极大似然估计(MLE)、最大后验概率估计(MAP)、贝叶斯估计(BE)
文章目录
- 生成过程与估计过程
- 极大似然估计(MLE)
- 似然函数
- 极大似然估计
- 实际应用
- 最大似然估计与极大似然估计(MLE)
- 常见的概率分布模型
- 直观理解
- 最大后验概率估计(MAP)
- 贝叶斯估计(BE)
- 三者的比较
- 频率派VS贝叶斯派
生成过程与估计过程
假设我们有一个概率模型,例如是高斯分布模型 N ( μ , σ ) N(μ,σ) N(μ,σ),利用这个模型,我们生成很多数据 { x 1 , x 2 … x N } \{x_{1},x_{2} \dots x_{N}\} {x1,x2…xN},这是利用模型生成数据的过程。
但如果反过来,我们有一批数据 { x 1 , x 2 … x N } \{x_{1},x_{2} \dots x_{N}\} {x1,x2…xN},想根据这批数据估计模型的参数,例如高斯分布模型的 μ , σ μ,σ μ,σ,这就是估计过程。常见的估计方法有极大似然估计、最大后验概率估计、贝叶斯估计等。含有隐变量的极大似然估计就是大名鼎鼎的EM算法。
极大似然估计(MLE)
似然函数
在概率论中,设 f ( x , Θ ) f(x,\Theta) f(x,Θ)为总体分布,其中 Θ \Theta Θ为概率分布模型的参数且在这里是未知的,且设该概率分布模型的参数有k个,即 { θ 1 , θ 2 … θ k } \{\theta_{1},\theta_{2} \dots \theta_{k}\} {θ1,θ2…θk}, x 1 , x 2 , x 3 … x n x_{1},x_{2},x_{3} \dots x_{n} x1,x2,x3…xn为对该总体采样得到的样本(生成过程),因为这些样本独立同分布,所以它们的联合概率密度为
L ( x 1 , x 2 … x n ; θ 1 , θ 2 … θ k ) = ∏ i = 1 n f ( x i ; θ 1 , θ 2 … θ k ) L(x_{1},x_{2} \dots x_{n};\theta_{1},\theta_{2} \dots \theta_{k})=\prod_{i=1}^{n}f(x_{i};\theta_{1},\theta_{2} \dots \theta_{k}) L(x1,x2…xn;θ1,θ2…θk)=i=1∏nf(xi;θ1,θ2…θk)
因为样本已经存在,所以认为 x 1 , x 2 , x 3 … x n x_{1},x_{2},x_{3} \dots x_{n} x1,x2,x3…xn为固定值,所以 L ( x , Θ ) L(x,\Theta) L(x,Θ)为关于 Θ \Theta Θ的函数,这就是似然函数,表示为 L ( Θ ∣ x ) L(\Theta|x) L(Θ∣x)。所以似然函数其实就是样本点的联合概率密度函数,只不过自变量变成了概率分布模型的参数 Θ \Theta Θ。似然函数一般形式如下:
L ( θ ∣ x ) = p ( x ∣ Θ = θ ) = p ( x ; Θ = θ ) L(\theta|x)= p(x|\Theta = \theta)= p(x;\Theta = \theta) L(θ∣x)=p(x∣Θ=θ)=p(x;Θ=θ)
p ( x ∣ θ ) p(x| \theta) p(x∣θ)与 p ( x ; θ ) p(x;\theta) p(x;θ)在这里表示一个意思,即在给定模型参数是 θ \theta θ的条件下, x x x的概率,与 x x x和 θ \theta θ的联合概率分布结果是一样的。还有一种解释方法可以看blog:https://blog.csdn.net/pipisorry/article/details/42715245 。这也是为什么贝叶斯公式分母去掉先验后的剩余部分是似然函数的原因。
一个似然函数乘以一个正的常数之后仍然是似然函数。所以 L ( θ ∣ x ) = α p ( x ∣ Θ = θ ) , α > 0 。 L(\theta|x)=\alpha p(x|\Theta = \theta),\alpha > 0。 L(θ∣x)=αp(x∣Θ=θ),α>0。
似然和概率是两码事,概率描述了已知概率模型参数时的随机变量的输出结果;似然则用来描述已知随机变量输出结果时,未知概率模型参数的可能取值,也就是说,概率使用背景是模型参数已知,似然是模型参数未知。
极大似然估计
顾名思义,求似然函数中参数 θ \theta θ的值,使得似然函数最大。
实际应用
一般用对数似然函数,对其求导取驻点得到要求的 θ \theta θ:
