突出的特点是Tensor Core:

二、TPU(张量处理器,Tensor Processing Unit)
TPU是Google推出的专门用于加速TensorFlow运算的处理器,其选择了8bit的定点运算。
https://www.zhihu.com/question/46692744
后来Google又发行了云TPU,不仅支持推断,还支持训练。