ML Lecture 1: Regression - Case Study
ML Lecture 1: Regression - Case Study
- Youtube
- Bilibili
- 课件
回归的基本特征:输出一个数值
之前提到,机器学习要做的事情就是寻找函数,而回归要做的事情就是使我们所找的那个函数,其输出为数值型。或者说,如果我们找到的函数,它的输出是一个数值,这类型的任务就称为回归。举几个关于回归的例子:
- 股票市场的预测:找一个函数,其输入是过去股票市场的变动情况,输出是明天道琼工业指数的数值
- 驾驶无人车:找一个复杂函数,其输入是无人车上的各个感受器收集的数据,输出是方向盘角度
- Amazon的商品推荐/Youtube的视频推荐:找一个函数,其输入是用户A、商品B的各种特性,输出是用户A购买商品B的可能性

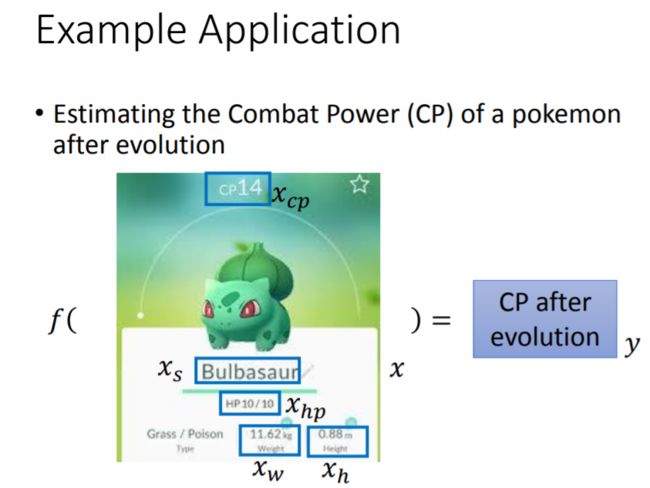
回归的应用实例:预测pokemon进化后的CP值(即战斗力)
回归任务:寻找一个函数,其输入为 x x x,代表pokemon进化前的各种指标值(例如:进化前的CP值 x c p x_{cp} xcp、所属物种 x s x_s xs、进化前的HP值 x h p x_{hp} xhp、重量 x w x_w xw、高度 x h x_h xh等),输出是进化后的CP值,用 y y y来表示。
如何找出这个函数?之前提到,机器学习的三个步骤分别是:
-
第一步,寻找一个模型(即一组函数/一个函数集)。假设我们认为进化后的CP值 y y y与进化前的CP值 x c p x_{cp} xcp有密切的关系,那么就可以将模型表示为:
y = b + w x c p y = b + w x_{cp} y=b+wxcp
并称其为线性模型(Linear Model),这个模型随着参数 b b b和 w w w取不同值,可以形成多个函数 f 1 , f 2 , f 3 . . . f_1,f_2,f_3... f1,f2,f3...。显然,该模型(函数集)中的函数并非全部是合理的,我们需要从中挑取有利于预测的函数。进一步地,考虑其他的各种指标,可以将模型推广表示为:
y = b + ∑ w i x i y = b + \sum w_i x_i y=b+∑wixi
其中, x i x_i xi泛指各种指标/特征(Feature),如 x c p , x h p , x w , x h x_{cp},x_{hp},x_w,x_h xcp,xhp,xw,xh等; w i w_i wi称为权重(Weight); b b b称为偏置(Bias)。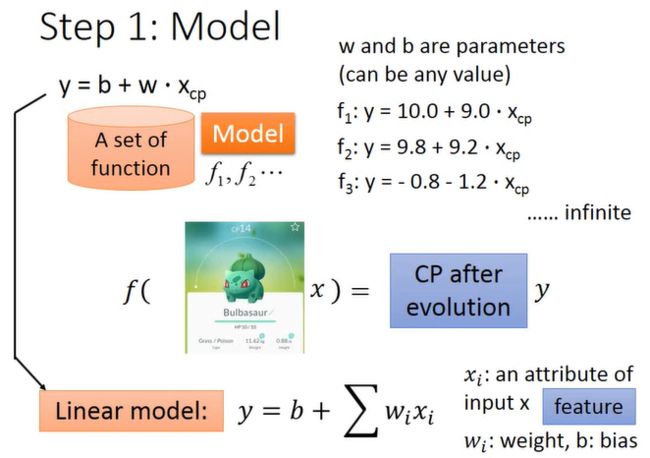
-
第二步,判断函数的优劣。为此,我们必须收集一些训练资料,其中包括不同pokemon的指标值和标签: ( x c p i , y ^ i ) (x_{cp}^i,\hat{y}^i) (xcpi,y^i)。其中 x c p i x_{cp}^i xcpi代表第 i i i只pokemon进化前的CP值, y ^ i \hat{y}^i y^i代表第 i i i只pokemon进化后的真实CP值。下图是收集到 10 10 10只pokemon的训练资料(蓝色点):

有了数据以后,就可以考察模型中的任意一个函数的优劣,这种“评价”是通过定义另一个函数,即
损失函数(Loss Function)来完成的,通常用 L L L表示。注意,损失函数是关于 f 1 , f 2 , f 3 . . . f_1,f_2,f_3... f1,f2,f3...的函数,即函数的函数。它的输入是:模型中的任意一个函数 f f f(由参数 b b b和 w w w决定);输出是:关于这个函数优劣的评价。
统计学习常用的损失函数有:0-1损失函数、平方损失函数、绝对损失函数、对数损失函数等,这里采用最常见的平方损失函数: L ( f ) = L ( w , b ) = ∑ n = 1 10 ( y ^ n − ( b + w x c p n ) ) 2 L(f) = L(w, b) = \sum_{n=1}^{10} ( \hat{y}^n - (b + wx_{cp}^n) )^2 L(f)=L(w,b)=n=1∑10(y^n−(b+wxcpn))2
-
第三步,根据定义的损失函数 L ( f ) L(f) L(f),按照 L ( f ) L(f) L(f)越小越好(即损失越少越好)的优化原则,从模型中挑选最佳函数 f ∗ f^* f∗,这个过程用公式表示为: f ∗ = a r g m i n f L ( f ) f^* = \mathop{argmin}_f L(f) f∗=argminfL(f)

