教你如何从Google Map爬数据
笔者在实验室某个GIS项目中必须需要一定数据级的地图数据。在百般无奈下,笔者开始从Google Map爬数据。从Google Map上采集一定量的数据有作实验。
从Google Map爬数据的原理
Google Map所采用的是Mercator坐标系。何为Mercator坐标系?读者可以详见{链接}。在Google Map也是以金字塔模型的方式来组织切图文件的。至于,它的后端处理或者存储方式或者文件命名方式是怎么样,笔者不得而知。笔者只能从URL等方面进行分析,大概确定其地图文件的组织方式。在金字塔模型中,地图分成若干层,每一层数据的分辨率为上层的4倍(横向与纵向各2倍)。同时,每一层数据的分辨是极其巨大,而且成指数形式增加。如果一下子,将一层的数据作为一个文件返回给用户,无论从网络的传输能力、CPU处理能力还是内存的存储能力而言都是无法做到的。而且用户所观看的只是地图的某一层的某一块区域。因而,一般都会将地图数据进行切图,即进行切分,将地图数据切成分辨率相等的若干块。因而,我们可以得知,每一层数据集的文件数为上层的4倍。
笔者使用GoogleChrome来查看Google Map的Resources,图如下:
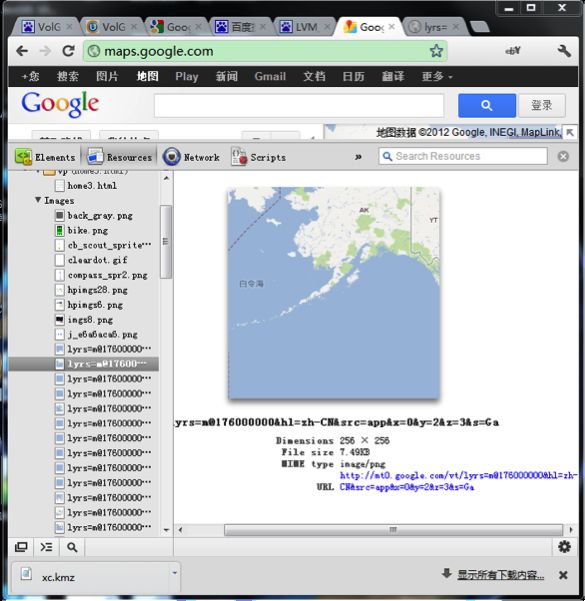
我们可以清楚地看到,在Google Map的地图文件并不是一次加载一整张,而是分成若干块,每一块的分辨为256*256。同时,我们也得到了每一块地图的地址,例如http://mt0.google.com/lyrs=m@176000000&hl=zh-CN&src=app&x=1&y=1&z=1&s=Ga.png。其中x、y是决定文件左上角坐标的参数,z为决定文件层次的参数。通过向Google Map服务器请求,我们可以得到第0层具有1块。从而第level层,具有2^level*2^level块,即x、y的取值范围为[0,2^level-1]。第level层每一块数据的横向经度差为360/2^level,纵向纬度差为180/2^level。
| x=0&y=0&z=0 |
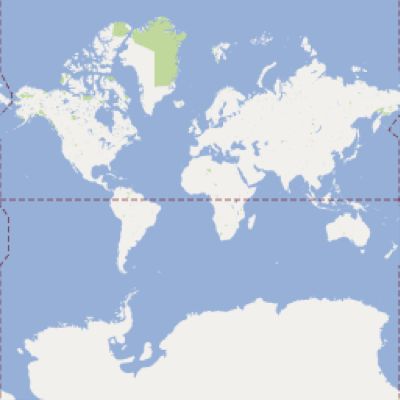 |
|
x=0&y=0&z=1
|
x=1&y=0&z=1 |
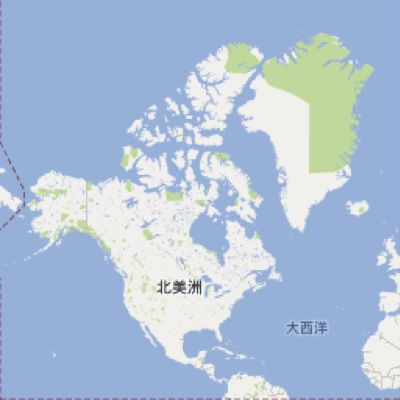 |
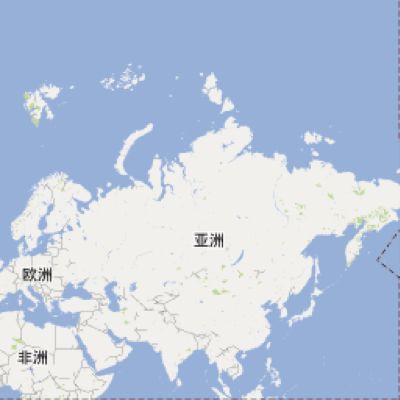 |
| x=0&y=1&z=1 | x=1&y=1&z=1 |
 |
 |
我们可以得知,x=xx,y=yy,z=zz的这块数据,所在的图层为zz层,该图层中每块数据的经度差为360/2^zz,纬度差为180/2^zz,左上角的经纬度为(360/2^zz*xx-180, 180/2^zz*yy-90)。同样,我们也可从一个数据块的左上角经纬度反推出这个文件在zz层的x与y。这也就是我们从Google Map爬数据的原理。
从Google Map爬数据有何难点?
