下面我们来看一下JAVA中有哪些查找树和哈希表,我们分两块内容来讲呗,第一块我们首先来讲查找树,第二块我们来讲哈希表,
JAVA里面我们有一个TreeSet,还有一个TreeMap,他们底层都是使用了红黑树,这个大家记住,我们在这里有一个图,这个图说明
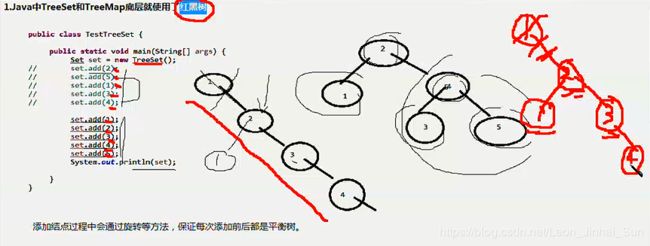
一个什么道理呢,我是不是创建了一个TreeSet,我加的数都是1,2,3,4,5,但是我是不是按照不同的顺序来加的,我想问的一个
问题是,当我们按照不同的顺序来加的话,最终会不会出现这中偏激的情况,会不会出现,不会,为什么不会啊,因为他是红黑树,
红黑树他是一种二叉平衡树,当你没加一个元素,他都会保证这个数加完之后,加之前是平衡树,加之后还是个平衡树,会有相关
的算法来实现自平衡,比如我们按照1,2,3,4,5来加的话,先加一个1是平衡,再加一个2是放在右边,因为它大于1,这时候还是
平衡的,当我们再加个3的时候,他就不平衡了,他有各种算法,比如这个时候我们可以把2的左指针改一下,把1放到这里,这个1
就没有了,这个时候首先左右是平衡的,同时还是二叉平衡树,保证左边的小于根,根小于右边的,你还可以再加一个4,这个时候
还是平衡的,那我们再加5的时候,要加5了,是不是又不平衡了,他还要有一个相应的解决方案,算法把它修改为平衡的状态,
这个大家知道,这是我们所说的一个红黑树,那我顺便想问大家,TreeSet和TreeMap是什么关系,或者说我们的HashSet和HashMap
是什么关系,什么关系我们可以来看一下相关的源码
下面我们来看HashMap的底层结构:
我知道HashSet的底层结构是HashMap了,那你能告诉我HashMap的底层结构是什么吗?
我告诉你,HashMap的底层结构就是哈希表,他就是哈希表,只要以后你见到这个名字,只要这个名字是以Hash开始的,都说明他的
底层结构是哈希表,都说明它是非常快的,速度是很快的,这是我们选择相应集合的一个依据,这个大家知道,底层就是一个哈希表,
主结构是一个数组,每个数组上面可以引一个链,这个链叫做一个桶,我们来看,但是这个时候还有一个变化,在JDK及其之前,我们
现在用的是哪一个,咱们是8,有的同学用的可能是7,那我告诉大家,在JDK1.7之前的话,HashMap底层就是一个哈希表,主结构是一个
数组,从结构是链表,大家来看,主结构是一个数组,然后从结构是一个链表,一个链表连起来就是一个桶,bucket这样的一个单词,
但是我们知道,它是有缺点的,万一这个冲突比较多的话,如果这个链表引得特别长的话,引了20个,30个的话,引了几十个的话,
他的查询效率也是比较低的,有没有别的办法,当然有了,比如后面我们可以给他扩容,这个都是有的,但是即使扩容,也难免会
出现这种情况,那我们怎么来解决,在JDK1.8的时候,给了一个更好的,当然也是一个更好的解决方案,大家再来看下面一个图,
我们来看下面这个图,这个图还是1.7之前的图,每个节点里面存储的还是entry,什么叫entry,有一个key,有一个value,
还有一个指针,这是每个节点,至少包括这三部分,数据就是存在这里面的,数据就是存在这儿的,每个Entry就是一个键值对,
当然还存放着指向下一个节点的指针,这是我们所说的内容,下边我们看,在1.8里面出现了一个什么变化,出现了这样的一个变化,
告诉我这个变化是什么,主结构是不是还是一个数组,如果出现了冲突,是不是还会引这个链表,但是下面一大堆一看就知道是什么,
这是不是红黑树,他怎么引出了红黑树,如果你这个列表的长度,大于等于8的时候,你这个列表太长了,大于等于8个的时候,
他就会把这一块做一下修改,给你变成下面这个结构,为什么要这么变,因为如果要是16个的话,那你这里要查找16次,当你变成一棵树
的话,层次就少了,可能3次4次就可以了,目的还是为了提高查询的效率,他还是提供啊查询的效率,这个主要是查询的时间复杂度上,
链表为O(n),而红黑树是log(2 n),如果冲突比较多,超过8,就采用红黑树来提高效率,这一点大家知道,当然红黑树难度就高了,
代码也就难理解了,这是一个
当我们再来看一下,HashSet的底层结构已经说了,底层就是HashMap,那我们再来看一下HashMap的源码分析,我们以JDK1.7的为准,
那我们现在是1.8的,1.8的可以简单的看一下,怎么看呢,我们就看HashMap就可以了
总结一下:
注意TreeSet和TreeMap用的是红黑树,TreeSet的底层用的是TreeMap,HashMap的底层结构1.7是表加链表,1.8有什么变化,加入了
红黑树,链表长度大于等于8的时候,源码大家去网上找一些相关的源码,最好看JDK1.7的,或者你的版本是1.7,直接来看,看哪些
操作,看他有哪些属性,看他有哪些方法,看他的put和get,来看这个就可以了,网上找资料有什么好处,它会给你加一些中文的
注释,会给你讲解,当然我们刚才找了半天也没有找到合适的,大家耐性来找
package com.learn.search;
import java.util.HashMap;
import java.util.HashSet;
import java.util.TreeSet;
/**
* HashSet的底层结构
* 底层结构采用HashMap