寻找最佳函数 f ∗ f^* f∗其实就是寻找最佳参数 ( w ∗ , b ∗ ) (w^*,b^*) (w∗,b∗)。一个有效方法是
梯度下降法(Gradient Descent),只要保证损失函数 L ( f ) L(f) L(f)对参数 w w w和 b b b是可微分的,就可以用此方法求解最佳函数/参数: f ∗ = f ( w ∗ , b ∗ ) f^* = f(w^*,b^*) f∗=f(w∗,b∗)。
梯度下降法的原理
梯度下降法是一种一阶最优化算法。它是如何实现参数优化的呢?
【单个待优化参数】
考虑一个简单的情况:假设待求解的参数只有一个: w w w。则优化问题描述为:寻找 w w w的最优值,记为 w ∗ w^* w∗,使得损失函数 L ( w ) L(w) L(w)在 w = w ∗ w=w^* w=w∗处能够取得最小值 L ( w ∗ ) L(w^*) L(w∗)。
这里涉及到如何定义损失函数 L ( w ) L(w) L(w)。 L ( w ) L(w) L(w)可被定义为任何表达式,只要其满足:(1)对 w w w可导;(2)能够反映不同 w w w的优劣。定义好 L ( w ) L(w) L(w)后,我们就可以开始着手解决上述优化问题。最容易联想到的做法是暴力穷举所有 w w w,逐个代入 L ( w ) L(w) L(w),比较之后得到最小的 L ( w ) L(w) L(w),显然此举效率十分低下。
梯度下降法则可以克服上述缺陷:它不是穷举所有 w w w,而是按照如下步骤找到最优值:
-
首先随机选取一个初始值 w 0 w^0 w0,计算 L ( w ) L(w) L(w)在 w = w 0 w = w^0 w=w0处的导数: d L d w ∣ w = w 0 \frac{dL}{dw} |_{w = w^0} dwdL∣w=w0,得到的数值即损失函数的曲线在 w 0 w^0 w0处的切线斜率
-
根据导数值 d L d w ∣ w = w 0 \frac{dL}{dw} |_{w = w^0} dwdL∣w=w0的正负,调整 w w w的值:
若 d L d w ∣ w = w 0 < 0 \frac{dL}{dw} |_{w = w^0} < 0 dwdL∣w=w0<0,说明 L ( w ) L(w) L(w)的曲线目前正处于下降状态,为了抵达曲线的最低谷,应该朝着坐标轴正向行进, w 0 w^0 w0应该增大
若 d L d w ∣ w = w 0 > 0 \frac{dL}{dw} |_{w = w^0} > 0 dwdL∣w=w0>0,说明 L ( w ) L(w) L(w)的曲线目前正处于上升状态,为了抵达曲线的最低谷,应该朝着坐标轴反向行进, w 0 w^0 w0应该减小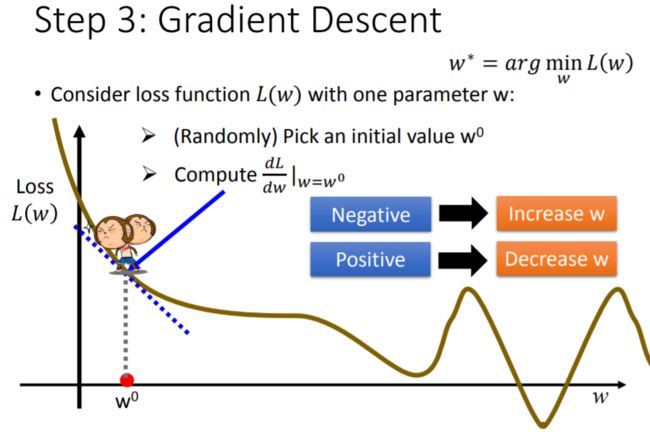
其中, w 0 w^0 w0增大或减小的幅度取决于两件事:
① 当前导数值 d L d w ∣ w = w 0 \frac{dL}{dw} |_{w = w^0} dwdL∣w=w0的大小。它代表了损失函数的曲线当前正处于陡峭,还是平坦状态。显然,在曲线越陡峭的位置, w 0 w^0 w0稍微增大或减小一点,就会使损失函数发生很大的变动
②
学习率(Learning Rate)η \eta η的大小。 η \eta η是自行设定的常数项,它决定了参数学习速度有多快。 η \eta η越大,则 w 0 w^0 w0下一步要跨越的距离就越大(即参数更新的幅度大),意味着参数的学习效率比较高(但学习率设置过高也有问题)
-
由于导数值 d L d w ∣ w = w 0 \frac{dL}{dw} |_{w = w^0} dwdL∣w=w0的正负与我们希望 w 0 w^0 w0移动的方向恰好相反,因此在更新 w 0 w^0 w0时,应该加上负号,即 w 1 = w 0 − η d L d w ∣ w = w 0 w^1 = w^0-\eta \frac{dL}{dw} |_{w = w^0} w1=w0−ηdwdL∣w=w0。按照这样的规则,从随机初始值 w 0 w^0 w0开始不断更新: w 0 → w 1 → w 2 . . . w^0 \to w^1 \to w^2... w0→w1→w2...。
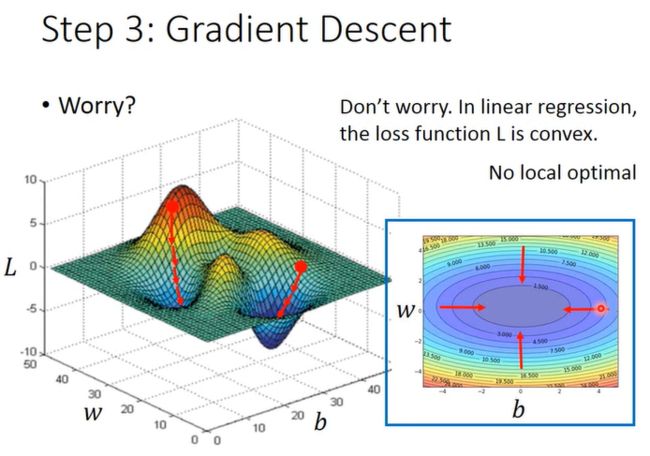
在针对线性回归的迭代过程中,参数的更新使得损失函数不断下降,最终逼近最优参数 w ∗ w^* w∗,最终损失函数取得最小值。梯度下降法之所以能用来解决线性回归任务的参数求解,是因为这里的损失函数 L L L是一个凸函数(Convex Function),其中不存在局部最小值的问题,最后只有一个全局最小值,所得即所求。
事实上,在其他参数求解问题中,会出现这种情况:虽然每一次参数更新,损失函数也在不断下降,但最后抵达的最小值,只是一个局部最小值(Local Minima),如下图的 w T w^T wT。在 w T w^T wT处,导数值 d L d w ∣ w = w T = 0 \frac{dL}{dw} |_{w = w^T} =0 dwdL∣w=wT=0,参数会停止更新,损失函数看似到达最低点,其实在整个损失函数曲线中还存在着一个更低点,即全局最小值(Global Minima),而全局最小值才是我们的最终目标。

