LZ78编码Java实现
1965年苏联数学家Kolmogolov提出利用信源序列的结构特性来编码。而两位以色列研究者J.Ziv和A.Lempel独辟蹊径,完全脱离Huffman及算术编码的设计思路,创造出了一系列比Huffman编码更有效,比算术编码更快捷的通用压缩算法。将这些算法统称为LZ系列算法。
LZ系列算法用一种巧妙的方式将字典技术应用于通用数据压缩领域,而且,可以从理论上证明LZ系列算法同样可以逼近信息熵的极限。
/**The class is used to solve LZ78 Coding.
*tool:notepad++,jdk 1.8
*Date: 2018/6/7
*@author JF LIU
*@version 1.0
*说明:程序只能双字节输入变量(例如,a1,a2,b1等)。如果是二元编码,请用a1,a2等代替0,1。
*/
import java.util.Scanner;
import java.util.Vector;
import java.util.HashMap;
class RandomVariable {//信源
private float possibility = 0;//信源概率
private String randomVariableName = null;//信源字符
private String coding = null;//信源编码
RandomVariable() {
}
RandomVariable(String randomVariableName,float possibility,String coding) {
this.possibility = possibility;
this.randomVariableName = randomVariableName;
this.coding = coding;
}
public void setRandomVarible(String randomVariableName,float possibility,String coding) {
this.possibility = possibility;
this.randomVariableName = randomVariableName;
this.coding = coding;
}
public String getCoding() {
return coding;
}
public float getPossibility() {
return this.possibility;
}
public String getRandomVaribleName() {
return this.randomVariableName;
}
}
class CodingDictionary {//字典
private String segmentation = null;//段码
private int codingTemp = 0;//段号整型10进制表示
private String coding = null;//完整编码2进制表示
CodingDictionary() {
}
CodingDictionary(String segmentation, int codingTemp) {//输入序列使用
this.segmentation = segmentation;
this.codingTemp = codingTemp;
}
public void setCoding(String coding) {
this.coding = coding;
}
public void setCodingDictionary(String segmentation, String coding) {
this.segmentation = segmentation;
this.coding = coding;
}
public String getSegmentation() {
return segmentation;
}
public int getCodingTemp() {
return codingTemp;
}
public String getCoding() {
return coding;
}
public String toString() {
return segmentation+"\t\t"+coding;
}
}
public class LZCoding {
private static int theNumOfCharacterSet = 0;
private static int segLength = 0;//段长
private static int codingLength = 0;//单个信源位长
private static boolean flag = true; //输入是否合法
private static boolean flag2 = true;//是否输出熵,编码速率,编码效率
private static RandomVariable[] characterSetDictionary = null;//输入信源符号
private static float entropy = 0.f;//熵
private static float codeRate =1.f;//编码速率
private static float codeEfficiency =1.f;//编码效率
private static HashMap hashMap = new HashMap();//信源符号
private static Vector vector = new Vector();//输入序列
private static Vector vectorSeg = new Vector();//分段后的序列
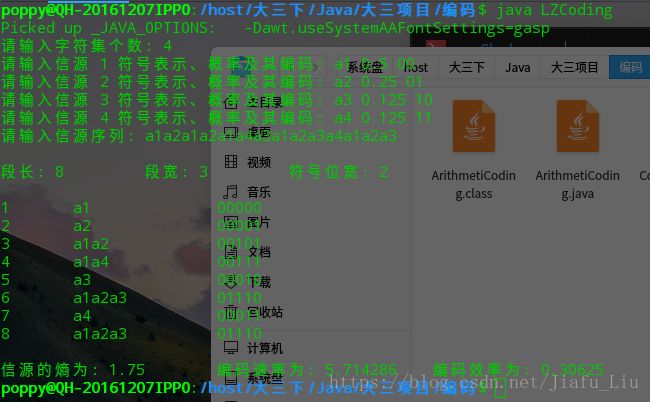
public static void main(String args[]) {
Scanner in = new Scanner(System.in);
while(flag) {
System.out.print("请输入字符集个数: ");
try {
theNumOfCharacterSet = in.nextInt();
if(theNumOfCharacterSet <= 0) {
System.out.println("输入值应该大约0!");
continue;
} else {
flag = false;
}
} catch(Exception e) {
System.out.println("输入含有非法字符!");
System.exit(0);
}
}
try {
inputCharacterSet(theNumOfCharacterSet);//信源字符集
} catch(Exception e) {
System.out.println("输入格式不正确!");
System.exit(0);
}
while(!inputMesSouSeqence());//输入序列
inputSegmentation();//分段
codeViaLZ();//编码
System.out.println();
for(int i =0;i//String str = String.format("%-20s", (vectorSeg.get(i)).toString());
System.out.println((i+1)+"\t"+(vectorSeg.get(i)).toString());
//System.out.println((i+1)+"\t"+str);
}
if(flag2) {
System.out.println();
System.out.println(showMessage());
}
}
public static void inputCharacterSet(int num) throws Exception {
characterSetDictionary = new RandomVariable[num];
Scanner in = new Scanner(System.in);
float sumPossible = 0.f;//检验概率空间是否封闭
for(int i=0; i < characterSetDictionary.length; i++)
characterSetDictionary[i]=new RandomVariable();
for(int i = 0; i < num; i++) {
System.out.print("请输入信源 " + (i+1) +" 符号表示、概率及其编码: ");
String str1 = in.next();
float possibility = in.nextFloat();
String str2 = in.next();
sumPossible += possibility;
try {
characterSetDictionary[i].setRandomVarible(str1,possibility,str2);
} catch(Exception e){
System.out.println("输入不合法或请按合理的参数顺序");
}
hashMap.put(characterSetDictionary[i].getRandomVaribleName(),characterSetDictionary[i]);
}
