机器学习教程 之 SKlearn 中 PCA 算法的运用:人脸识别实例
一.PCA原理简介
关于主成分分析算法,即 Principal conponent analysis ,PCA是数据分析与挖掘领域最常见也是最经典的降维方法。它通过对原数据的协方差矩阵进行广义特征值的求解,将原数据矩阵转化到另一组正交基空间(即特征向量空间)当中,在这一正交基空间中不同的维度具有不同权重,这一权重的大小对应相应的特征向量的特征值的大小,特征值越大,原数据在这一维度的重要性越大,即这一维度对于原数据的解释性与代表性更强。通过这一算法,我们可以保留数据中重要的属性,舍去代表性差的属性,从而达到压缩数据、数据降维的目的。
这一经典的无监督降维算法已经有很多网友对其原理进行了详细和全面的讲解,比如:
[1] http://blog.csdn.net/zhongkelee/article/details/44064401
[2] https://www.cnblogs.com/SCUJIN/p/5965946.html
[3] http://blog.jobbole.com/109015/
这里,我就讲解一下,在python库sklearn当中PCA接口的使用,并给出一个用于人脸识别的例子
二. sklearn 中的PCA
我们可以以下式将PCA导入
from sklearn.decomposition import PCAPCA的函数原型如下:
sklearn.decomposition.PCA(n_components=None, copy=True, whiten=False)参数说明:
- n_components: PCA算法中所要保留的主成分个数n,缺省时默认为None,所有成分被保留。若赋值为int,比如n_components=1,将把原始数据降到一个维度。赋值为小数,比如n_components = 0.9,将自动选取特征个数n,使得满足所要求的方差百分比。
- copy: 类型:bool,True或者False,缺省时默认为True。表示是否在运行算法时,将原始训练数据复制一份,若为True,则运行PCA算法后,原始训练数据的值不会有任何改变,因为是在原始数据的副本上进行运算;若为False,则运行PCA算法后,原始训练数据的值会改,因为是在原始数据上进行降维计算。
- whiten:类型:bool,缺省时默认为False。意义:白化,使得每个特征具有零均值、单位方差
基本的代码如下:
from sklearn.decomposition import PCA #导入PCA
pca = PCA(0.99,True,True) #建立pca类,设置参数,保留99%的数据方差
trainDataS = pca.fit_transform(trainData) #拟合并降维训练数据
testDataS = pca.transform(testData) #降维测试数据三. PCA降维进行人脸识别
为了便于讲解,我们先导入人脸数据用于PCA降维,两个人脸数据集的下载地址如下:
yale_face:https://github.com/LiangjunFeng/Machine-Learning/tree/master/pic/SFA/yale_face
orl_face: https://github.com/LiangjunFeng/Machine-Learning/tree/master/pic/SFA/orl_faces_full
数据的导入代码为:
import skimage.io as io
import numpy as np
def LoadData(number): #需要选择数据集
if number == 1:
path = '/Users/zhuxiaoxiansheng/Desktop/yale_faces/*.bmp' #数据集的路径
num =11
elif number == 2:
path = '/Users/zhuxiaoxiansheng/Desktop/orl_faces_full/*.pgm' #数据集的路径
num =10
pictures = io.ImageCollection(path)
data = []
for i in range(len(pictures)):
data.append(np.ravel(pictures[i].reshape((1,pictures[i].shape[0]*pictures[i].shape[1]))))
label = []
for i in range(len(data)):
label.append(int(i/num))
return np.matrix(data),np.matrix(label).T #返回数据和标签我们可以先来看几张yale_face里的人脸图片

导入数据以后,我们还需要将它拆分为训练集和测试集,可以使用下面这段代码:
import math
import random
def SplitData(data,label,number,propotion): #输入数据、标签、数据集种类、和拆分比例
if number == 1:
classes = 15
elif number == 2:
classes = 40
samples = data.shape[0]
perClass = int(samples/classes)
selected = int(perClass*propotion)
trainData,testData = [],[]
trainLabel,testLabel = [],[]
count1 = []
for i in range(classes):
count2,k = [],math.inf
for j in range(selected):
count2.append(k)
k = random.randint(0,perClass-1)
while k in count2:
k = random.randint(0,perClass-1)
trainData.append(np.ravel(data[perClass*i+k]))
trainLabel.append(np.ravel(label[perClass*i+k]))
count1.append(11*i+k)
for i in range(samples):
if i not in count1:
testData.append(np.ravel(data[i]))
testLabel.append(np.ravel(label[i])) #返回训练集、训练集标签、测试集、测试集标签
return np.matrix(trainData),np.matrix(trainLabel),np.matrix(testData),np.matrix(testLabel) 另外,我们还需要用到sklearn中的一些分类器以用作分类:
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
def Faceidentifier( trainDataSimplified,trainLabel,testDataSimplified,testLabel):
print("=====================================")
print("GaussianNB") #高斯贝叶斯分类器
clf1 = GaussianNB()
clf1.fit(trainDataSimplified,np.ravel(trainLabel))
predictTestLabel1 = clf1.predict(testDataSimplified)
show_accuracy(predictTestLabel1,testLabel)
print()
print("SVC") #支持向量机分类器
clf3 = SVC(C=8.0)
clf3.fit(trainDataSimplified,np.ravel(trainLabel))
predictTestLabel3 = clf3.predict(testDataSimplified)
show_accuracy(predictTestLabel3,testLabel)
print()
print("LogisticRegression") #逻辑回归分类器
clf4 = LogisticRegression()
clf4.fit(trainDataSimplified,np.ravel(trainLabel))
predictTestLabel4 = clf4.predict(testDataSimplified)
show_accuracy(predictTestLabel4,testLabel)
print()
print("=====================================") 做完这些准备工作,我们只需要很简单的几步,就可以完成人脸识别的工作
if __name__ == "__main__":
data,label = LoadData(2) #可以分别输入1,2看看两个数据集的分类效果
trainData,trainLabel,testData,testLabel = SplitData(data,label,2,0.6)
pca = PCA(30,True,True)
trainDataS = pca.fit_transform(trainData)
testDataS = pca.transform(testData)
Faceidentifier(trainDataS,trainLabel,testDataS,testLabel)
两个数据集分类的正确率分别如下:
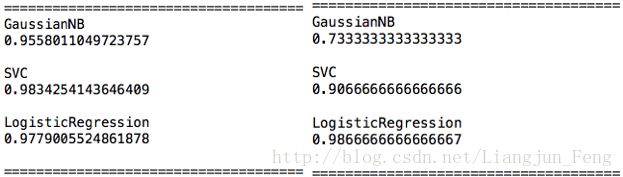
此外,我们将PCA得到的特征向量重构为原图像长宽的图像,可以得到所谓的特征脸图片,大家可以自己尝试。
关于PCA降维的一个与K均值聚类算法联合运用的代码地址为:
https://github.com/LiangjunFeng/Machine-Learning/blob/master/8.PCA.py