MYSQL 笔记【回购数】
1、group by语句
select userid,date_format(paytime,'%Y-%m-%d')
from dash.order_info
where userid is not null
group by
userid,date_format(paytime,'%Y-%m-%d');group by A ,B;
a、select查询后面确定的字段,只能是group by后面出现的字段,和计数项。
b、gruop by A,B;
先按照A来做一次分组【相当于把原始数据分成n组,此时可以进行任何字段的count/sum动作,包含本身】,
在A分组的基础上,进行类别系划,再次分组,第二次分组,条件是B;
eg,a分组后,结果是独立用户数,b是把系划,独立用户数,哪几个月发生购买行为。
c、is not null 限制条件有is
*************************************************************************************************************************************
group by 可以对by后的分组字段进行计算count(),和excel的透视表一样,即使标签,又是计数项

可以来计算当月的复购率【第一行的count和sum等价】
select count(userid),count(if(a >1,1,null)) as 重复购买-- 此时等价sum(if(a>1,1,null)
from (
select userid,count(userid) as a -- count()可以用任何字段,因为在此时分组中都含有所有字段,
from
star.order_info
where paytype='已支付' and month(paytime)=3
group by userid) as t;![]()
**********************************************************************************************************************************
2、针对已经group by的数据,进行条件筛选having
select userid,count(userid)as s from dash.order_info
group by userid
having s >5;注意having 后面的条件是针对已经group by的结果,进行筛选的。
3、子查询
select count(distinct userid)
from dash.order_info
where month(paytime)=4 and
userid in
(select userid from dash.order_info where month(paytime)=3)
and paytype='已支付';注意where 条件1 and 字段 in (子查询);
标红的字段,对应的是整张表的字段,设定了一个条件是出现在子查询中。
where限定条件:所有数据都来自4月,其次,uderid还要来自3月。
求的是3月userid在4月依旧出现,的去重个数。
4、利用date_format()函数,时间粒度调整
获得年-月-日,或者 年-月
select userid,date_format(paytime,'%Y-%m')
from dash.order_info
where userid is not null
group by
userid,date_format(paytime,'%Y-%m');首先是date format在where语句就已经执行了转换操作,即已经将原本是具体日期的转化成dateformat规定的样式。但是行数和未作转换的行数相同。
eg:1 2018-08-09 结果 1 2018-08
1 2018-8-10 1 2018-08
并没有合并为 1 2018-08.
但是接下来的group by语句,是把where的结果作为源数据进行分组,也就是说此时的,时间已经被date format转后的时间样式了,group by 第一个条件是userid,如果没有第二个条件,那么就相当于把userid进行去重操作,和python的set()集合操作等价,后面跟第二个条件,也即是date format转换后的时间,我们这么理解,就是在去重操作后,又按照条件进行粒度细分,每个userid,细分为多少行有userid 对应的set(date format)去重后的个数确定,而非所有个数。
意义就是同一个用户在一个月买100次和买1次,效果相同,即按照独立购买用户计数,而非购买次数计数。
解释:
d=2017-8-9 10:14:02
date_format(d,'%Y-%m)=2017-08
date_format(d,'%Y-%m-%d)=2018-08-09
还可以指定哪一天**********************************
date_format(d,'%Y-%m-01)=2018-08-01
不可以是date_format(d,'%Y-%m-1)=2018-08-1,日期是双位数
5、left join 如果出现一对多,导致数量增加
select count(*) from
(select userid ,date_format(paytime,'%Y-%m-01') as d
from star.order_info
where userid is not null and paytype='已支付'
group by
userid,d
) as t1
left join
(select userid,date_format(paytime,'%Y-%m-01') as e
from star.order_info
where userid is not null and paytype='已支付'
group by
userid,e
) as t2
on t1.userid=t2.userid;我们把两张相同的表,进行left join ,条件是on t1.userid=t2.userid;
- 因为两张表相同,eg,001 2018-08-09 001 2018-08-09
- 001 2018-08-10 001 2018-08-10
left join 首先t1 的第一行001 2018-08-09,匹配t2 因为t2也有两条001,所以join后的表,t1的一行,匹配两行,t1的第二行,又匹配了两行。
- 结果是 001 2018-08-09 001 2018-08-09
- 001 2018-08-09 001 2018-08-10
- 001 2018-08-10 001 2018-08-09
- 001 2018-08-10 001 2018-08-09
需要on 在加一个限制条件,能后唯一确定匹配。
select count(*) from
(select userid ,date_format(paytime,'%Y-%m-01') as d
from star.order_info
where userid is not null and paytype='已支付'
group by
userid,d
) as t1
left join
(select userid,date_format(paytime,'%Y-%m-01') as e
from star.order_info
where userid is not null and paytype='已支付'
group by
userid,e
) as t2
on t1.userid=t2.userid and t1.d=date_sub(t2.e,interval 1 month);最后一行,on语句用and添加了限制条件,t1的日期,等于t2减一个月的日期,因为之前用date_format()处理过了,天都是01,所以就唯一限制死了,针对表1的某一行只能join表2的一行,或者没有join上【值为null】。
date_sub(日期1,interval 1 month/day/week)等等,做日期减法。
6、计数回购数,3月购买的用户在4月依旧购买。
select t1.d,count(t1.d)as 3月购买,count(t2.e)as 4月依旧购买 from
(select userid ,date_format(paytime,'%Y-%m-01') as d
from star.order_info
where userid is not null and paytype='已支付'
group by
userid,d
) as t1
left join
(select userid,date_format(paytime,'%Y-%m-01') as e
from star.order_info
where userid is not null and paytype='已支付'
group by
userid,e
) as t2
on t1.userid=t2.userid and t1.d =date_sub(t2.e,INTERVAL 1 month)
group by t1.d;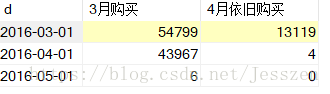
为什么count(t1.d)可以作为计算3月独立购买人数,那是因为我们left on左连接时已经,把userid和t1.d一一对应起来了【在每个月这个分类下】,而又group by t1.d,把日期给分组了,自然就对应每个月的独立购买人数。