* HashSet的元素作为HashMap的key,
* 统一使用Object对象作为value
* 我们可以看源码
* 这是我们所说的一个内容
* 我们这里还可以再加一句话,
* TreeSet的底层结构是TreeMap,都使用了红黑树
* 因为它底层就是TreeMap,TreeMap的底层是红黑树
* TreeSet当然也是红黑树
* @author Leon.Sun
*
*/
public class TestCollection {
public static void main(String[] args) {
/**
* 然后我们来创建一个TreeSet
* 当我们创建TreeSet的时候,
* 点他进来,
* this(new TreeMap());
* 底层实际上是创建了一个TreeMap
* 你创建了一个TreeSet,实际上是创建了一个TreeMap
* 他给你创建了一个TreeMap
* 这个大家记住了
* TreeSet(NavigableMap m)
* this.m = m;
* 这个m是谁看一下
* private transient NavigableMap m;
* m实际上是一个Map
* 这个明确一下
* 我们再来看一下size
* return m.size();
* 你这个哈希size,你这个TreeSet的size
* 实际上就是map的size
* m.clear();
* 还是map的清空啊
* 为什么,因为我刚才做了一个清空的操作
* this(new TreeMap());
* 是不是new了一个TreeMap
* 结果把这个TreeMap做了一个实参
* TreeSet(NavigableMap m)
* 这个就是一个TreeMap,
* this.m = m;
* 就给这个m了
* 就给他了
*
*/
TreeSet set = new TreeSet();
/**
* 加入一个内容
*/
set.add("aaa");
set.size();
/**
* 很多的函数
*/
set.clear();
/**
* 同样顺便我们来说一下
* 我们创建一个HashSet
* 当你new了一个HashSet的时候,
* 你实际上是new了一个HashMap
* map = new HashMap<>();
* 这个map是谁,点一下这个map
* private transient HashMap map;
* 底层就是一个HashMap
* 是这么来的
* 那我们再来看,
* 当我们add的时候呢
* public boolean add(E e)
* 你往set里面加个数据,
* return map.put(e, PRESENT)==null;
* put我们都用过,放了一个键值对
* 那我们这里放的abc,到map里面是key
* 那value是谁啊
* 一个键一个值
* 就是我们往set里面放的元素
* 放到map里面,
* 会变成map里面的key
* 值是这个PRESENT
* PRESENT他是谁啊
* private static final Object PRESENT = new Object();
* 它是一个空的Object对象
* 他就是一个Object对象
* 表面上是Set,实际上都放到Map里面去了
* 作为Map的key存在
* 那他的value是什么啊
* value都是统一的new Object(),Object对象
* 这个大家知道
*
*/
HashSet set2 = new HashSet();
set2.add("abc");
/**
* 我们再来看size,
* return map.size();
* map的size
*
*/
set2.size();
/**
* map.clear();
* map的clear
*
*/
set2.clear();
/**
* return map.isEmpty();
* map是不是空的
* 这一点大家一定要记住
*/
set2.isEmpty();
/**
* 看我们添加对象的时候是怎么添加的
* this.loadFactor = DEFAULT_LOAD_FACTOR;
* 这个什么意思,相当于我们一创建HashMap的时候,
* 是不是只引用了一个参数,别的参数有没有指定
* 没有指定,
* static final float DEFAULT_LOAD_FACTOR = 0.75f;
* 这个Default_load_factor什么意思
* 0.75是什么啊,就是我们将哈希表说的装填因子
* 他采用默认的是0.75
* 如果你要是100个,数组的总长度是100,
* 达到75个之后就扩容了
* 他就开始扩了
* 那我想知道默认的总长度是多少
* 我想知道哈希表默认的总长度是多少
* 那我们是可以找一下的
* static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
* 默认的总长度,这什么意思啊
* 1左移4位,每左移相当于乘以2
* 相当于16嘛
* 默认的初始化长度是16
* 但是你要知道
* 如果从源码上来看的话
* 他里面有没有指定默认的值
* 没有指定
* 初始化容量,默认装填因子
* public HashMap(int initialCapacity, float loadFactor)
