数据科学领域的缺陷汇总
技术盲点
从数据科学家的角度来看,他们通常认为实际技术与 功能性取向没有太大关联,因为所使用的模型和算法是以数学方式定义的。因此,算法的数学定义是揭示真相的唯一途径。但对于非功能性需求,这个观点有些站不住脚。例如,编程语言和技术方面的专家的可用情况和成本存在很大的差异。在维护方面,所选择的技术对于项目能否取得成功有很大影响。
数据科学家倾向于使用他们最擅长的编程语言和框架。首先,我来介绍一下 R 和 R-Studio 等开源技术,这些技术的程序包和库数量庞大且难以管理,而且其语法松散且难以维护。随后,我会介绍语法结构完善且经过精心组织的 Python 及相关框架(如 Pandas 和 Scikit-Learn)。另一类工具是“含少量代码或无代码”的完全可视化开源工具,如 Node-RED、KNIME、RapidMiner 和 Weka 以及诸如 SPSS Modeler 之类的商用产品。
“我最熟悉的技术”足以满足概念验证 (proof of concept, PoC)、黑客马拉松或启动式项目的需求。但对于行业和企业级规模的项目,必须提供有关技术使用的一些架构准则,无论此类技术有多浅显易懂都应如此。
缺乏再现性和可复用性
鉴于上述问题,我们显然无法容忍企业环境中数据科学资产不受控制的增长。在大型企业中,项目与人力资源可能出现大量流失,例如,仅为特定项目短期雇佣具备特定技能的外部咨询人员。通常,当有人退出项目时,其拥有的知识技能也会随之离去。因此,本质上,数据科学资产并不只是用各种编程语言编写且分布在各个位置和环境中的脚本的集合。由于许多数据科学资产都是在非协作环境下开发的,因此这些资产的可复用性往往是有限的。临时性的文档记录、代码质量差、技术混用且过于复杂以及普遍缺乏专业知识是导致此类问题的主要推动因素。解决这些问题后,资产就会变为可复用并且其价值显著增加。例如,如果未经协调,每位数据科学家都可能针对同一数据源重新创建 ETL(抽取 (Extract) - 变换 (Transform) - 装入 (Load))、数据质量评估和特征工程管道,从而显著增加开销并降低质量。
缺乏协作
数据科学家都是伟大的思想家。常识告诉他们,脑容量是不变的。因此,数据科学家倾向于以自己的方式和步调独立工作。当他们遇到棘手的难题时,像“stackexchange.com”这样的 Web 站点就可能成为他们获得帮助的最佳资源。也许是因为不知情或者只是缺少具有同等技能的伙伴,但技术最好的数据科学家往往不擅长协作。从局外人的角度来看,因为他们秉着“哪管死后洪水滔天”的心态,所以没有采用可复用的方式来共享和组织所创建的资产。文档记录欠佳,甚至没有文档记录,而且组件分散,这些都导致难以回溯和复制以前的工作。因此,需要提供一个公共资产存储库并制定最低的文档记录准则。
次优架构决策
数据科学家通常是具备线性代数技能和一定程度的业务理解能力的“黑客”。他们通常不是经过培训的软件工程师或架构设计师。如上所述,数据科学家倾向于使用他们最熟悉的编程语言和框架,并快速构建解决方案,而未必会考虑可扩展性、可维护性和人力资源可用性等非功能性需求 (Non-functional requirement, NFR)。因此,我要强调一点,在每个重大数据科学项目中都应设立解决方案架构设计师或首席数据科学家角色,从而确保适当满足 NFR。预定义的架构和流程框架非常适合为此类角色提供支持。但首先,我们来了解一下传统企业架构如何适用于数据科学项目。
怎样的架构和流程才适用于数据科学项目
在回答这个问题之前,我们首先来简单回顾一下传统企业架构,然后评估怎样的架构方法和流程模型才适用于此类架构。
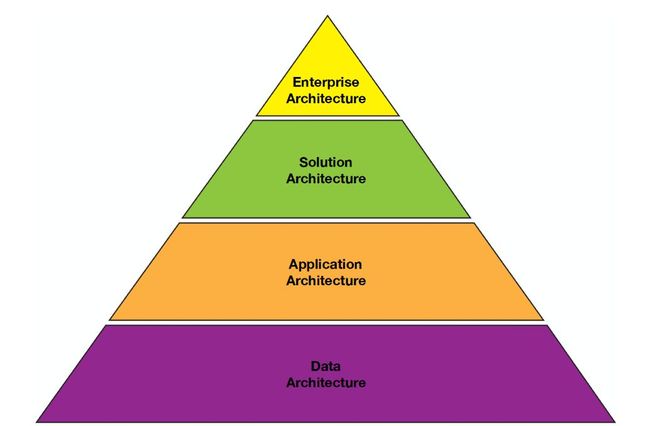
架构层次结构。来源:IBM 公司
站在金字塔顶端的是企业架构设计师。企业架构设计师负责定义在整个企业内行之有效的标准和准则。示例包括:
只要拥有许可证,就可以使用开源软件
REST 调用始终需要使用 HTTPS