l o g L ( θ 1 , θ 2 … θ k ) = ∑ i = 1 n l o g f ( x i ; θ 1 , θ 2 … θ k ) logL(\theta_{1},\theta_{2} \dots \theta_{k})=\sum_{i=1}^{n}logf(x_{i};\theta_{1},\theta_{2} \dots \theta_{k}) logL(θ1,θ2…θk)=i=1∑nlogf(xi;θ1,θ2…θk)
∂ L ( θ ) θ i = 0 i = 1 , 2 … k \frac{\partial L(\theta)}{\theta_{i}}=0~~~~~~~~~i=1,2 \dots k θi∂L(θ)=0 i=1,2…k
最大似然估计与极大似然估计(MLE)
在很多场合下,最大似然估计与极大似然估计是一种东西的两种叫法,理论上我们应该是要求最大似然估计,但是由于我们是求对数似然函数的驻点得到,严格来说求得是极值点,所以也叫极大似然估计,在指数族框架下的概率密度函数,极值就是最值。我个人倾向于叫极大似然估计。
常见的概率分布模型
- 伯努利分布(零一分布、两点分布)
p ( x = 1 ) = p , p ( x = 0 ) ≠ 1 − p p(x=1)=p,~~~~p(x=0) \neq 1-p p(x=1)=p, p(x=0)̸=1−p。其概率密度函数可写为:
f ( x ∣ p ) = { p x ( 1 − p ) x x = 1 , 0 0 x ≠ 1 , 0 f(x|p)=\begin{cases} p^{x}(1-p)^{x} & x=1,0 \\ 0 & x \neq 1,0 \end{cases} f(x∣p)={px(1−p)x0x=1,0x̸=1,0
对于伯努利模型n次独立产生结果,k次结果为1,可以用极大似然估计估计其模型参数p,即x=1的概率。其似然函数为 L ( p ) = p k ( 1 − p ) n − k L(p)=p^{k}(1-p)^{n-k} L(p)=pk(1−p)n−k(这里似然函数简单,不用取对数也可以,不过本blog仍按照取对数计算),对数似然函数为 l o g L ( p ) = k l o g p + ( n − k ) l o g ( 1 − p ) logL(p)=klogp+(n-k)log(1-p) logL(p)=klogp+(n−k)log(1−p),对p求偏导等于0得到 p = k n p=\frac{k}{n} p=nk。
- 正太分布
X~ N ( μ , σ 2 ) (\mu, \sigma^{2}) (μ,σ2)。其概率密度函数可写为:
f ( x ∣ μ , σ ) = 1 2 π σ 2 e − ( x − μ ) 2 2 σ 2 f(x|\mu, \sigma)=\frac{1}{\sqrt{2 \pi \sigma^{2}}}e^{-\frac{(x-\mu)^2}{2\sigma^2}} f(x∣μ,σ)=2πσ21e−2σ2(x−μ)2
对于正态分布模型n次独立产生结果,可以用极大似然估计估计其模型参数 μ , σ \mu,\sigma μ,σ。其似然函数为 L ( μ , σ ) = ∏ n i = 1 f ( x i ∣ μ , σ ) L(\mu,\sigma)=\prod \limits ^{i=1}_{n}f(x_{i}|\mu,\sigma) L(μ,σ)=n∏i=1f(xi∣μ,σ),对数似然函数为 l o g L ( μ , σ ) = ∑ i = 1 n l o g f ( x i ∣ μ , σ ) = − n 2 l o g ( 2 π σ 2 ) − ∑ i = 1 n ( x i − μ ) 2 2 σ 2 logL(\mu,\sigma)=\sum \limits_{i=1}^{n}logf(x_{i}|\mu,\sigma)=-\frac{n}{2}log(2\pi \sigma^2)-\sum \limits_{i=1}^{n}\frac{(x_{i}-\mu)^2}{2\sigma^2} logL(μ,σ)=i=1∑nlogf(xi∣μ,σ)=−2nlog(2πσ2)−i=1∑n2σ2(xi−μ)2,对 μ , σ \mu,\sigma μ,σ分别求偏导等于0得到 μ = 1 n ∑ i = 1 n x i , σ 2 = 1 n ∑ i = 1 n ( x i − μ ) 2 \mu=\frac{1}{n}\sum \limits_{i=1}^{n}x_{i},~\sigma^2=\frac{1}{n}\sum \limits_{i=1}^{n}(x_{i}-\mu)^2 μ=n1i=1∑nxi, σ2=n1i=1∑n(xi−μ)2,可见 μ , σ 2 \mu,\sigma^2 μ,σ2分别就是样本的均值和伪方差(方差为 1 n − 1 ∑ i = 1 n ( x i − μ ) 2 \frac{1}{n-1}\sum \limits_{i=1}^{n}(x_{i}-\mu)^2 n−11i=1∑n(xi−μ)2),符合我们的直观认识。