【两个待优化参数】
同理,当有两个参数 ( w , b ) (w,b) (w,b)时,首先定义一个关于 ( w , b ) (w,b) (w,b)的损失函数 L ( w , b ) L(w,b) L(w,b),按照如下步骤找到最优值:
-
随机选取一组初始参数 ( w 0 , b 0 ) (w^0,b^0) (w0,b0),分别计算 L ( w , b ) L(w,b) L(w,b)在点 ( w = w 0 , b = b 0 ) (w = w^0,b = b^0) (w=w0,b=b0)处,对 w w w和 b b b的偏导数: ∂ L ∂ w ∣ w = w 0 , b = b 0 \frac{\partial L}{\partial w} |_{w = w^0, b = b^0} ∂w∂L∣w=w0,b=b0 ∂ L ∂ b ∣ w = w 0 , b = b 0 \frac{\partial L}{\partial b} |_{w = w^0, b = b^0} ∂b∂L∣w=w0,b=b0
-
根据偏导数值和学习率,分别更新 w w w和 b b b的值:
w 1 = w 0 − η ∂ L ∂ w ∣ w = w 0 , b = b 0 w^1 = w^0 - \eta \frac{\partial L}{\partial w} |_{w = w^0, b = b^0} w1=w0−η∂w∂L∣w=w0,b=b0, b 1 = b 0 − η ∂ L ∂ b ∣ w = w 0 , b = b 0 b^1 = b^0 -\eta \frac{\partial L}{\partial b} |_{w = w^0, b = b^0} b1=b0−η∂b∂L∣w=w0,b=b0
w 2 = w 1 − η ∂ L ∂ w ∣ w = w 1 , b = b 1 w^2 = w^1 - \eta \frac{\partial L}{\partial w} |_{w = w^1, b = b^1} w2=w1−η∂w∂L∣w=w1,b=b1, b 2 = b 1 − η ∂ L ∂ b ∣ w = w 1 , b = b 1 b^2 = b^1 -\eta \frac{\partial L}{\partial b} |_{w = w^1, b = b^1} b2=b1−η∂b∂L∣w=w1,b=b1
…
直到最后偏导数等于 0 0 0,参数停止更新,此时的参数 ( w ∗ , b ∗ ) (w^*,b^*) (w∗,b∗)能够使损失函数 L ( w , b ) L(w,b) L(w,b)最小
梯度下降中的梯度,就是指损失函数 L L L对各个参数求偏导后,所组成的向量:
∇ L = [ ∂ L ∂ w ∂ L ∂ b ] \nabla L = \left[ \begin{matrix} \frac{\partial L}{\partial w} \\ \frac{\partial L}{\partial b} \\ \end{matrix} \right] ∇L=[∂w∂L∂b∂L]

上面两个参数的迭代过程,可以通过下图直观表达:纵轴为参数 w w w的取值,横轴为参数 b b b的取值,则图中每一个点分别代表不同的 ( w , b ) (w,b) (w,b)。
图中不同的颜色区域分别对应着损失函数的大小。越往中间(紫色部分),损失函数的值越小。 ( w , b ) (w,b) (w,b)的每一次更新,就是沿着等高线的法线方向,往中间区域移动。

【多个待优化参数】
同样地,可以推广到用梯度下降法求解多个参数的情形。假设 θ \theta θ表示一个参数的集合,运用梯度下降法求解时,我们希望参数的每一次更新,都能使损失函数再降低一点: θ 0 → θ 1 → θ 2 \theta^0 \to \theta^1 \to \theta^2 θ0→θ1→θ2 L ( θ 0 ) > L ( θ 1 ) > L ( θ 2 ) L(\theta^0) > L(\theta^1) > L(\theta^2) L(θ0)>L(θ1)>L(θ2)