使用非关系数据库需要获得来自企业架构委员会的特别核准
解决方案架构设计师在企业架构设计师定义的框架内开展工作。该角色负责定义适用于项目或用例的技术组件。示例包括:
必须在 Db2 关系数据库管理系统 (Relational database management system, RDBMS) 中存储历史数据
对于实时构造的高吞吐量数据,必须使用 Apache Spark Streaming
对于低延迟的实时视频流处理,必须使用 IBM Steams
然后,应用程序架构设计师负责在解决方案架构设计师的框架内定义应用程序。示例包括:
使用“模型 - 视图 - 控制器”(Model-View-Controller, MVC) 模式实施 UI
对于标准实体,将使用对象关系映射器
对于复杂查询,将使用准备好的 SQL 语句
最后,数据架构设计师负责定义数据相关组件,如:
在 ETL 期间,必须取消对数据的规范化以构成星型模型
在 ETL 期间,必须对所有分类字段和有序字段建立索引
那么在此过程中,富有创造力的全能数据科学家如何一展身手呢?首先,我们尝试定义在以上定义的角色中,数据科学家能部分承担其中哪些角色以及能够与其中哪些角色进行交互。
让我们再来从上到下审视一下这些角色。为了更直观地进行说明,我们以城市设计作比喻。企业架构设计师相当于设计整个城市的人。例如,他们负责定义污水处理系统和道路。解决方案架构设计师相当于每栋房屋的设计人,应用程序架构设计师相当于厨房的设计人,数据架构设计师负责监督电路安装和供水系统。
最后,数据科学家负责打造有史以来最先进的厨房!他们不会采用任何现有的厨房设计。他们会利用个别的现成组件,但也会根据需要创建原创部件。数据科学家与应用程序架构设计师的交互最为频繁。如果对厨房有特殊要求,那么数据架构设计师可能需要提供基础架构。记住这个比喻后,我们再来看一下,如果厨房由数据科学家独立打造,它会变成什么样?它将成为一个功能齐全的厨房,具有很多功能,但很可能欠缺适用性。例如,要启动烤箱,您需要登录到 Raspberry Pi 并运行一个 Shell 脚本。由于各个部件来自不同的供应商(包括某些定制硬件),因此厨房的设计可能并不美观。最后,它虽然提供了大量的功能,但其中有些功能并不必要,而且大部分功能都没有相应的文档记录。
再次从 IT 角度来看,此示例展示了原先问题的答案。在此过程中,富有创造力的全能数据科学家将如何一展身手呢?
数据科学家很少与企业架构设计师进行交互。他们可能会与解决方案架构设计师进行交互,但必然会与应用程序架构设计师和数据架构设计师紧密合作。他们不需要承担对方的角色,但必须能够从对方的角度来理解对方的想法。由于数据科学是一个新兴的创新领域,因此数据科学家必须与架构设计师从同样的角度(应用程序开发者或数据库管理员则不必如此)来思考问题,才能转变和影响企业架构。
我将使用一个示例来说明这其中的含义,以此作为本文的总结。考虑如下架构准则:采用 R-Studio Server 作为企业中的标准数据科学平台,所有数据科学项目都必须使用 R。此软件已经过企业架构设计师核准,内部部署的 R-Studio Server 自助服务门户网站是由解决方案架构设计师设计的。数据科学家使用可显著提升模型性能的 TensorFlow 后端来查找用 Python 编写的 Keras 代码片段。此代码为开源代码,由人工智能领域最智慧的大师之一负责维护。数据科学家只需一小时即可将此代码片段注入其笔记本上运行的数据处理管道(没错,他们就是在笔记本上建立原型的,因为他们真的不喜欢所提供的 R-Studio Server 安装)。那么,您认为这样做之后会发生什么呢?
在以往企业架构设计师全知全能的时代,数据科学家可能被迫将代码移植到 R 上(使用不太复杂的深度学习框架)。但这其中存在一种可能性。数据科学家应该能够在需要时使用此代码片段。但如果在没有任何指导的情况下这样做,那么可能导致数据科学领域成为一片荒芜之地。
商务合作 / 技术交流
请在公众号菜单栏获取联系方式

 好看你就点点我
好看你就点点我