- 其它分布
用到了回来补上。
直观理解
假设一个妈妈( a 1 a_{1} a1)带着自己孩子(b)出去,中途和另一个妈妈( a 2 a_{2} a2)交谈,这时,来了一个朋友,这位朋友如何知道孩子(b)具体是谁的孩子呢?经验来看就是孩子 b b b和妈妈 a 1 a_{1} a1长得像,所以应该是 a 1 a_{1} a1的孩子,用极大似然估计法解释就是 p ( b ; θ = a 1 ) p(b;\theta=a_{1}) p(b;θ=a1)要大于 p ( b ; θ = a 2 ) p(b;\theta=a_{2}) p(b;θ=a2),把 a 1 a_{1} a1与 a 2 a_{2} a2理解为概率分布模型参数,所以 b b b应该属于类别 a 1 a_{1} a1。
最大后验概率估计(MAP)
上面说过,极大似然估计就是求解下面的式子(直接表示成了对数似然函数): a r g max θ log p ( x ∣ θ ) arg \max \limits_{\theta}\log p(x|\theta) argθmaxlogp(x∣θ)
这里模型参数 θ \theta θ是确定但是未知的,我们假设了参数 θ \theta θ的取值,例如伯努利分布中的p参数,才能对上式进行进一步的数学求解。
如果我们知道了模型参数 θ \theta θ的一些先验分布,我们就要用最大后验概率估计来求解参数 θ \theta θ,最大后验概率估计主要求解下面的式子: a r g max θ p ( θ ∣ x ) arg \max \limits_{\theta} p(\theta|x) argθmaxp(θ∣x) p ( θ ∣ x ) p(\theta|x) p(θ∣x)就是后验概率,这也是最大后验概率名字的由来。用贝叶斯公式展开就是 a r g max θ p ( x ∣ θ ) p ( θ ) p ( x ) arg \max \limits_{\theta} \frac{p(x|\theta)p(\theta)}{p(x)} argθmaxp(x)p(x∣θ)p(θ)考虑到分母和 θ \theta θ无关,因此在求解上式时直接舍去,同时转化为对数形式有 a r g max θ log p ( x ∣ θ ) p ( θ ) = a r g max θ ( log p ( x ∣ θ ) + log p ( θ ) ) \begin{aligned} & arg \max \limits_{\theta} \log p(x|\theta)p(\theta) \\ = & ~arg \max \limits_{\theta} (\log p(x|\theta)+\log p(\theta))\end{aligned} =argθmaxlogp(x∣θ)p(θ) argθmax(logp(x∣θ)+logp(θ))
可以看到最大后验概率估计的前半部分就是似然函数,后面部分是参数的先验分布,我们可以认为模型参数 θ \theta θ满足高斯分布或者beta分布。以参数 θ \theta θ满足均值是0.5,方差是0.1的高斯分布为例可得 a r g max θ log p ( x ∣ θ ) p ( θ ) = a r g max θ ( log p ( x ∣ θ ) + log p ( θ ) ) = a r g max θ ( log p ( x ∣ θ ) + log 1 2 π × 0.1 exp ( − ( θ − 0.5 ) 2 2 × 0.1 ) \begin{aligned} & arg \max \limits_{\theta} \log p(x|\theta)p(\theta) \\ = & ~arg \max \limits_{\theta} (\log p(x|\theta)+\log p(\theta))\\ = &~ arg \max \limits_{\theta} (\log p(x|\theta)+\log \frac{1}{\sqrt{2\pi \times 0.1}} \exp{(-\frac{(\theta-0.5)^2}{2\times 0.1}}) \end{aligned} ==argθmaxlogp(x∣θ)p(θ) argθmax(logp(x∣θ)+logp(θ)) argθmax(logp(x∣θ)+log2π×0.11exp(−2×0.1(θ−0.5)2)