但正如前面所说,梯度下降法也有缺陷:
-
在非线性模型中,选取不同的初始参数,最后可能抵达不同的局部最小值
-
在全局/局部最小值处,参数不再更新,是因为这里的导数值为 0 0 0。但其实在整个
误差曲面(Error Surface)上,导数值为 0 0 0的点不止全局最小值和局部最小值,也有可能是鞍点(Saddle Point)。鞍点的位置如下图浅蓝色框所示,在该点处,导数值为 0 0 0却并非最小值点 -
实际更新参数时,我们往往不会真的等到导数值为 0 0 0,才停止参数的更新,而是会设定一个
阈值(Threshold),当导数值小于此阈值时,我们就认为损失函数已经差不多接近最小值,参数也差不多接近最优,并停止迭代。
但这样的做法会带来问题:绿色框对应的点,其实离全局最小值、局部最小值、鞍点还很远,但由于处在非常平坦的地方,其计算出来的导数值特别小,每一次参数更新都只前进一点点,若此时误以为已经接近目标而停止迭代,那么求出来的参数并不能使损失函数最小
必须强调的是,在线性回归模型中,由于损失函数是一个凸函数,类似于碗的形状,不存在多个最小值,因此从任何一个初始位置出发,最后都会回到唯一的最低点,所以能够克服上述缺陷。
模型选择与评估
除了用梯度下降法求解最优参数,机器学习的重要环节还包括模型选择与评估。
选择模型时,我们通常是基于先验知识进行一些假设,根据假设设计模型结构,通过考察模型的拟合效果,判断所选模型是否合理。
根据上述思路:进行假设 → \to →设计模型 → \to →考察拟合效果,以 10 10 10只训练集pokemon、 10 10 10只测试集pokemon为例,拟合了如下七个模型(表格总结):
| 进行假设 | 设计模型 | 考察拟合效果(平均误差) |
|---|---|---|
| y y y与 x c p x_{cp} xcp有关 | y = b + w x c p y = b + w x_{cp} y=b+wxcp | 训练集 31.9 31.9 31.9,测试集 35.0 35.0 35.0 |
| y y y与 x c p x_{cp} xcp、 x c p 2 x_{cp}^2 xcp2有关 | y = b + w 1 x c p + w 2 ( x c p ) 2 y = b + w_1 x_{cp} + w_2 (x_{cp})^2 y=b+w1xcp+w2(xcp)2 | 训练集 15.4 15.4 15.4,测试集 18.4 18.4 18.4 |
| y y y与 x c p x_{cp} xcp、 x c p 2 x_{cp}^2 xcp2、 x c p 3 x_{cp}^3 xcp3有关 | y = b + w 1 x c p + w 2 ( x c p ) 2 + w 3 ( x c p ) 3 y = b + w_1 x_{cp} + w_2 (x_{cp})^2 + w_3 (x_{cp})^3 y=b+w1xcp+w2(xcp)2+w3(xcp)3 | 训练集 15.3 15.3 15.3,测试集 18.1 18.1 18.1 |
| y y y与 x c p x_{cp} xcp、 x c p 2 x_{cp}^2 xcp2、 x c p 3 x_{cp}^3 xcp3、 x c p 4 x_{cp}^4 xcp4有关 | y = b + w 1 x c p + w 2 ( x c p ) 2 + w 3 ( x c p ) 3 + w 4 ( x c p ) 4 y = b + w_1 x_{cp} + w_2 (x_{cp})^2 + w_3 (x_{cp})^3 + w_4 (x_{cp})^4 y=b+w1xcp+w2(xcp)2+w3(xcp)3+w4(xcp)4 | 训练集 14.9 14.9 14.9,测试集 28.8 28.8 28.8 |
| y y y与 x c p x_{cp} xcp、 x c p 2 x_{cp}^2 xcp2、 x c p 3 x_{cp}^3 xcp3、 x c p 4 x_{cp}^4 xcp4、 x c p 5 x_{cp}^5 xcp5有关 | y = b + w 1 x c p + w 2 ( x c p ) 2 + w 3 ( x c p ) 3 + w 4 ( x c p ) 4 + w 5 ( x c p ) 5 y = b + w_1 x_{cp} + w_2 (x_{cp})^2 + w_3 (x_{cp})^3 + w_4 (x_{cp})^4 + w_5 (x_{cp})^5 y=b+w1xcp+w2(xcp)2+w3(xcp)3+w4(xcp)4+w5(xcp)5 | 训练集 12.8 12.8 12.8,测试集 232.1 232.1 232.1 |
| y y y与 x c p x_{cp} xcp、 x s x_s xs有关 | y = { b 1 + w 1 ⋅ x c p , x s = P i d g e y b 2 + w 2 ⋅ x c p , x s = W e e d l e b 3 + w 3 ⋅ x c p , x s = C a t e r p i e b 4 + w 4 ⋅ x c p , x s = E e v e e y = \left \{ \begin{aligned} b_1+ w_1 \cdot x_{cp} &,x_s = Pidgey \\ b_2+ w_2 \cdot x_{cp} &,x_s = Weedle \\ b_3+ w_3 \cdot x_{cp} &,x_s = Caterpie \\ b_4+ w_4 \cdot x_{cp} &,x_s = Eevee \end{aligned} \right. y=⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧b1+w1⋅xcpb2+w2⋅xcpb3+w3⋅xcpb4+w4⋅xcp,xs=Pidgey,xs=Weedle,xs=Caterpie,xs=Eevee | 训练集 3.8 3.8 3.8,测试集 14.3 14.3 14.3 |
| y y y与 x s x_s xs、 x c p x_{cp} xcp、 x c p 2 x_{cp}^2 xcp2、 x h p x_{hp} xhp、 x h p 2 x_{hp}^2 xhp2、 x h x_{h} xh、 x h 2 x_{h}^2 xh2、 x w x_{w} xw、 x w 2 x_{w}^2 xw2有关 | y ′ = { b 1 + w 1 ⋅ x c p + w 5 ⋅ ( x c p ) 2 , x s = P i d g e y b 2 + w 2 ⋅ x c p + w 6 ⋅ ( x c p ) 2 , x s = W e e d l e b 3 + w 3 ⋅ x c p + w 7 ⋅ ( x c p ) 2 , x s = C a t e r p i e b 4 + w 4 ⋅ x c p + w 8 ⋅ ( x c p ) 2 , x s = E e v e e y^{'} = \left \{ \begin{aligned} b_1+ w_1 \cdot x_{cp} + w_5 \cdot (x_{cp})^2 &,x_s = Pidgey \\ b_2+ w_2 \cdot x_{cp} + w_6 \cdot (x_{cp})^2 &,x_s = Weedle \\ b_3+ w_3 \cdot x_{cp} + w_7 \cdot (x_{cp})^2 &,x_s = Caterpie \\ b_4+ w_4 \cdot x_{cp} + w_8 \cdot (x_{cp})^2 &,x_s = Eevee \end{aligned} \right. y′=⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧b1+w1⋅xcp+w5⋅(xcp)2b2+w2⋅xcp+w6⋅(xcp)2b3+w3⋅xcp+w7⋅(xcp)2b4+w4⋅xcp+w8⋅(xcp)2,xs=Pidgey,xs=Weedle,xs=Caterpie,xs=Eevee y = y ′ + w 9 ⋅ x h p + w 10 ⋅ ( x h p ) 2 + w 11 ⋅ x h + w 12 ⋅ ( x h ) 2 + w 13 ⋅ x w + w 14 ⋅ ( x w ) 2 y = y^{'} + w_9 \cdot x_{hp} + w_{10} \cdot (x_{hp})^2 + w_{11} \cdot x_h + w_{12} \cdot (x_h)^2 + w_{13} \cdot x_w + w_{14} \cdot (x_w)^2 y=y′+w9⋅xhp+w10⋅(xhp)2+w11⋅xh+w12⋅(xh)2+w13⋅xw+w14⋅(xw)2 | 训练集 1.9 1.9 1.9,测试集 102.3 102.3 102.3 |