String str = characterSetDictionary[0].getRandomVaribleName();
for(int i = 0;i < theNumOfCharacterSet;i++) {
for(int j = i + 1;j < theNumOfCharacterSet;j++)
if(characterSetDictionary[i].getRandomVaribleName().equals(characterSetDictionary[j].getRandomVaribleName())) {
System.out.println("输入信源字符重复,无法编码,程序已退出!");
System.exit(0);
}
}
if(sumPossible != 1) {
System.out.println("概率空间不封闭,如果仅仅编码可以忽略");
flag2 = false;
return;
}
}
public static boolean inputMesSouSeqence() {
int index = 0;
String temp = "0.";
Scanner in = new Scanner(System.in);
System.out.print("请输入信源序列: ");
String str = in.next();
if(str.length()%2 != 0) {
System.out.print("请检查输入序列,重新输入: ");
return false;
}
String[] input = new String[str.length()/2];
for(int i = 0; i < str.length()/2; i++) {
input[i] = (str.charAt(2*i)+""+str.charAt(2*i+1)+"");
vector.add(input[i]);
}
System.out.println();
return true;
}
public static void inputSegmentation() {
String str = "";
boolean flag = false;
boolean flag2 = true;
int thefirstCom = 0;
int otherSeg = 0;//段号
for(int i = 0;i < vector.size(); i++) {
if(flag2)
str = (String)vector.get(i);
//遍历字典,分段
for(int j = 0; j < vectorSeg.size(); j++) {
if((vectorSeg.get(j).getSegmentation()).equals(str)) {
flag = true;
break;
}
}
if(flag) {
if(vector.size()-i<=1&&(str.length()<=2)){
if(hashMap.containsKey(str)) {////剩余的是单字母
vectorSeg.add(new CodingDictionary(str,thefirstCom));
} else{
System.out.println("输入非信源字母!");
}
break;
} else if(vector.size()-i<=1&&(str.length()>2)) {
//a1a2a1a2a1a2的形式,后面的a1a2与前面的a1a2重复
String temp = "";
String temp2 = str.charAt(str.length()-2)+""+str.charAt(str.length()-1);
for(int k = 0;k < str.length() - 2;k++) {
temp+=str.charAt(k);
}
for(int k2 = 0;k2 < vectorSeg.size(); k2++) {
if(vectorSeg.get(k2).getSegmentation().equals(temp)) {
otherSeg = k2 + 1;
break;
}
}
vectorSeg.add(new CodingDictionary(str,otherSeg));
}
if(vector.size()-i>1) {
str += (String)vector.get(i+1);
flag2 = false;
}
//System.out.println(str);
} else {//其它
if(hashMap.containsKey(str)) {////单字母或第一次出现译为000..
vectorSeg.add(new CodingDictionary(str,thefirstCom));
} else {
String temp = "";
String temp2 = str.charAt(str.length()-2)+""+str.charAt(str.length()-1);
for(int k = 0;k < str.length() - 2;k++) {
temp+=str.charAt(k);
}
for(int k2 = 0;k2 < vectorSeg.size(); k2++) {
if(vectorSeg.get(k2).getSegmentation().equals(temp)) {
otherSeg = k2 + 1;
break;
}
}
vectorSeg.add(new CodingDictionary(str,otherSeg));
flag2 = true;//添加元素后,可以迭代下一个元素
otherSeg = 0;
}
}
flag = false;
}
}
public static void codeViaLZ() {
codingLength = (int)(Math.ceil((Math.log(theNumOfCharacterSet)/Math.log(2))));
segLength = (int)(Math.ceil((Math.log(vectorSeg.size())/Math.log(2))));
System.out.println("段长: "+vectorSeg.size()+"\t\t段宽: "+segLength+"\t\t符号位宽: "+codingLength);
RandomVariable dir = null;
for(int j = 0; j < vectorSeg.size(); j++) {
String str = vectorSeg.get(j).getSegmentation();
String temp = str.charAt(str.length()-2)+""+str.charAt(str.length()-1);
dir = (RandomVariable)hashMap.get(temp);
int seq = vectorSeg.get(j).getCodingTemp();
String temp2 = null;
try {
temp2 = Integer.toString(seq,2) + dir.getCoding();
} catch(NullPointerException e) {
System.out.println("请输入合法的序列!");
return;
} catch(Exception e) {
System.out.println("输入异常!");
}
StringBuilder temp3 = new StringBuilder (temp2);
for(int k=0;k<(segLength+codingLength-temp2.length());k++) {
temp3.insert(0,"0");
}
vectorSeg.get(j).setCoding(temp3.toString());
}
}
public static void entropyFunction() {
for(int i = 0;i < theNumOfCharacterSet;i++) {
float possibility = characterSetDictionary[i].getPossibility();
entropy += possibility*(-1*Math.log(possibility)/Math.log(2));
}
}
public static void codeRate() {
codeRate = (float)((Math.log(theNumOfCharacterSet)/Math.log(2))*(vectorSeg.size()*(segLength+codingLength))/(float)vector.size());
}
public static void codeEfficiency() {
codeEfficiency = entropy / codeRate;
}
public static String showMessage() {//toString()
entropyFunction();
codeRate();
codeEfficiency();
return "信源的熵为: "+entropy+"\t编码速率为: "+codeRate+"\t编码效率为: "+codeEfficiency;
}
} 后记
LZ系列算法用一种巧妙的方式将字典技术应用于通用数据压缩领域,而且可以从理论上证明LZ系列算法同样可以逼近信息熵的极限。