【Ctrl_I】团队日记6
1.模型改进
在上周对简单的模型和复杂模型进行了简单的初步对比后,本周工作内容为在复杂模型上进行结构调整,试图寻找到比简单模型更好的模型结构。
主要尝试的调整包括以下四个方面的内容:
不使用眼部图像,单独使用脸部图像和眼睛相对于的屏幕的信息构建网络
在复杂模型基础上,减少脸部特征的提取数量(一层卷积)
在复杂模型上减少脸部图像卷积后的全连接层(一层全连接)
在获取所有特征后只经过一层全连接输出
具体结果详见:
https://blog.csdn.net/AFXBR/article/details/89643998
2.手势功能
本周实现用户手势的语义理解,从而实现根据手势操作应用.
之前队友使用了Face++进行情绪分析,Face++同样也有手势识别,但是手势的种类有限,因此采用了百度的API.
http://ai.baidu.com/ 找到对应的模块 注册 获得各类Key以后即可使用.
具体的一些要求和Face++类似,无非是图片的一些要求,不再赘述.
2.1.Node.js SDK
整体包结构如下,主要用到的是核心是AipBodyAnalysis.其中的getGesture方法.
├── src
│ ├── auth //授权相关类
│ ├── http //Http通信相关类
│ ├── client //公用类
│ ├── util //工具类
│ └── const //常量类
├── AipBodyAnalysis.js //人体分析交互类
├── index.js //入口文件
└── package.json //npm包描述文件
Nodejs SDK代码已开源,github链接:https://github.com/Baidu-AIP/nodejs-sdk
2.2.连接使用
直接使用node开发包步骤如下:
1.在官方网站下载node SDK压缩包。
2.将下载的aip-node-sdk-version.zip解压后,复制到工程文件夹中。
3.进入目录,运行npm install安装sdk依赖库
4.把目录当做模块依赖
其中,version为版本号,添加完成后,用户就可以在工程中使用人体分析 Node SDK。
直接使用npm安装依赖:
npm install baidu-aip-sdk新建AipBodyAnalysisClient
AipBodyAnalysisClient是人体分析的node客户端,为使用人体分析的开发人员提供了一系列的交互方法
var AipBodyAnalysisClient = require("baidu-aip-sdk").bodyanalysis;
// 设置APPID/AK/SK
var APP_ID = "App ID";
var API_KEY = "Api Key";
var SECRET_KEY = "Secret Key";
// 新建一个对象
var client = new AipBodyAnalysisClient(APP_ID, API_KEY, SECRET_KEY);
此外模块提供了设置全局参数和全局请求拦截器的方法;
var HttpClient = require("baidu-aip-sdk").HttpClient;
// 设置request库的一些参数,例如代理服务地址,超时时间等
// request参数请参考 https://github.com/request/request#requestoptions-callback
HttpClient.setRequestOptions({timeout: 5000});
// 也可以设置拦截每次请求(设置拦截后,调用的setRequestOptions设置的参数将不生效),
// 可以按需修改request参数(无论是否修改,必须返回函数调用参数)
// request参数请参考 https://github.com/request/request#requestoptions-callback
HttpClient.setRequestInterceptor(function(requestOptions) {
// 查看参数
console.log(requestOptions)
// 修改参数
requestOptions.timeout = 5000;
// 返回参数
return requestOptions;
});
2.3.手势识别具体接口说明
识别图片中的手势类型,返回手势名称、手势矩形框、概率分数,可识别24种手势,支持动态手势识别,适用于手势特效、智能家居手势交互等场景;支持的24类手势列表:拳头、OK、祈祷、作揖、作别、单手比心、点赞、Diss、我爱你、掌心向上、双手比心(3种)、数字(9种)、Rock、竖中指。 注:
1)上述24类以外的其他手势会划分到other类。
2)除识别手势外,若图像中检测到人脸,会同时返回人脸框位置。
可识别的24种手势示意图如下,自拍场景、他人拍摄均适用。
| 序号 | 手势名称 | classname | 示例图 |
|---|---|---|---|
| 1 | 数字1(原食指) | One |  |
| 2 | 数字5(原掌心向前) | Five |  |
| 3 | 拳头 | Fist |  |
| 4 | OK | OK |  |
| 5 | 祈祷 | Prayer |  |
| 6 | 作揖 | Congratulation |  |
| 7 | 作别 | Honour |  |
| 8 | 单手比心 | Heart_single |  |
| 9 | 点赞 | Thumb_up |  |
| 10 | Diss | Thumb_down |  |
| 11 | Rock | ILY |  |
| 12 | 掌心向上 | Palm_up |  |
| 13 | 双手比心1 | Heart_1 |  |
| 14 | 双手比心2 | Heart_2 |  |
| 15 | 双手比心3 | Heart_3 |  |
| 16 | 数字2 | two |  |
| 17 | 数字3 | three |  |
| 18 | 数字4 | four |  |
| 19 | 数字6 | six |  |
| 20 | 数字7 | seven |  |
| 21 | 数字8 | eight |  |
| 22 | 数字9 | nine |  |
| 23 | Rock | Rock |  |