模型拟合是一个由简到繁的试错过程。每一次新的拟合都是针对上一次拟合结果所进行的改进。在上述七个模型中:
-
首先考虑最简单的情况:假设进化后的CP值 y y y应该与进化前的CP值 x c p x_{cp} xcp值有密切联系,基于此拟合模型一: y = b + w x c p y = b + w x_{cp} y=b+wxcp
并定义损失函数为: L ( f ) = L ( w , b ) = ∑ n = 1 10 ( y ^ n − ( b + w x c p n ) ) 2 L(f) = L(w, b) = \sum_{n=1}^{10} ( \hat{y}^n - (b + wx_{cp}^n) )^2 L(f)=L(w,b)=n=1∑10(y^n−(b+wxcpn))2
分别计算两个偏导数: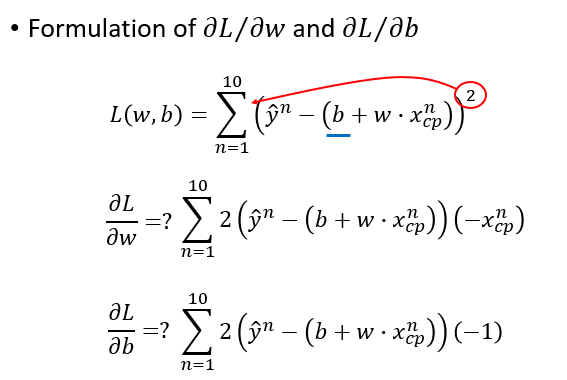
通过训练集,用梯度下降法求得模型一的最优参数为 ( w , b ) = ( 2.7 , − 188.4 ) (w, b) = (2.7,-188.4) (w,b)=(2.7,−188.4)。
即求得最优函数: y = − 188.4 + 2.7 x c p y = -188.4 + 2.7 x_{cp} y=−188.4+2.7xcp。
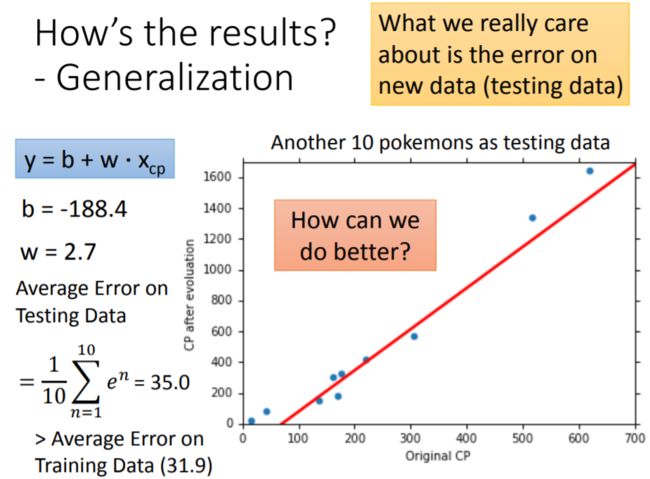
这个函数在训练集上的平均误差为 31.9 31.9 31.9。平均误差(Average Error)的计算公式为: A E = 1 10 ∑ n = 1 10 ∣ e n ∣ AE = \frac{1}{10} \sum_{n=1}^{10} |e^n| AE=101n=1∑10∣en∣
为了考察这个函数的泛化性能,还需要计算测试集上的平均误差:为 35.0 35.0 35.0。
-
进一步地,考虑进化后的CP值 y y y与进化前的CP值 x c p x_{cp} xcp、及其平方项 x c p 2 x_{cp}^2 xcp2之间的关系,拟合模型二: y = b + w 1 x c p + w 2 ( x c p ) 2 y = b + w_1 x_{cp} + w_2 (x_{cp})^2 y=b+w1xcp+w2(xcp)2得到训练集的平均误差为 15.4 15.4 15.4,测试集的平均误差为 18.4 18.4 18.4。
训练集、测试集的平均误差均比模型一小,预测效果明显提升。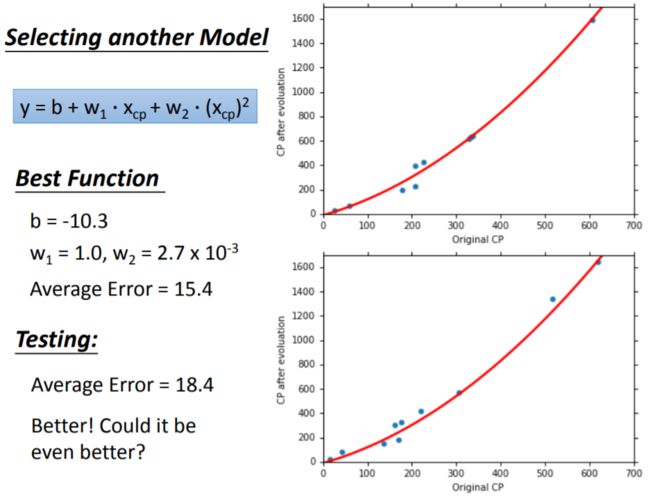
-
以此类推,考虑 x c p x_{cp} xcp、平方项 x c p 2 x_{cp}^2 xcp2、三次方项 x c p 3 x_{cp}^3 xcp3,拟合模型三: y = b + w 1 x c p + w 2 ( x c p ) 2 + w 3 ( x c p ) 3 y = b + w_1 x_{cp} + w_2 (x_{cp})^2 + w_3 (x_{cp})^3 y=b+w1xcp+w2(xcp)2+w3(xcp)3得到训练集的平均误差为 15.3 15.3 15.3,测试集的平均误差为 18.1 18.1 18.1。
训练集、测试集的平均误差相比模型二虽有下降,但降幅变小,预测性能只有小幅提升。
-
当拟合模型四: y = b + w 1 x c p + w 2 ( x c p ) 2 + w 3 ( x c p ) 3 + w 4 ( x c p ) 4 y = b + w_1 x_{cp} + w_2 (x_{cp})^2 + w_3 (x_{cp})^3 + w_4 (x_{cp})^4 y=b+w1xcp+w2(xcp)2+w3(xcp)3+w4(xcp)4得到训练集的平均误差为 14.9 14.9 14.9,测试集的平均误差为 28.8 28.8 28.8。
相比模型三,此时测试集的平均误差反而上升,泛化性能下降,这是由于模型开始出现过拟合的问题。
-
当拟合模型五: y = b + w 1 x c p + w 2 ( x c p ) 2 + w 3 ( x c p ) 3 + w 4 ( x c p ) 4 + w 5 ( x c p ) 5 y = b + w_1 x_{cp} + w_2 (x_{cp})^2 + w_3 (x_{cp})^3 + w_4 (x_{cp})^4 + w_5 (x_{cp})^5 y=b+w1xcp+w2(xcp)2+w3(xcp)3+w4(xcp)4+w5(xcp)5得到训练集的平均误差为 12.8 12.8 12.8,测试集的平均误差为 232.1 232.1 232.1。
相比模型四,测试集的平均误差急速上升,说明已经严重过拟合。
【注】:上面拟合的模型均为线性模型。原因是:虽然多项式回归拟合的是自变量 x x x与因变量 y y y之间的非线性关系,但作为统计估计问题时,模型是针对参数 w w w和 b b b而言的。在某种意义上, y y y与待估计参数之间是呈线性关系的。因此,尽管最后拟合出的是曲线,但仍然视为线性模型。换言之, x c p x_{cp} xcp、 x c p 2 x_{cp}^2 xcp2、 x c p 3 x_{cp}^3 xcp3…等自变量可以视为一只pokemon样本的不同特征,用 x 1 x_1 x1、 x 2 x_2 x2、 x 3 x_3 x3…代替也无妨: y = b + w 1 x c p + w 2 ( x c p ) 2 + w 3 ( x c p ) 3 + w 4 ( x c p ) 4 + w 5 ( x c p ) 5 y = b + w_1 x_{cp} + w_2 (x_{cp})^2 + w_3 (x_{cp})^3 + w_4 (x_{cp})^4 + w_5 (x_{cp})^5 y=b+w1xcp+w2(xcp)2+w3(xcp)3+w4(xcp)4+w5(xcp)5 = b + w 1 x 1 + w 2 x 2 + w 3 x 3 + w 4 x 4 + w 5 x 5 = b + w_1 x_1 + w_2 x_2 + w_3 x_3 + w_4 x_4 + w_5 x_5 =b+w1x1+w2x2+w3x3+w4x4+w5x5
显然,从模型一到模型五,随着模型结构越来越复杂,基于训练集所求出来的平均误差是逐渐降低的,而基于测试集的平均误差则是先减小后增大,从第四个模型开始出现过拟合问题。
为什么会出现过拟合?
考察上面五个模型(函数集)之间的关系,它们之间满足: 模 型 一 ∈ 模 型 二 ∈ 模 型 三 ∈ 模 型 四 ∈ 模 型 五 模型一 \in模型二 \in 模型三 \in 模型四 \in 模型五 模型一∈模型二∈模型三∈模型四∈模型五令 w 5 = 0 w_5 = 0 w5=0,就能使模型五等于模型四;
令 w 4 = 0 w_4 = 0 w4=0,就能使模型四等于模型三;以此类推…
这说明模型五所涵盖的范围最广,它覆盖了前面所有模型的可能情况。与前面四个模型相比,模型五在训练集上的性能应该更好,在训练集上的平均误差应该更小,它的表现至少要优于前面四个模型。

