阿里天池服装标签识别比赛新人赛练习经验心得 Tianchi FashionAI Attributes Recognition of Apparel
服装标签项目总结与心得
先放项目代码仓库:https://github.com/JosephPai/FashionAI-Attributes
强烈欢迎Star/Follow
关于代码或者数据集如果有任何问题,欢迎大家本博客或者github issues留言一起交流学习
任务描述

从属性标签知识体系中拿出了8种重要的属性维度对服装进行标签识别。
这些属性维度是:颈线设计、领子设计、脖颈设计、翻领设计、袖长、衣长、裙长、裤长。
具体示意,见下图:
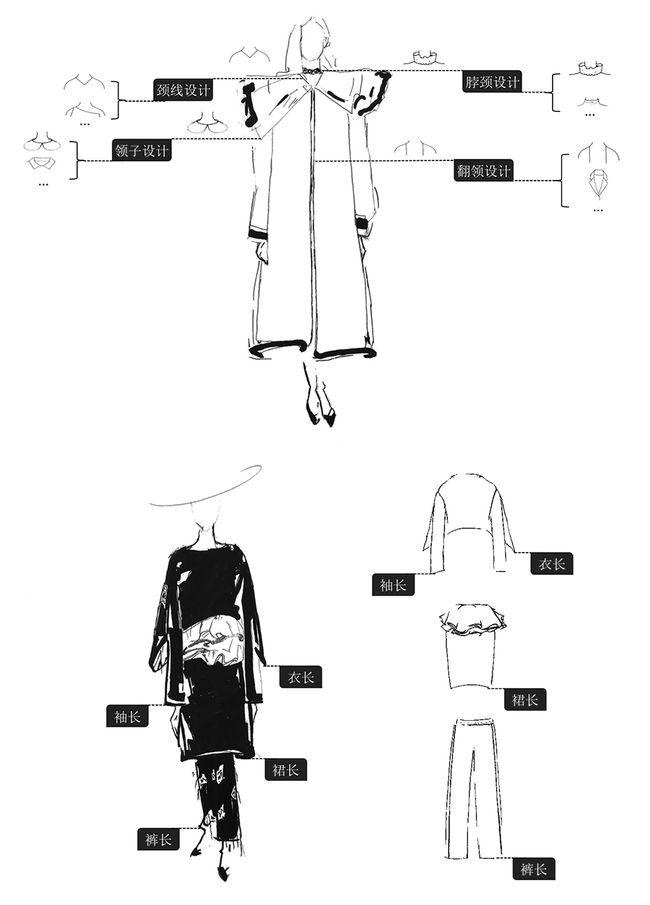
针对八个不同的属性维度,分别训练了各自的分类器。
经验总结
从零开始接触这个任务到现在,一些不成熟探索的经验
1.Pre-trained model
最开始接触这个任务的时候,用了一个ResNet101网络直接训练,一方面训练极慢,另一方面效果很差。
虽说训练集有两万多张图片好像看起来不是很少,但是对于CNN提取基础的features来说还不够,
更不用说和ImageNet weights相比。
导致模型完全overfit了训练集,训练集Acc达到95%+,测试集Acc约为67%。
使用Pre-trained weights后,训练过程收敛很快,效果也提升了很多。
准确率提升约’7-10%’
2. Data augmentation
数据增强对于提升模型的泛化能力有很强的作用。
但是在选择augment类型时候,要针对特定任务有取舍,选错了方法则适得其反。
比如属性标签任务中,可以大致分为设计和长度两大类(每一大类各包括四个属性维度)。
通过一些实验结果得出,比较适用于长度的增强方法:
- 颜色通道偏移 channel_shift
- 随机旋转 rotation
- 水平翻转 horizontal_flip
这应该是比较通用的几个增强方法了,适用于绝大部分分类任务
针对设计任务,在上面的基础上,还可以增加
- 错切,x坐标(或y)保持不变,而对应的y(或x)按比例发生平移 shear
- 水平/垂直随机放缩 zoom
可以想象,如果把垂直放缩方法应用到长度任务上,很可能会对模型造成负面影响
一些框架工具自带的增强类型有限,可以用python的imgaug库
准确率提升约’3-5%’
3. Backbone网络的选择
对于没有特殊需求的图片分类任务,个人觉得,
应该从AlexNet、VGG一路到ResNet再一路到NASNet进行排序,
根据自己的硬件条件选择可以使用的最强的网络
本次任务暂时选用DenseNet121作为统一的Backbone
4. 利用人的先验知识挖掘数据中的信息
例如长度任务,我们的知识告诉我们,这些长度是一个递增的关系。
我们可以基于此设计一个weighted loss function。
weight权重是基于类间距离的,预测结果和正确结果差别越大,惩罚应该越大。
准确率提升约’1-1.5%’
值得一提的是,这次的数据集中,标签中含有m(maybe)。
如果单纯根据y标签,进行one-hot编码,则损失了m信息。
利用m标签信息,编码为soft label(例如y 0.7, m 0.3)。使用此编码方式时需要注意数据中可能存在多个m。
准确率提升约’1.5-2.5%’
5. Padding
一开始忘了对图片进行padding操作,读入之后直接resize了,好在数据集的图片都比较友好
经丹阳哥提醒,进行了padding操作
准确率提升约’0.3%’(当数据集不够规范时候,是否进行padding操作对结果影响要大很多)
6. Image Size
图像的大小(分辨率)对于模型效果有很大影响,尤其在设计的维度
更大的图像包含更多的信息
例如在collar design任务中,将Image size从320提升至448,准确率提升约’3%’
7. Attention
好的模型应该是自适应attention的。
在神经网络学习过程中,应该能够自动关注到对分类结果有影响的区域。
当然外力的attention驱动还是可以使模型更专注的关注到该区域。
只不过,当Image size越大,网络越强,attention带来的提升会相对越小。
基于heat map的attention使准确率提升约’1-2%’
热度图heat map的获得一般参考Grad-CAM。
可视化热度图,对于理解模型原理,判断模型是否真正有效,
以及attribute localization and manipulation有很强的指导意义。
8. 调参
个人感受是,在模型基本固定的情况下,learning rate是最重要的参数。
一般先用Adam(1e-4)快速收敛
然后再用SGD(3e-5, 1e-5, 3e-6)等手动微调
并且不同的任务适应不同的参数的训练过程,私以为用jupyter notebook边看结果边手动调效果最好。
9. 多任务联合训练
根据结果看,长度维度的准确率普遍低于设计维度,
于是尝试用多任务联合训练的方式训练长度任务。
实现思路见https://gist.github.com/ypwhs/8e8ba38a313d76337ed4fc482afc9034
但是效果一般。
联合训练的优点在于数据量更大,一定程度上增加模型的泛化能力(提取features的丰富度)
缺点在于,上一条关于调参里面提到的,即使同属于长度维度,不同属性在分类时难易程度,
适应的参数变化也是不同的,对这样一个多任务的大的模型调参,对不同属性造成的影响不同,
出现了此消彼长的情况。
训练结果
| 属性 | Accuracy | Precision |
|---|---|---|
| collar design | 87.3% | 86.8% |
| lapel design | 90.1% | 89.6% |
| neck design | 88.6% | 88.7% |
| neckline design | 88.4% | 89.2% |
| pant length | 84.5% | 83.4% |
| skirt length | 81.3% | 81.7% |
| sleeve length | 80.8% | 79.4% |
| coat length | 78.2% | 78.3% |