所以,最大后验概率估计可以看作是规则化(regularization)的最大似然估计,这点在求解对数形式函数时更加的明显(此时同机器学习模型一样是加性的规则化,不是乘性的)。
求解最大后验概率估计就是对上面的式子求导取极值点,方法和极大似然估计类似,求出的结果是一个确定的点。
贝叶斯估计(BE)
贝叶斯估计看名字,也知道主要在使用贝叶斯公式,和最大后验概率估计的前半截一样,后面的步骤不同。前半截同MAP一样,求参数 θ \theta θ的后验概率 p ( θ ∣ x ) = p ( x ∣ θ ) p ( θ ) p ( x ) p(\theta|x) = \frac{p(x|\theta)p(\theta)}{p(x)} p(θ∣x)=p(x)p(x∣θ)p(θ)由于分母和参数 θ \theta θ没有任何关系,只考虑分子部分 (1) p ( θ ∣ x ) = α p ( x ∣ θ ) p ( θ ) = α ∏ i = 1 N p ( x i ∣ θ ) p ( θ ) p(\theta|x) =\alpha p(x|\theta)p(\theta) \tag{1}=\alpha \prod\limits_{i=1}^{N}p(x_{i}|\theta)p(\theta) p(θ∣x)=αp(x∣θ)p(θ)=αi=1∏Np(xi∣θ)p(θ)(1)其中 α \alpha α是与 θ \theta θ无关的部分,由于最大后验概率估计认为 θ \theta θ是一个确定但未知的参数,所以MAP认为(1)式是关于 θ \theta θ的一般函数,就把估计问题转变成了优化问题,找到参数 θ \theta θ使得(1)式最大,可以使用导数等优化方法,求得的最值点就是参数 θ \theta θ的估计值。
但是在贝叶斯估计中,认为参数 θ \theta θ是一个未知的变量,所以贝叶斯估计认为(1)式是 p ( θ ∣ x ) p(\theta|x) p(θ∣x)的后验概率密度函数。我们要求的参数 θ \theta θ的估计值 θ ^ \hat{\theta} θ^,要满足最小化下面的期望损失函数 a r g min θ ^ ∫ f ( θ ^ , θ ) p ( θ ∣ x ) d θ arg \min \limits_{\hat{\theta}} \int f(\hat{\theta}, \theta)p(\theta|x) d\theta argθ^min∫f(θ^,θ)p(θ∣x)dθ
其中 θ ^ \hat{\theta} θ^是估计值, f ( θ ^ , θ ) f(\hat{\theta}, \theta) f(θ^,θ)是损失函数,一般可以选择二阶损失函数 f ( θ ^ , θ ) = ( θ ^ − θ ) 2 f(\hat{\theta}, \theta)=(\hat{\theta}- \theta)^{2} f(θ^,θ)=(θ^−θ)2
我们对期望损失函数 = ∫ f ( θ ^ , θ ) p ( θ ∣ x ) d θ = ∫ ( θ ^ − θ ) 2 p ( θ ∣ x ) d θ = ∫ ( θ ^ 2 − 2 θ ^ θ + θ 2 ) p ( θ ∣ x ) d θ = θ ^ 2 ∫ p ( θ ∣ x ) d θ − 2 θ ^ ∫ θ p ( θ ∣ x ) d θ + ∫ θ 2 p ( θ ∣ x ) d θ \begin{aligned} & =\int f(\hat{\theta}, \theta)p(\theta|x)d\theta \\ & = \int (\hat{\theta}- \theta)^{2}p(\theta|x)d\theta \\ & = \int (\hat{\theta}^{2}-2\hat{\theta}\theta+\theta^{2})p(\theta|x)d\theta \\ & = \hat{\theta}^{2}\int p(\theta|x)d\theta-2\hat{\theta}\int\theta p(\theta|x)d\theta+\int \theta^{2}p(\theta|x)d\theta \end{aligned} =∫f(θ^,θ)p(θ∣x)dθ=∫(θ^−θ)2p(θ∣x)dθ=∫(θ^2−2θ^θ+θ2)p(θ∣x)dθ=θ^2∫p(θ∣x)dθ−2θ^∫θp(θ∣x)dθ+∫θ2p(θ∣x)dθ