1. 在国内由于政治等原因,连接Google服务器会有所中断。
2. Google的Web服务器,或者Google防火墙,会对某一台客户端的请求进行统计。如果一段时间内,请求数超过一定的值,此后的请求会直接被忽略。据说,当一天中,来自某一个IP的请求数超过7000个时,此后的请求后直接被忽略。
3. 单线程操作的效率太低,多线程情况下,效率会有很大提升。
4. Google服务器会对每个请求检查,判断是否来自浏览器还是来自爬虫。
5. 对于已下载的文件无须下载,即爬虫必须拥有“断点续传”的功能。不能由于网络的中断或者人为的中断,而导致之前的进度丢失。
对于这些难点有何解决方案
1. 对于第1点难点,我们可以使用国外的服务器作为我们的代理。这样,我们通过国外的服务器来请求Google Map。而对于大名鼎鼎的GFW而言,我们连接的并不是Google的服务器,而是其它的服务器。只要那台服务器没有被墙,我们就可以一直下载。
2. 对于第2个难点,我们依然可以使用代理。一旦,下载失败,这个代理ip可能已经被Google Map所阻拦,我们就需要更换代理。如果,代理的连接速度较慢,或者代理的下载文件时,超时较多,可能我们目前所使用的代理与我们的机器之间的网络连接状态不佳,或者代理服务负载较重。我们也需要更换代理。
3. 单线程操作的效率太低,我们需要使用多线程。但是,在使用多线程时,由于每一个文件的大小都很小,因而我们设计多线程机制时,每一个线程可以负责下载若干个文件。而不同的线程所下载的文件之间,没有交集。
4. 对于第4点,我们可以在建立http连接时,设置”User-Angent”,例如:
httpConnection.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");5. 对于第5点,我们可以在每下一个文件之间,事先判断文件是否已经完成。这有很多种解决方法,笔者在这里,采用file.exists()来进行判断。因为,对于下载一个文件而言,检查文件系统上某一个文件的代价会小很多。
改进与具体实现
1. 代理的获取
代理的获取有很多种方式。但如果一开始就配置所有的代理,那么,当这些代理都已经无法使用时,系统也将无法运行下去。当然,我们也不想那么麻烦地不断去更换代理。笔者是一个lazy man,所以还是由计算机自己来更换代理吧。笔者在此使用www.18daili.com。www.18daili.com会将其收集到代理已web的形式发布出来。因而,我们可以下载这张网页,对进行解析,便可以得最新可用的代理了。笔者在这里使用Dom4J来进行网页的解析。
2. 架构
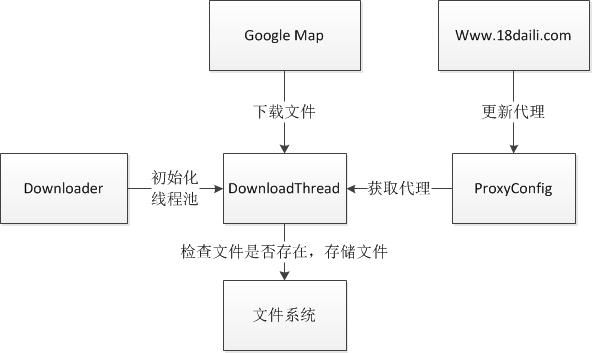
其中,分成三个模块:Downloader, DownloadThread, ProxyConfig。Downloader负责初化化线程池以存放DownloaderThread。每一个DownloadThread都会负责相应的若干个切图数据的下载。DownloadThread从ProxyConfig那里去获取代理,并从文件系统中检查某一个文件是否已经下载完成,并将下载完成文件按一定的规则存储到文件系统中去。ProxyConfig会从www.18daili.com更新现有的代理,在笔者的系统,每取1024次代理,ProxyCofig就会更新一次。
原码
Downloader:
package ??;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Downloader {
private static int minLevel = 0;
private static int maxLevel = 10;
private static String dir = "D:\\data\\google_v\\";
private static int maxRunningCount = 16;
private static int maxRequestLength = 100;
public static void download() {
ExecutorService pool = Executors.newFixedThreadPool(maxRunningCount);
for (int z = minLevel; z <= maxLevel; z++) {
int curDt = 0;
int requests[][] = null;
int maxD = (int) (Math.pow(2, z));
for (int x = 0; x < maxD; x++) {
for (int y = 0; y < maxD; y++) {
if (curDt % maxRequestLength == 0) {
String threadName = "dt_" + z + "_" + curDt;
DownloadThread dt = new DownloadThread(threadName, dir, requests);
pool.execute(dt);
curDt = 0;
requests = new int[maxRequestLength][3];
}
requests[curDt][0] = y;
requests[curDt][1] = x;
requests[curDt][2] = z;
curDt++;
}
}
DownloadThread dt = new DownloadThread("", dir, requests);
pool.execute(dt);
}
pool.shutdown();
}
public static void main(String[] strs) {
download();
}
}
DownloadThread:
package ??;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.InputStream;
import java.net.HttpURLConnection;
import java.net.Proxy;
import java.net.URL;
import java.text.SimpleDateFormat;
import java.util.Date;
public class DownloadThread extends Thread {
private static int BUFFER_SIZE = 1024 * 8;// 缓冲区大小
private static int MAX_TRY_DOWNLOAD_TIME = 128;
private static int CURRENT_PROXY = 0;
private String threadName = "";
private String dir;
// private int level;
private String tmpDir;
private Proxy proxy;
private int[][] requests;
private String ext = ".png";
private static SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
public DownloadThread(String threadName, String dir, int[][] requests) {
this.threadName = threadName;
this.dir = dir;
this.requests = requests;
}
@Override