| 24 | 竖中指 | Insult |  |
手势识别具体调用如下:
var fs = require('fs');
var image = fs.readFileSync("assets/example.jpg").toString("base64");
// 调用手势识别
client.gesture(image).then(function(result) {
console.log(JSON.stringify(result));
}).catch(function(err) {
// 如果发生网络错误
console.log(err);
});
手势识别 请求参数详情
| 参数名称 | 是否必选 | 类型 | 说明 |
|---|---|---|---|
| image | 是 | string | 图像数据,base64编码,要求base64编码后大小不超过4M,最短边至少15px,最长边最大4096px,支持jpg/png/bmp格式 |
手势识别 返回数据参数详情
| 字段 | 是否必选 | 类型 | 说明 |
|---|---|---|---|
| result_num | 是 | int | 结果数量 |
| result | 是 | object[] | 检测到的目标,手势、人脸 |
| +classname | 否 | string | 目标所属类别,24种手势、other、face |
| +top | 否 | int | 目标框上坐标 |
| +width | 否 | int | 目标框的宽 |
| +left | 否 | int | 目标框最左坐标 |
| +height | 否 | int | 目标框的高 |
| +probability | 否 | float | 目标属于该类别的概率 |
| log_id | 是 | int64 | 唯一的log id,用于问题定位 |
3具体应用
3.1.创建应用
首先需要创建应用,填写相关信息之后确认,就可以获得API Key和secret Key,拥有它们才可以进行下一步的操作:
3.2.获取access_token
具体方式可以参考如下地址的API文档:
http://ai.baidu.com/docs#/Auth/top
这里似乎必须从服务端来获取,在HTML页面中直接发post请求就会报跨域的错误,这里我用bash来获取需要的access_token:
curl -i -k 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=【百度云应用的AK】&client_secret=【百度云应用的SK】'
从结果中可以看到获取到了这个access_token。
3.3.实现调用代码
这里只需要向接口发送access_token和base64编码的图片即可,从返回值中就可以拿到识别结果的json,结果json示例如下:
{
"log_id": 4466502370458351471,
"result_num": 2,
"result": [{
"probability": 0.9844077229499817,
"top": 20,
"height": 156,
"classname": "Face",
"width": 116,
"left": 173
},
{
"probability": 0.4679304957389832,
"top": 157,
"height": 106,
"classname": "Heart_2",
"width": 177,
"left": 183
}]
}
这里我封装了一个js文件gesture.js用于调用手势识别,识别之后打印出识别出的手势代号以及准确率:
const access_token = [自己的access_token];
window.gesture = {
dealGesture:function(json) {
for(var i = 0; i < json.result_num; i++) {
console.log(json.result[i].classname+' '+json.result[i].probability);
}
},
getGesture:function(base64Image) {
console.log(base64Image);
var image;
if(base64Image.substr(0,4) == 'data')
image = base64Image.substr(22, base64Image.length);
else
image = base64Image;
$.ajax({
type: "POST",
url: "https://aip.baidubce.com/rest/2.0/image-classify/v1/gesture",
contentType: "application/x-www-form-urlencoded",
dataType: "json", //表示返回值类型,不必须
data: {'access_token': access_token, 'image' : image},
success: gesture.dealGesture
});
}
}
其余具体内容详见:https://blog.csdn.net/zekdot/article/details/89725549
4.文章选择功能
从文章列表页面需要通过视线定位具体文章标题然后进一步进入具体的文章页面:

我们预计提供两种进入方式:
利用手势左划或者右划来进入、退出页面
全视线控制的进入、退出页面
第一种实现方式目前还在调试之中,所以这里我先使用第二种实现方式来实现文章的进入:
当视线停留在标题块上的时候,标题块开始从红色变为绿色。
如果在变为绿色之前移开了视线,则标题块变回原来的白色。
如果在标题块最终变为了绿色,则进入到标题对应的文章页面。
当视线没有停留在标题块上时,什么都不做。
该功能主要利用JavaScript的计时器来实现,通过计时器来实现颜色的渐变,等时间到了再载入具体的文章HTML页面.
使用情况如下:
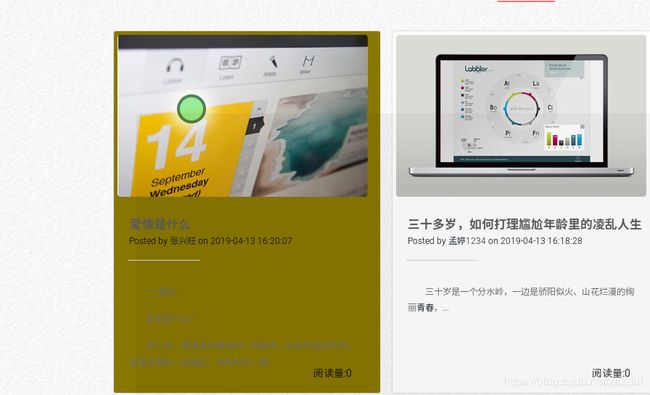
可见标题块正在逐渐变成绿色,当彻底变为绿色之后,会跳转到具体文章页面。
如图可见这里成功跳转到了具体文章页面。
代码详见https://blog.csdn.net/zekdot/article/details/89725549