但在测试集上,模型五的表现并非最优,反而是模型三的平均误差最小。从第四个模型开始,平均误差就逐渐增大。可见,模型并非越复杂越好,增加模型的复杂度不能持续提升其在测试集上的性能。
一个复杂模型在训练集上得到了比较好的性能,而在测试集上性能表现十分不理想,这就是过拟合(Overfitting)问题。
在机器学习中,我们更多的是关注模型在测试集(而非训练集)上的表现,这关乎模型的泛化能力。因此在选择模型时,应该以在测试集上表现最佳的模型作为最终选择。

解决过拟合的其中一个方法是收集更多的数据。当持有更多数据的时候,会观察到:进化后的CP值 y y y不止受到 x c p x_{cp} xcp的影响,同时也与pokemon所属的物种 x s x_s xs有关。
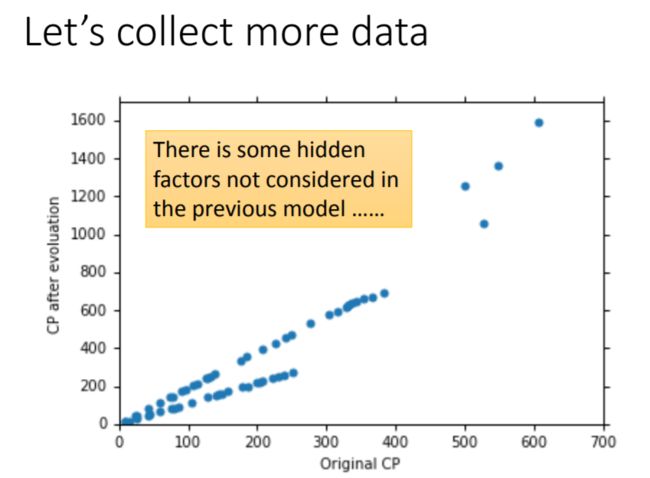
例如下图中,颜色不同的散点分别对应着不同的物种:蓝色是波波(Pidgey),绿色是绿毛虫(Caterpie),黄色是独角虫(Weedle),红色是伊布(Eevee)。容易观察到,在同一物种下,pokemon的 y y y与 x c p x_{cp} xcp之间呈线性关系。