public void run() {
Date now = new Date();
System.out.println(dateFormat.format(now) + "\t" + threadName + ":\t开始运行");
long t1 = System.currentTimeMillis();
long totalLength = download();
long t2 = System.currentTimeMillis();
double speed = (double) totalLength / (t2 - t1);
now = new Date();
if (speed < 0.5) {
CURRENT_PROXY++;
}
System.out.println(dateFormat.format(now) + "\t" + threadName + ":\t完成运行\t" + speed + "kB/s");
}
public long download() {
long totalLength = 0;
if (requests == null) {
return 0;
}
//System.out.println(requests.length);
for (int i = 0; i < requests.length; i++) {
int yy = requests[i][0];
int xx = requests[i][1];
int zz = requests[i][2];
int yyg = (int) (Math.pow(2, zz) - 1 - requests[i][0]);
this.tmpDir = dir + "/tmp/" + zz + "/";
File tmpDirFile = new File(tmpDir);
if (tmpDirFile.exists() == false) {
tmpDirFile.mkdirs();
}
String dirStr = dir + "/download/" + zz + "/" + yy + "/";
File fileDir = new File(dirStr);
if (fileDir.exists() == false) {
fileDir.mkdirs();
}
String fileStr = dirStr + yy + "_" + xx + ext;
File file = new File(fileStr);
// double lat1 = (yy) * dDegree - 90;
// double lat2 = (yy + 1) * dDegree - 90;
String url = "http://mt0.google.com/vt/lyrs=m@174000000&hl=zh-CN&src=app&x=" + xx + "&y=" + yyg + "&z=" + zz
+ "&s=";
// System.out.println(url);
if (file.exists() == false) {
String tmpFileStr = tmpDir + yy + "_" + xx + ext;
boolean r = saveToFile(url, tmpFileStr);
if (r == true) {
totalLength += cut(tmpFileStr, fileStr);
Date now = new Date();
System.out.println(dateFormat.format(now) + "\t" + threadName + ":\t" + zz + "\\" + yy + "_" + xx + ext + "\t"+proxy+"\t完成!");
} else {
Date now = new Date();
System.out.println(dateFormat.format(now) + "\t" + threadName + ":\t" + zz + "\\" + yy + "_" + xx + ext + "\t"+proxy+"\t失败!");
}
} else {
Date now = new Date();
System.out.println(dateFormat.format(now) + "\t" + threadName + ":\t" + zz + "\\" + yy + "_" + xx + ext + "已经下载!");
}
}
return totalLength;
}
public static long cut(String srcFileStr, String descFileStr) {
try {
// int bytesum = 0;
int byteread = 0;
File srcFile = new File(srcFileStr);
File descFile = new File(descFileStr);
if (srcFile.exists()) { // 文件存在时
InputStream is = new FileInputStream(srcFileStr); // 读入原文件
FileOutputStream os = new FileOutputStream(descFileStr);
byte[] buffer = new byte[1024 * 32];
// int length;
while ((byteread = is.read(buffer)) != -1) {
// bytesum += byteread; //字节数 文件大小
// System.out.println(bytesum);
os.write(buffer, 0, byteread);
}
is.close();
os.close();
}
srcFile.delete();
return descFile.length();
} catch (Exception e) {
System.out.println("复制单个文件操作出错");
e.printStackTrace();
}
return 0;
}
public boolean saveToFile(String destUrl, String fileName) {
int currentTime = 0;
while (currentTime < MAX_TRY_DOWNLOAD_TIME) {
try {
FileOutputStream fos = null;
BufferedInputStream bis = null;
HttpURLConnection httpConnection = null;
URL url = null;
byte[] buf = new byte[BUFFER_SIZE];
int size = 0;
// 建立链接
url = new URL(destUrl);
// url.openConnection(arg0)
currentTime++;
proxy = ProxyConfig.getProxy(CURRENT_PROXY);
//if (proxy != null) {
// System.out.println(threadName + ":\t切换代理\t" + proxy.address().toString());
//} else {
// System.out.println(threadName + ":\t使用本机IP");
//}
if (proxy == null) {
httpConnection = (HttpURLConnection) url.openConnection();