对 θ ^ \hat{\theta} θ^求导可得 θ ^ ∗ = ∫ θ p ( θ ∣ x ) d θ ∫ p ( θ ∣ x ) d θ \hat{\theta}^{*}=\frac{\int\theta p(\theta|x)d\theta}{\int p(\theta|x)d\theta} θ^∗=∫p(θ∣x)dθ∫θp(θ∣x)dθ考虑到 ∫ p ( θ ∣ x ) d θ = 1 \int p(\theta|x)d\theta=1 ∫p(θ∣x)dθ=1,所以最终得到的参数 θ \theta θ的最终估计值是 θ ^ ∗ = ∫ θ p ( θ ∣ x ) d θ \hat{\theta}^{*}=\int\theta p(\theta|x)d\theta θ^∗=∫θp(θ∣x)dθ也就是参数 θ \theta θ的后验概率期望,即是贝叶斯估计的最终估计结果。
综上,贝叶斯估计根据参数的先验分布 P ( θ ) P(\theta) P(θ)和一系列观察X,求出参数 θ \theta θ的后验分布 P ( θ ∣ X ) P(\theta|X) P(θ∣X),然后求出 θ \theta θ的期望值,作为其最终值。
贝叶斯估计可以迭代使用:在观察一些数据后,利用BE求得到后验概率,可以当作新的先验概率,再根据新的数据得到新的后验概率。因此贝叶斯定理可以应用在许多不同的证据上,不论这些证据是一起出现或是不同时出现都可以,这个程序称为贝叶斯更新(Bayesian updating)。
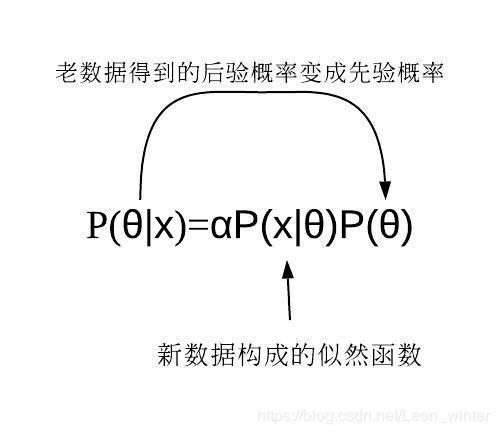
三者的比较
有观点认为极大似然估计中, p ( x ∣ θ ) p(x|\theta) p(x∣θ),数据x是已确定的,参数 θ \theta θ是变量,但我觉得这样理解不太准确。
在MLE中, θ \theta θ应该是已经确定但是未知的,所以MLE求得的结果是参数 θ \theta θ的一个点。
在MAP中, θ \theta θ同样是已经确定但是未知的,但是与MLE不同的是,MAP考虑了先验知识,也就是参数 θ \theta θ根据我们的经验,满足一个概率分布,MLE求得的结果同样是参数 θ \theta θ的一个点。
在BE中, θ \theta θ压根就是未知的变量,我们利用贝叶斯定理得到了参数 θ \theta θ的后验概率分布,而不是MLE或MAP那样得到一个点,只不过我们最终取后验概率期望为我们最终的估计值。
频率派VS贝叶斯派
频率派认为参数是固定的,样本是变换的,例如极大似然估计和最大后验概率估计,参数不随观察结果 x x x的变化而变化,所以你使用MLE和MAP的参数估计结果都是一个值;如果你使用贝叶斯公式 p ( θ ∣ x ) = p ( x ∣ θ ) p ( θ ) p ( x ) p(\theta|x)=\frac{p(x|\theta)p(\theta)}{p(x)} p(θ∣x)=p(x)p(x∣θ)p(θ),由于 p ( θ ) p(\theta) p(θ)与 p ( x ) p(x) p(x)均是固定的,所以相当于只考虑了 p ( x ∣ θ ) p(x|\theta) p(x∣θ),这个函数就是似然函数,其实是定值只不过你不知道,又可以写成 p ( x ; θ ) p(x;\theta) p(x;θ)。
贝叶斯派认为样本是固定的,参数是变换的,所以,使用BE得到的参数估计结果是一个分布,所以 P ( θ ∣ x ) P(\theta|x) P(θ∣x),当 x x x不断有新的观察值进入,就会不断更新 θ \theta θ,最初的没有观察值的概率称为先验概率,先验概率由经验得到,这些经验不会直接影响概率,仅提供一个参考。在频率学派中不考虑先验,在贝叶斯学派中先验极其重要,需要假设。
参考资料:
极大似然估计与最大后验概率估计:https://blog.csdn.net/u011508640/article/details/72815981
极大似然估计与最大后延概率估计:https://www.cnblogs.com/sylvanas2012/p/5058065.html
贝叶斯估计:https://blog.csdn.net/zengxiantao1994/article/details/72889732
贝叶斯估计:https://blog.csdn.net/pipisorry/article/details/51471222