* 这里面会有的
* this.threshold = tableSizeFor(initialCapacity);
* 会有这样的一个操作
* 从而把16传进去,赋给另外一个属性
* 这个就是1.8,1.8来说就要难一些了
* 我们再来看这个put了
*
*/
HashMap map = new HashMap();
/**
* 这个相当于添加
*
* put什么意思
* 就调了个putVal,
* return putVal(hash(key), key, value, false, true);
* putVal里面怎么办
* 这里面来说就是相对比较复杂了
* 我们这里面甚至都有TreeNode了
* 那就涉及到了红黑树了
* 红黑树的节点
* 就是链表的节点,可以这么来理解
* 这是我们所说的一个内容
*
*/
map.put("cn", "China");
map.put("us", "USA");
/**
* 请问这个时候我输出us是谁
* 是USA还是America
* 是不是America
* 因为我们来放是按照key来放的
* 我们按照key来放的
* 值是跟着key走的
* 如果我们放了一次us
* 现在再放一次us
* us只存一个
* 但是这个value就变了
* 就由USA变成了America
* 就变成他了
* 那我们看一下是不是这个代码
* 打开他来看
* 哈希码相同并且对象相同
* 新值替换旧值
* 这什么意思啊
* 返回的就是一个旧值
* V oldValue = e.value;
* 把原来的值赋给旧值
* e.value = value;
* 把现在的值相当于旧值替换
* return oldValue;
* 最后返回的是旧值
* 是这么来的
* 大家还是在网上多搜一下1.7的代码
* 还是比较好看的
* 因为1.8加了一个我们红黑树
* 代码比较难懂
* 大家就可以到网上找一些相关的资料来看
* 那JAVA中的查找和哈希表就讲到这里了
*/
map.put("us", "America");
/**
* 大家想一下,这个相当于获取
*
* 我们再来看一个内容,
* get怎么办呢,
* 找HashMap的get呗
* 他最终调的是getNode,
* return (e = getNode(hash(key), key)) == null ? null : e.value;
* 先得到这个e,
* e就是那个Entry
* getNode可以看一下里面的这个代码
* 因为自从1.8之后这个难度就比较高了
* 比较难理解
* 那我们就看一下1.7的
* 1.7的就非常好理解了
* 怎么看1.7呢
* 那我们就网上来找吧
* 很多人关注他
* https://www.cnblogs.com/stevenczp/p/7028071.html
* 很多人关注这个
* http://www.cnblogs.com/wuhuangdi/p/4175991.html
* 至少找一个排版比较好的
* HashMap的存储结构
* 主结构是一个数组
* 这是不是一个链表啊
* 而每个Entry里面一放大,
* 有key,有value,是不是还要有一个指针指向下一个
* 我们给大家介绍一下,大家看资料的时候也比较方便
* 我们找他无参构造方法吧
* 他这个不好
* https://blog.csdn.net/jevonscsdn/article/details/54619114
* 先了解一下他的成员
* static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
* 这是我们刚才看到的默认长度16
* static final float DEFAULT_LOAD_FACTOR = 0.75f;//默认加载因子
* 默认的加载因子0.75
* 这个也不好
* 总可以找到很好的
* 构造方法,
* 比如我们来看这个,
* https://blog.csdn.net/u011617742/article/details/54576890
* 我们就是要找无参构造方法
* https://blog.csdn.net/ghsau/article/details/16843543/
* public V put(K key, V value)
* 他这个put就是1.7的
* 这个put什么含义
* 我们找最关键的,
* int hash = hash(key);
* 得到这个方法
* 把key传进来,调用这个hash,他就会得到哈希码
* 就是key本身是有哈希码的,这个二次进行了hash,这是一个细节
* 把这个哈希码又重新转换了一下,这一步就相当于得到哈希码
* int i = indexFor(hash, table.length);
* 这一步indexFor,根据哈希码和数组的长度去得到这个地址
* 这是我们哈希表原理里面的第一步
* 第一步计算哈希码,第二步根据哈希码算出地址,
* 第三步我们要干什么了,
* 就是1这个位置,是不是要顺着链表往下找了
* 往下找怎么办,如果找到一个14呢
* 不是不放,我们放的是map,
* map是什么意思,
* map就是这个意思,
*
*
*/
map.get("cn");
}
}