} else {
httpConnection = (HttpURLConnection) url.openConnection(proxy);
}
httpConnection.setRequestProperty("User-Agent", "Mozilla/4.0 (compatible; MSIE 5.0; Windows NT; DigExt)");
httpConnection.setConnectTimeout(60000);
httpConnection.setReadTimeout(60000);
// 连接指定的资源
httpConnection.connect();
// 获取网络输入流
bis = new BufferedInputStream(httpConnection.getInputStream());
// 建立文件
fos = new FileOutputStream(fileName);
// System.out.println("正在获取链接[" + destUrl + "]的内容;将其保存为文件[" +
// fileName + "]");
// 保存文件
while ((size = bis.read(buf)) != -1){
// System.out.println(size);
fos.write(buf, 0, size);
}
fos.close();
bis.close();
httpConnection.disconnect();
// currentTime = MAX_TRY_DOWNLOAD_TIME;
break;
} catch (Exception e) {
//e.printStackTrace();
CURRENT_PROXY++;
}
}
if (currentTime < MAX_TRY_DOWNLOAD_TIME) {
return true;
} else {
return false;
}
}
}
ProxyConfig:
package org.gfg.downloader.google.vctor;
import java.net.InetSocketAddress;
import java.net.Proxy;
import java.net.Proxy.Type;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class ProxyConfig {
private static List proxies;
private static int getTime = 0;
@SuppressWarnings("unchecked")
public static void inital() {
// if (proxies == null) {
proxies = null;
proxies = new ArrayList();
// } else {
// proxies.clear();
// }
try {
URL url = new URL("http://www.18daili.com/");
URLConnection urlConnection = url.openConnection();
urlConnection.setConnectTimeout(30000);
urlConnection.setReadTimeout(30000);
SAXReader reader = new SAXReader();
// System.out.println(url);
reader.setFeature("http://apache.org/xml/features/nonvalidating/load-external-dtd", false);
Document doc = reader.read(urlConnection.getInputStream());
if (doc != null) {
Element root = doc.getRootElement();
Element proxyListTable = getElementById(root, "proxyListTable");
// System.out.println(proxyListTable.asXML());
Iterator trs = proxyListTable.elementIterator();
trs.next();
while (trs.hasNext()) {
Element tr = trs.next();
Iterator tds = tr.elementIterator();
String ip = tds.next().getText();
String port = tds.next().getText();
// System.out.println(ip+":"+port);
Proxy proxy = new Proxy(Type.HTTP, new InetSocketAddress(ip, Integer.valueOf(port)));
proxies.add(proxy);
System.out.println("添加代理\t" + proxy);
}
}
} catch (Exception e) {
// e.printStackTrace();
}
}
private static Element getElementById(Element element, String id) {
Element needElement = null;
Iterator subElements = element.elementIterator();
while (subElements.hasNext()) {
Element subElement = subElements.next();
String getId = subElement.attributeValue("id");
if (getId != null && getId.equals(id)) {
needElement = subElement;
break;
} else {
needElement = getElementById(subElement, id);
if (needElement != null) {
break;
}
}
}
return needElement;
}
synchronized public static Proxy getProxy(int i) {
getTime++;
if (getTime % 1024 == 0 || proxies == null) {
inital();
getTime = 0;
System.out.println("重新生成代理列表!");
System.out.println("当前共有" + proxies.size() + "个代理!");
}
if (i % 8 == 0) {
return null;
}
int index = i % proxies.size();
index = Math.abs(index);
return proxies.get(index);
}
public static void main(String... str) {
inital();
}
}
发布与运行效果
本博客中所有的博文都为笔者(Jairus Chan)原创。
如需转载,请标明出处:http://blog.csdn.net/JairusChan。
如果您对本文有任何的意见与建议,请联系笔者(JairusChan)。