-
因此拟合模型六,使 x s x_s xs这个解释变量也纳入考虑, x s x_s xs表示pokemon对应的种类:
y = { b 1 + w 1 ⋅ x c p , x s = P i d g e y b 2 + w 2 ⋅ x c p , x s = W e e d l e b 3 + w 3 ⋅ x c p , x s = C a t e r p i e b 4 + w 4 ⋅ x c p , x s = E e v e e y = \left \{ \begin{aligned} b_1+ w_1 \cdot x_{cp} &,x_s = Pidgey \\ b_2+ w_2 \cdot x_{cp} &,x_s = Weedle \\ b_3+ w_3 \cdot x_{cp} &,x_s = Caterpie \\ b_4+ w_4 \cdot x_{cp} &,x_s = Eevee \end{aligned} \right. y=⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧b1+w1⋅xcpb2+w2⋅xcpb3+w3⋅xcpb4+w4⋅xcp,xs=Pidgey,xs=Weedle,xs=Caterpie,xs=Eevee该模型表明,当 x s x_s xs取不同的值时,函数表达式的参数不同, y y y值也不同。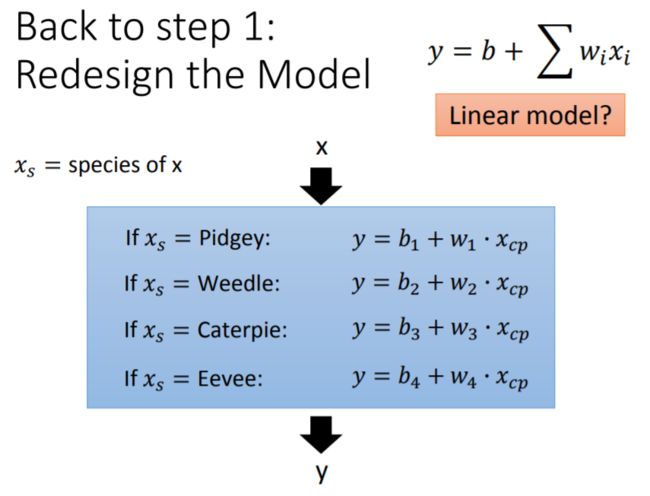
尽管模型六是一个分段的函数集,但它仍然是一个线性模型,因为它可以被表示为如下形式:

相当于引入 δ ( x s = P i d g e y ) \delta(x_s = Pidgey) δ(xs=Pidgey)、 δ ( x s = W e e d l e ) \delta(x_s = Weedle) δ(xs=Weedle)、 δ ( x s = C a t e r p i e ) \delta(x_s = Caterpie) δ(xs=Caterpie)、 δ ( x s = E e v e e ) \delta(x_s = Eevee) δ(xs=Eevee)作为哑变量。其中,蓝色方框内的 8 8 8个变量可分别用 x i ( i = 1 , 2...8 ) x_i(i=1,2...8) xi(i=1,2...8)代替, b 1 , w 1 , . . . , b 4 , w 4 b_1,w_1,...,b_4,w_4 b1,w1,...,b4,w4是待估计的参数,则模型六被简化为线性模型: y = b 1 x 1 + w 1 x 2 + b 2 x 3 + w 2 x 4 + b 3 x 5 + w 3 x 6 + b 4 x 7 + w 4 x 8 y = b_1 x_1 + w_1 x_2 + b_2 x_3 + w_2 x_4 + b_3 x_5 + w_3 x_6 + b_4 x_7 + w_4 x_8 y=b1x1+w1x2+b2x3+w2x4+b3x5+w3x6+b4x7+w4x8
用此模型在训练集上拟合,可求得 8 8 8个参数,代表四条曲线,分别反映四个物种的 y y y与 x c p x_{cp} xcp之间的联系。
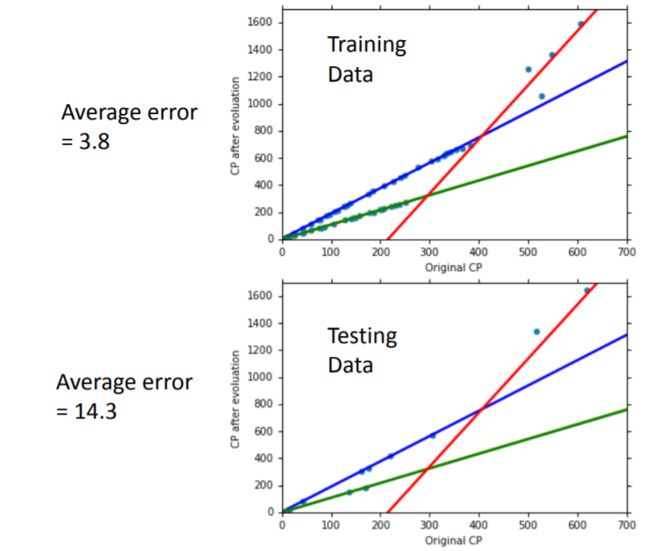
下图为模型六对四个物种的拟合直线。由于Caterpie(绿)与Weedle(黄)的拟合结果十分接近,几乎重合,所以图中看上去只有三条直线(实际有四条直线)。最后,在训练集上平均误差为 3.8 3.8 3.8,在测试集上平均误差为 14.3 14.3 14.3。
-
考虑了物种因素后,模型六的性能虽然有所提升,但在训练集上的平均误差还是没有接近 0 0 0,这可能是由于直线不足以描述 y y y与 x c p x_{cp} xcp之间的关系,又或者是还有其他相关的因素未加以考虑:例如观察如下散点图发现,pokemon的HP值 x h p x_{hp} xhp也可能会影响 y y y。

因此,在模型六加入了物种因素的基础上,拟合模型七:

模型七加入了:进化前的CP值的平方项 ( x c p ) 2 (x_{cp})^2 (xcp)2、体重 x w x_w xw、高度 x h x_h xh、HP值 x h p x_{hp} xhp等因素,含有 18 18 18个待求解参数( w 1 , . . . , w 14 ; b 1 , . . . , b 4 w_1,...,w_{14};b_1,...,b_4 w1,...,w14;b1,...,b4)。
最后得到训练集上的平均误差为 1.9 1.9 1.9,测试集上的平均误差高达 102.3 102.3 102.3,出现严重过拟合,说明模型七的表现不理想。
采用正则化防止过拟合
定义了损失函数后,我们通常按照使训练集的损失函数最小化/平均误差最小化的原则求最优参数,并得到最佳预测函数 f ∗ f^* f∗。但通过这种方法求得的函数,很多时候会产生过拟合问题。
对于上一节设计模型时出现的各种过拟合问题,如果具备相应的领域知识(Domain Knowledge),那么可以根据先验知识人为剔除一些不重要的因素(比如先验知识告诉我们 y y y很大程度上受到 x c p x_{cp} xcp的影响,但一般不会受到 x w x_w xw的影响)。但在无法对各个因素做出准确判断的情况下,通常采正则化(Regularization)来防止过拟合。
正则化方法对损失函数进行了重新定义,在原有损失函数的基础上,加入了一个正则项。假设线性模型为: y = b + ∑ i w i x i y = b + \sum_i w_i x_i y=b+i∑wixi其中 x i x_i xi代表不同的特征/指标: x c p , x h p , x w , x h x_{cp},x_{hp},x_w,x_h xcp,xhp,xw,xh等。则原来的损失函数(未加入正则项)定义为: L = ∑ n ( y ^ n − ( b + ∑ i w i x i n ) ) 2 L = \sum_n ( \hat{y}^n - (b + \sum_i w_i x_i^n))^2 L=n∑(y^n−(b+i∑wixin))2重新定义后的损失函数(加入正则项)为: L ′ = L + λ ∑ i ( w i ) 2 = ∑ n ( y ^ n − ( b + ∑ i w i x i n ) ) 2 + λ ∑ i ( w i ) 2 L' =L + \lambda \sum_i (w_i)^2 = \sum_n ( \hat{y}^n - (b + \sum_i w_i x_i^n))^2 + \lambda \sum_i (w_i)^2 L′=L+λi∑(wi)2=n∑(y^n−(b+i∑wixin))2+λi∑(wi)2
正则项 λ ∑ i ( w i ) 2 \lambda \sum_i (w_i)^2 λ∑i(wi)2是由 λ \lambda λ和所有权重参数 w i w_i wi的平方和构成的。定义新的损失函数 L ′ L' L′后,求 L m i n ′ L'_{min} Lmin′意味着同时求 L m i n L_{min} Lmin和 [ λ ∑ i ( w i ) 2 ] m i n [\lambda \sum_i (w_i)^2]_{min} [λ∑i(wi)2]min:即,它不仅要求原有的损失函数 L L L最小化,还要求正则项也最小化。
使原来的损失函数 L L L最小化容易理解。但最小化正则项对于模型选择有什么帮助呢?或者说,加入正则项的意义是什么?
首先明确,在模型 y = b + ∑ i w i x i y = b + \sum_i w_i x_i y=b+∑iwixi中,参数 w i w_i wi很小意味着模型里的函数是比较平滑的。
所谓函数平滑(Smooth),是指当输入值 x i x_i xi发生变化时,这种变化不会引起输出值 y y y的剧烈变动,即 w i w_i wi越小, Δ x i \Delta x_i Δxi对 Δ y \Delta y Δy的影响越小(可以理解为:较小的 w i w_i wi,降低了因 x i x_i xi变化对 y y y造成的冲击)。举个极端例子,当 w i = 0 w_i = 0 wi=0, y = b y = b y=b是一条相当平滑的直线, x i x_i xi的任何变化都不会对 y y y造成影响。
因此,正则项最小化意味着我们寻找的最佳函数,要尽可能的平滑,能够最大程度地抵挡因输入值变化而对输出值带来的冲击。
正则项存在的意义是:当我们从一个模型(函数集)中挑选最佳函数 f ∗ f^* f∗时,正则项的存在能够避免挑到对波动十分敏感的函数。为什么我们不喜欢那些敏感度高、波动程度大的函数(而倾向于选择平滑函数)?因为波动幅度太大的函数通常会造成很大的误差,相比之下,平滑函数的预测结果更缓和,即便有误差,也不会一下子偏离太远。简言之,平滑函数的表现更符合我们对预测模型的期待。
然而,正则项也有失灵的时候。正则项的存在是为了使最终挑出来的预测函数 f ∗ f^* f∗更平滑,减小测试集上的误差。但,假如真实的函数本身就是一个波动性很大的函数,我们还利用正则项去挑选平滑的预测函数,那么与真实函数恰恰背道而驰。不过这种情况应该是极少见的,大多数情况下,我们还是宁愿相信:一个符合自然规律、符合人类直觉的函数,不应该是波动得特别厉害的函数。所以总体而言,采用正则项对改进拟合效果还是颇有帮助的。
综上,新的损失函数 L ′ L' L′由于加入了正则项,令我们的优化目标变为:
- 寻找最佳函数 f ∗ f^* f∗,使得原来的损失函数 L L L达到最小化
- 这个最佳函数 f ∗ f^* f∗的各权重参数 w i w_i wi也是尽可能小的,从而使 f ∗ f^* f∗尽可能地平滑
对于正则项,还有两个需要注意的地方:
- 正则项中还有一个常数 λ \lambda λ,它是一个需要手动设置的参数,决定了 f ∗ f^* f∗的平滑程度( λ \lambda λ越大,则要求 f ∗ f^* f∗越平滑)
- 正则化通常只作用于权重参数 w i w_i wi(一般不对偏置参数 b b b做正则化)。如果非要为偏置参数 b b b构造正则项,并不是错误的做法,但在实际经验中, b b b的正则化通常对改进模型没有帮助。因为偏置参数 b b b这一项只代表了一条水平线,它对函数 f ∗ f^* f∗是否平滑没有任何影响,只决定 f ∗ f^* f∗上下移动的位置。

如果用不同的正则项参数 λ \lambda λ拟合模型,会发现:随着 λ \lambda λ不断增大,得到的最佳函数 f ∗ f^* f∗也越来越平滑。这个过程中, f ∗ f^* f∗在训练集的平均误差从 1.9 1.9 1.9增大到 8.5 8.5 8.5,这个变化是合理的:因为没有加入正则项的时候,我们的优化目标只有 a r g m i n { L } argmin\{L\} argmin{L},而加入正则项使我们同时要考虑减小 w i w_i wi,使 f ∗ f^* f∗变得平滑。并且随着 λ \lambda λ的增大,我们更倾向于得到平滑的 f ∗ f^* f∗,这是以训练集的平均误差上升为代价的。但训练集的平均误差增大,不代表测试集的平均误差会增大。当 λ = 100 \lambda=100 λ=100时,测试集上的平均误差最小,此时的参数为最优参数。

补充讨论
- 进化后的CP值与进化前的CP值、pokemon的种类有密切关系,但仍然可能存在其他隐藏的关联因素
- 后面将继续介绍梯度下降法的相关理论
- 加入正则项,最后在测试集上得到的最好结果是, λ = 100 \lambda = 100 λ=100,平均误差为 11.1 11.1 11.1。假如继续收集新的数据,平均误差会增大还是减小?(答案:平均误差将会增大,大于 11.1 11.1 11.1)
